







1.摘要
LLM在使用过程中往往难以进行复杂的推理,并且在知识可追溯性、及时性和准确性至关重要的场景中表现出较差的性能。为了解决这些局限性,该文章提出了Think on Graph(ToG),该框架利用知识图来增强LLM的推理深度和负责任推理能力(即推理过程不是黑盒)。通过使用ToG,我们可以识别与给定问题相关的实体,并进行探索和推理,从外部知识数据库中检索相关的三元组。这个迭代过程生成由顺序连接的三元组组成的多个推理路径,直到收集到足够的信息来回答问题或达到最大深度。通过对复杂多跳推理问答任务的实验,我们证明了ToG优于现有方法,有效地解决了LLM的上述局限性,而**不会产生额外的训练成本。
2.Intro
2.1 LLM现有的问题
尽管大型语言模型(LLM)在各种任务中都取得了显著的成功,但在面对需要深度和负责任的推理的复杂知识推理任务时,LLM 有很大的局限:
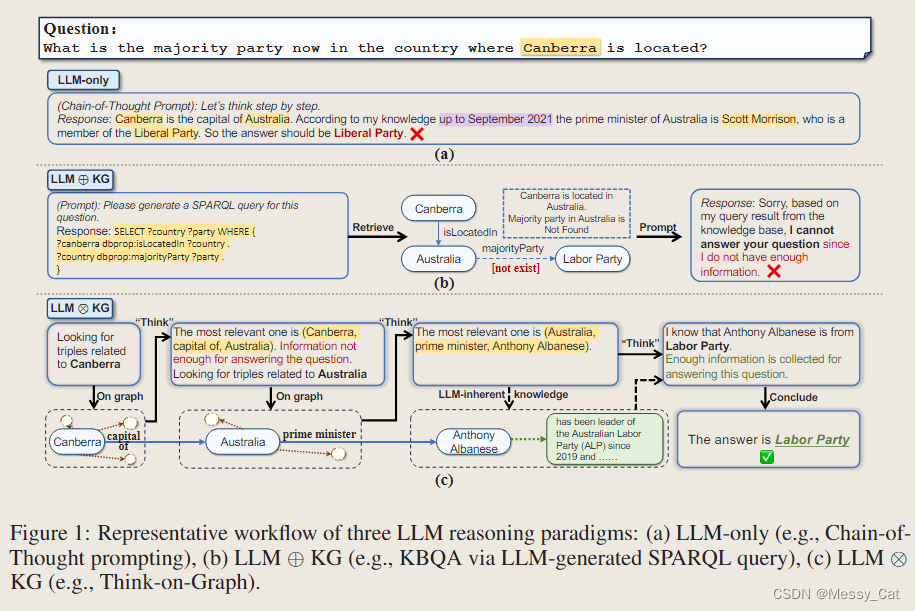
- LLM通常无法准确回答需要预训练阶段以外的专业知识的问题(例如图1(a)中的过时知识),或需要长逻辑链和多跳知识推理的问题;
- LLM缺乏责任感、可解释性和透明度,这增加了用户对“幻觉生成”和“有害文本”风险的担忧;
- LLM的训练过程通常既昂贵又耗时,这使得它们很难保持最新的知识。
现有解决方案是结合外部知识,例如知识图谱 (KG),以帮助改进 LLM 推理。KG 提供结构化的、显式和可编辑的知识表示,提出了一种补充策略来减轻 LLM 的局限性。
2.2 “LLM ⊕ KG”范式的问题
探索使用 KG 作为外部知识源来减轻 LLM 中的幻觉。这些方法遵循例程:从 KG 中检索信息,相应地增加提示,并将增加的提示馈送到 LLM(如图 1b 所示)。在本文中,我们将此范式称为“LLM ⊕ KG”,即KGs作为类似搜索引擎的作用,仅提供内容而不参与与LLM的推理过程。在这种范式中,LLM扮演翻译器的角色,它将输入问题转移到机器可理解的命令中进行KG搜索和推理,但它不直接参与图推理过程。松散耦合LLM⊕KG范式有自己的局限性,其成功在很大程度上取决于KG的完整性和高质量。例如,在上图 中,虽然 LLM 成功地识别了回答问题所需的必要关系类型,但关系“majority Party”的缺失导致检索正确答案失败。
2.3 LLM⊗KG范式(Think on Graph,ToG)
在该范式中KGs和LLM协同工作,在图推理的每个步骤中相互补充彼此的能力。使用 KG/LLM 推理中的Beam Search算法,ToG 允许 LLM 动态探索 KG 中的许多推理路径并相应地做出决策。给定一个输入问题,ToG 首先识别初始实体,然后通过探索(通过“On gragh”步骤查看 KG 中的相关三元组)和推理(通过“Think”步骤决定最相关的RDF三元组)迭代地调用 LLM 从 KG 中检索相关三元组,直到足够的信息,通过Beam Search中的前 N 个推理路径收集以回答问题(由 LLM 在“Think”步骤中判断)或达到预定义的最大搜索深度。
3.Methods
ToG要求LLM迭代地探索KGs上的多个可能的推理路径,直到LLM确定问题可以根据当前的推理路径回答。ToG 不断更新并保持前 N 条推理路径 P = {p1, p2,., pN } 用于每次迭代后问题 x,其中 N 表示Beam Search的宽度。
3.1 初始化
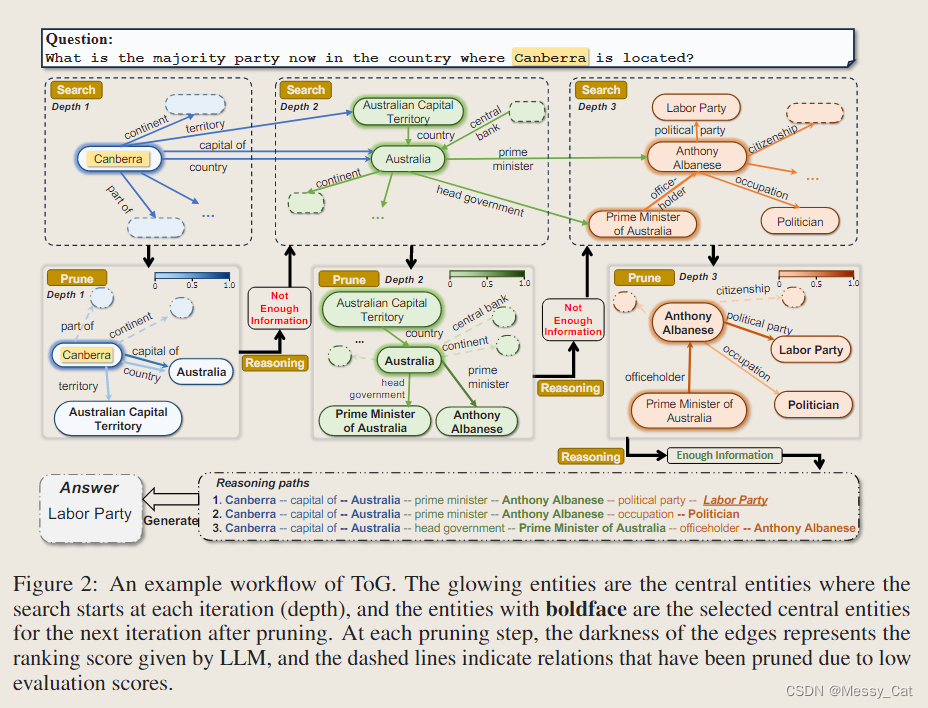
给定一个问题“What is the majority party now in the country where **Canberra** is located”,ToG 利用底层 LLM 来定位知识图谱上推理路径的初始实体。这个阶段可以看作是前 N 个推理路径 P 的初始化。ToG 首先提示 LLM 自动提取问题中的主题实体,得到top - N 个主题实体 E0 = {e0 1, e0 2, ..., e0N } *(此处的0都是上标,表示实体序数)*到问题。请注意,主题实体的数量可能少于 N。
3.2 搜索
在第 D 次迭代开始时,每条路径 pn 由 D-1 个三元组组成,即 pn ={(ed s,n, rd j,n, ed o,n)}D−1d=1 ,其中 ed s,n 和 ed o,n 表示主语和宾语实体,rd j,n 是它们之间的特定关系,(ed s,n, rd j,n, ed o,n) 和 (ed+1s,n , rd+1j,n , ed+1o,n ) 相互连接。P 中的前一次迭代的实体集和关系集分别表示为 ED−1 = {eD−1 1 , eD−1 2 。…, eD−1N } 和 RD−1 = {rD−1 1 , rD−1 2 ,…, rD−1N }。

3.2.1 关系搜索
关系探索是一个Beam Search过程,深度为 1,宽度为 N(进行一次,产生N或小于N个实体),从 ED-1 到 RD。整个过程可以分解为两个步骤:Search 和 Prune。LLM 作为代理自动完成此过程。
- 搜索
在第 D 次迭代开始时,关系探索阶段首先搜索与每个推理路径 pn 的尾部实体 eD−1n 相关联的关系 RD cand,n。这些关系被聚合到 RD 罐中。在图 2 的情况下,E1 = {Canberra} 和 R1cand 表示与 Camberra 向内或向外相关的所有关系的集合。值得注意的是,搜索过程可以通过执行附录 E.1 和 E.2 中显示的两个简单的预定义形式查询轻松完成,这使得 ToG 在没有任何训练成本的情况下很好地适应不同的 KG。 - 剪枝
我们获得了候选关系集 RD cand 和扩展的候选推理路径 Pcand 从关系搜索中,我们可以利用 LLM 从 Pcand 中选择以尾部关系 RD 结尾的新前 N 个推理路径 P,基于问题 x 的文字信息和候选关系 RD 可以。这里使用的提示可以在附录E.3.1中找到。如图2所示,LLM在第一次迭代中从链接到实体Canberra的所有关系中选择前3个关系{资本、国家、领土}。由于堪培拉是唯一主题实体,前 3 条候选推理路径更新为 {(Canberra, capital of),(Canberra, country),(Canberra, 领土)}。
3.2.2 实体搜索
公式太多,放图摆烂。

3.3 推理
在通过探索过程获得当前推理路径
后,我们提示LLM评估当前推理路径P是否足以生成答案。如果评估结果为肯定,我们将提示LLM使用推理路径生成答案,并将查询作为输入,如图2所示。相反,如果评估结果为阴性,我们重复探索和推理步骤,直到评估结果为阳性或达到最大搜索深度Dmax。如果算法尚未结束,则表明即使达到
,ToG仍然无法探索解决问题的推理路径。在这种情况下,ToG仅基于LLM中的固有知识生成答案。ToG的整个推理过程包括 D个探索阶段和 D个评估步骤以及一个生成步骤,该生成步骤最多需要对LLM进行 2ND + D + 1 次调用。
- 部分内容
How do different prompt designs affect ToG?
我们执行额外的实验来确定哪种类型的提示表示可以很好地用于我们的方法。结果如表 4 所示。 “Triples”表示使用三重格式作为提示来表示多条路径,例如“(Canberra, capital of, Australia), (Australia, Prime 部长, Anthony Albanese)”。“序列”是指使用序列格式,如图 2 所示。 “句子”涉及将三元组转换为自然语言句子。例如,“(Canberra, capital of, Australia)”可以转化为“堪培拉的首都是澳大利亚的”。结果表明,利用基于三元组的表示对推理路径产生最高程度的效率和优越的性能。相反,在考虑 ToG-R 时,每个推理路径都是一个从主题实体开始的关系链,使其与基于三元组的提示表示不兼容。因此,将 ToG-R 转换为自然语言形式会导致提示过长,从而导致性能显着下降。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









