







HIVE3 深度剖析 (上篇)
大家好,我是明哥!
HIVE3 相对于HIVE2,差异还是很大的,为方便大家了解这些差异点以更有效地使用HIVE,接下来我会通过几篇文章,重点剖析下这些差异点。
整个系列分为上下两篇文章,涵盖以下章节:
- 从 HIVE 架构的演进看 HIVE 的发展趋势
- 盘点下 HIVE3.X 和 HIVE2.X 的那些重大差异点
- HIVE3.X 的 ORC 事务表详解
- HIVE3.X 的 LEGACY 传统模式详解
- 周边生态如 SPARK/DATAX 如何对接HIVE 3x
- 大数据应用对接 HIVE3.x 的几点建议
本片文章是上篇,包含前三个章节,希望大家喜欢。
1. 从 HIVE 架构的演进看 HIVE 的发展趋势
早期的 HIVE,按照 METASTORE SERVICE/DB 所处的位置,经常会提到三种模式:内嵌模式,本地模式,远程模式:
- 内嵌模式:客户端和服务端还有底层存储元数据的数据库是同一个进程(使用的是derby这种jvm嵌入式数据库),是一体的(即不区分客户端和服务端);
- 本地模式:在内嵌模式的基础上,把存储元数据的数据库拆分了出来,但客户端和服务端还是同一个进程,是一体的(即不区分客户端和服务端);
- 远程模式:在本地模式的基础上,把元数据服务 hms 也拆分出来作为一个单独的进程,有了真正意义上的客户端和服务端,从 HIVE1.X 开始,所有生产环境推荐使用的都是 remote metastore 模式;
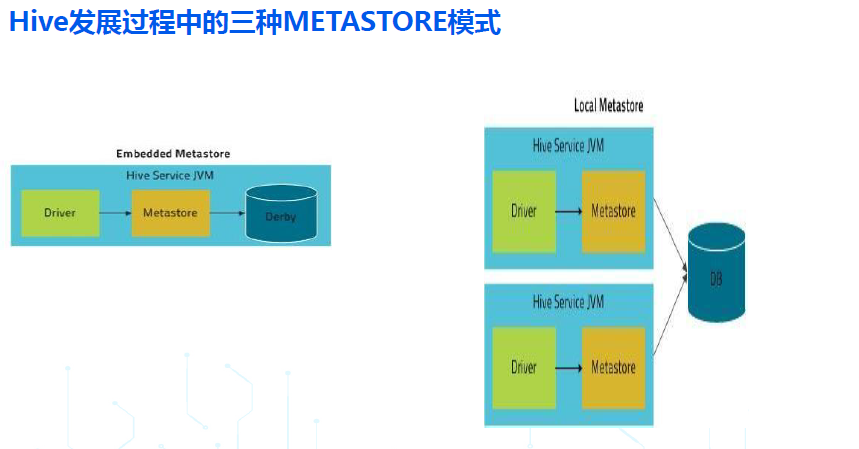
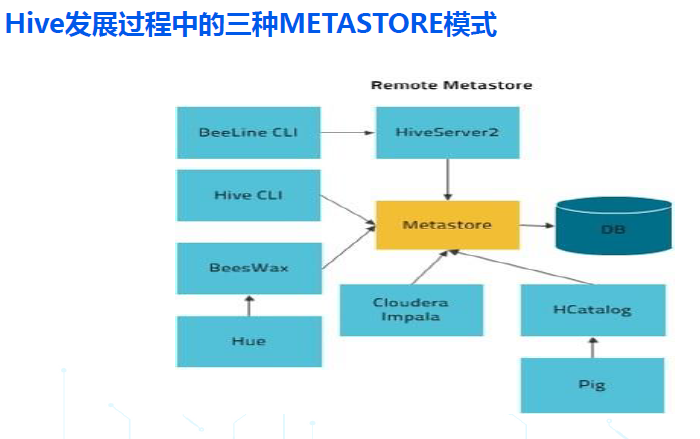
我们重点看下从 HIVE1.X 开始,生产环境使用的 远程模式:
- 远程模式,在服务端,包括一个或多个查询引擎 HiveServer2 和一个元数据引擎 HMS (Hive Metastore Service);
- 远程模式,从客户端使用方式来看,在 hive1.x 和 hive2.x 中又可以进一步分为两种方式:hive cli 的胖客户端模式,和 beeline 的瘦客户端模式;
- Hive cli 的胖客户端模式,客户端承载了 hiveserver2 的查询引擎角色,只需要访问服务端的元数据服务 hms 即可;
- Beeline 的瘦客户端模式,客户端需要访问服务端的 hiveserver2 ,并通过 hiveserver2 访问底层的 hms;
- 从 hive3.x 开始,hive 不再支持 cli 胖客户端模式, 仅仅支持 beeline 瘦客户端模式;
- 目前HIVE远程模式,完整的架构图如下:
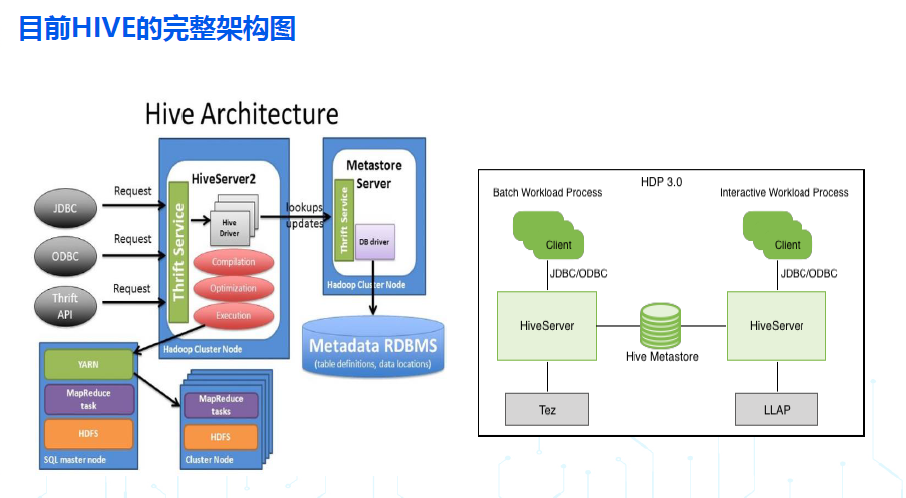
从上述HIVE 架构的演进,可以看到 HIVE 如下发展趋势:
- HIVE 将客户端与服务端分离,并在服务端进一步按照功能拆分出 hiveserver2 和 hms 两个服务,就可以应对多个客户端的并发访问,也能够适配大数据生态的其它计算引擎,如 spark/impala/presto/flink;
- 为了提高数据质量,也为了提高数据查询和分析的效率 Hive 社区还孵化出了列式存储 orc ,目前 Orc 已经是 apache 顶级项目;
- HIVE 进一步补强优化了 hiveserver2 服务端,通过 ORC 事务表提供了对增删改查的完善的 ACID 语义的支持,也通过 LL
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











