






大数据生态安全框架的实现原理与最佳实践(下篇)
前言
数字化转型大背景下,数据作为企业重要的战略资产,其安全的重要性不言而喻。
我们会通过系列文章,来看下大数据生态中安全框架的实现原理与最佳实践,系列文章一共两篇,包含以下章节:
-
大数据生态安全框架概述 -
HDFS 认证详解 -
HDFS 授权详解 -
HIVE 认证详解 -
HIVE 授权详解 -
金融行业大数据安全最佳实践
本片文章是下篇,包含上述后三个章节,希望大家喜欢。
1. HIVE 认证详解
-
HIVE 的认证方式,通过参数 hive.server2.authentication 在服务端进行统一配置; -
该参数可选的值主要有三种:hive.server2.authentication=none/kerberos/ldap -
HIVE的客户端,不管是 beeline 等专用 cli 客户端,还是 dbeaver 等通用 jdbc gui 客户端,抑或 JAVA 应用(基于jdbc),都需要根据服务端配置的认证方式,使用对应的方式,进行认证后才能成功连上 hiveserver2,进而提交查询命令。 -
视乎大数据集群中是否开启了 kerberos,实际的认证方式,分为以下四种: -
无认证模式 -
只开启LDAP认证模式 -
只开启Kerberos认证模式 -
开启Kerberos和LDAP双重认证模式
-
1.1 无认证模式:hive.server2.authentication = none
-
当不需要对用户身份进行校验,可以配置 hive.server2.authentication = none, 这种境况经常用在测试环境,生产环境一般不推荐; -
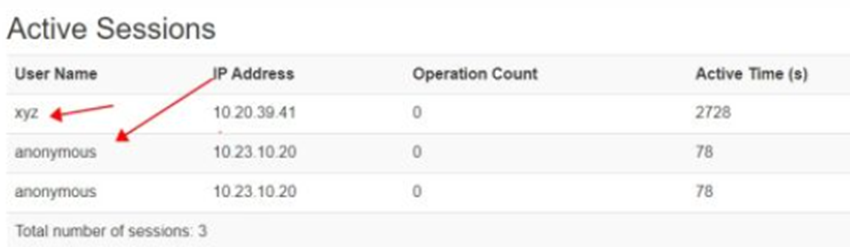
此时用户通过各种客户端如 cli/gui/java 登录时,可以不配置用户名和密码, 在服务端 Hive 会认为登录的是匿名用户 anonymous,(这点不同于 hdfs, 当没有开启kerberos安全时,如果没有配置 环境变量或系统参数 Hadoop_user_name,hdfs 的默认用户是提交作业的LINUX系统用户)如:beeline -u jdbc:hive2://xx.xx.xx.xx:10000/default -
此时用户通过各种客户端如 cli/gui/java 登录时,也可以配置为任意用户名和任意密码,在服务端 Hive 会认为登录的是用户声明的任意用户(用户名可以是任意用户名,甚至是不存在的用户名;密码可以是任意密码,或不配置密码),如:beeline -u jdbc:hive2://xx.xx.xx.xx:10000/default -n xyz;beeline -u jdbc:hive2://xx.xx.xx.xx:10000/default -n xyz -p xxxx -
可以通过 hiveserver2 webui,验证登录的用户身份;
1.2 只开启LDAP认证模式:hive.server2.authentication = ldap
-
中大型企业中一般都会有用户身份的统一认证平台,其底层一般都使用 ldap 协议,其具体实现有微软的 ActiveDirectory, 也有 openLdap, ApacheDS等开源实现; -
Hive 提供了基于 Ldap 的认证机制,可以使用企业的统一认证平台,来验证登录hive的用户的身份,其配置方式:hive.server2.authentication = ldap; -
具体的 ldap 工具的 url,需要通过参数指定:hive.server2.authentication.ldap.url; -
除了集成商业版的 ActiveDirectory,大数据集群中也可以使用独立安装的开源的ldap工具,此类工具常见的有 openLdap 和 ApacheDS,其中前者在大部分linux发行版中都自带了package安装包,更容易安装,不过主要通过命令行cli进行管理;而后者则自带了gui客户端 Apache Directory Studio,功能更为丰富;以 openLdap为例,其安装命令如下:sudo yum -y install openldap-clients; sudo yum -y install openldap; -
客户端登录 ldap 认证的 hiveserver2 时,需要提供用户名和密码,hiveserver2 会到ldap中验证用户名和密码,只有验证通过后才能正常登录; -
以 beeline 登录为例,其命令格式如下:beeline -u jdbc:hive2://xx.xx.xx.xx:10000/default -n ldapUserName -p ldapUserPwd;
1.3 HIVE 在 kerberos 环境下的认证
-
大数据生态中的各种存储系统,如HDFS/hive/hbase/zookeeper/kafka等,都支持开启Kerberos安全认证;
-
当大数据集群中的存储系统如HDFS/hive/hbase/zookeeper/kafka等开启了kerberos安全认证后,访问这些存储系统的客户端,包含各种计算引擎如 hive/hbase/spark/flink 的系统服务,和用户编写的各种应用如 spark/hive/flink等,都需要经过 kerberos kdc 的认证获得了 ticket 凭证后,才能与这些存储系统进行正常交互;
-
具体到 hiveserver2,其在跟开启了 kerberos 安全认证的 hdfs/yarn/hbase 等交互时,同样需要配置使用相应的 kerberos principal(一般配置为hive),且只有在经过 kdc 验证获得 ticket 后,才能与 hdfs/yarn/zk 进行交互,hive-site.xml中,相关配置项截图如下:
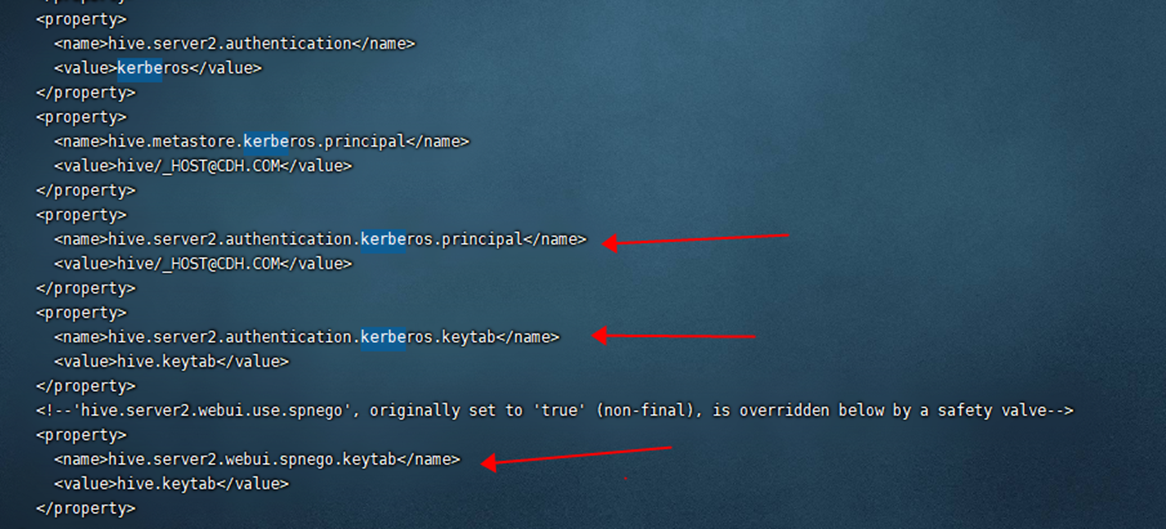
-
在开启了 kerberos 安全认证的大数据集群环境中,HIVE既可以配置使用 kerberos 认证机制,也可以配置使用 LDAP 认证机制:hive.server2.authentication = kerberos/ldap,分别对应上文所说的,只开启Keberos认证模式 和 开启Kerberos认证和LDA认证模式
1.4 只开启Kerberos认证模式:hive.server2.authentication = kerberos
-
配置hive.server2.authentication = kerberos,即要求 hiveserver2 的各种客户端如 cli/gui/java jdbc,只有在通过 kerberos 认证获得ticket 后,才能正常登陆 hiveserver2 进而提交 sql; -
由于是在kerberos环境下,所以客户端在登录前,需要首先从 kdc 获取 ticket 并维护在 ticket cache中: a valid Kerberos ticket in the ticket cache before connecting; -
如果是 cli/beeline 等客户端,一般会通过命令 kinit,基于手工输入的密码或keytab 文件,来获取特定业务用户的 ticket,并存储在客户端的 ticket cache中;(如果缓存的 ticket 过期了,需要重新获取); -
如果是程序代码,则一般通过 org.apache.hadoop.security.UserGroupInformation.loginUserFromKeytab(String user, String path) 的方式,基于keytab文件来获取特定业务用户的 ticket,并存储在客户端的 ticket cache中;(UserGroupInformation 在后台会自动基于keytab 文件来定时刷新ticket,确保不会过期); -
客户端在获取业务用户的 ticket 成功后,才可以通过 jdbc连接,登录到指定的 hiveserver2; -
客户端在获取业务用户的 ticket 成功后,通过 jdbc连接登录到指定的 hiveserver2时,需要特别注意下 hiveserver2 的url的格式,其格式推荐使用:jdbc:hive2://xx.xx.xx.xx:10000/default;principal=hive/_HOST@CDH.COM: -
这里的principal部分,推荐使用三段式来指定,包含pincipal, host 和 realm; -
pincipal 必须指定为系统用户hive,而不能是业务用户如 dap,xyz等(本质上是因为,hive-site.xml 中配置的hive系统用户是hive); -
host部分,推荐指定为_HOST,此时在底层使用时会替换为 hiveserver2 节点的hostname (当然也可以直接指定为 hiveserver2 节点的具体的 hostname); -
realm 部分,需要根据实际配置情况进行指定(可以查看配置文件 /etc/krb5.conf);
1.5 开启Kerberos和LDAP双重认证模式:hive.server2.authentication = ldap
-
配置hive.server2.authentication = ldap,即要求 hiveserver2 的各种客户端如 cli/gui/java jdbc,需要提供用户名和密码,且hiveserver2 会到ldap中验证用户名和密码,只有验证通过后,才能正常登陆 hiveserver2 进而提交 sql;(当然因为整个大数据环境开启了 kerberos, 所以在登录hiveserver2之前,一样要经过 kerberos kdc 的认证) -
由于是在kerberos环境下,所以客户端在登录前,需要首先从 kdc 获取 ticket 并维护在 ticket cache中,这一点跟 kerberos 环境下,hive 的 kerberos 认证方式时一直的:a valid Kerberos ticket in the ticket cache before connecting: -
如果是 cli/beeline 等客户端,一般会通过命令 kinit,基于手工输入的密码或keytab 文件,来获取特定业务用户的 ticket,并存储在客户端的 ticket cache中;(如果缓存的 ticket 过期了,需要重新获取); -
如果是程序代码,则一般通过 org.apache.hadoop.security.UserGroupInformation.loginUserFromKeytab(String user, String path) 的方式,基于keytab文件来获取特定业务用户的 ticket,并存储在客户端的 ticket cache中;(UserGroupInformation 在后台会自动基于keytab 文件来定时刷新ticket,确保不会过期); -
客户端在获取业务用户的 ticket 成功后,才可以通过 jdbc连接,登录到指定的 hiveserver2,此时登录格式,跟非 kerberos 环境下,hive 的 ldap认证方式,是一样的: -
此时需要提供用户名和密码,hiveserver2 会到ldap服务器中验证用户名和密码,只有验证通过后才能正常登录; -
以 beeline 登录为例,其命令格式如下:beeline -u jdbc:hive2://xx.xx.xx.xx:10000/default -n ldapUserName -p ldapUserPwd;
1.6 大数据平台 CDH/TDH/CDP 与 TDH 中,hive 认证方式的差异
-
客户端可用的登录方式,本质上取决于服务端的具体配置; -
在TDH环境下,在大数据集群开启了 kerberos 安全认证的环境下,如果 hive 服务端配置了使用ldap (hive.server2.authentication = ldap),则必须通过kerberos和ldap的双重认证后,才能登陆 hiveserver2; -
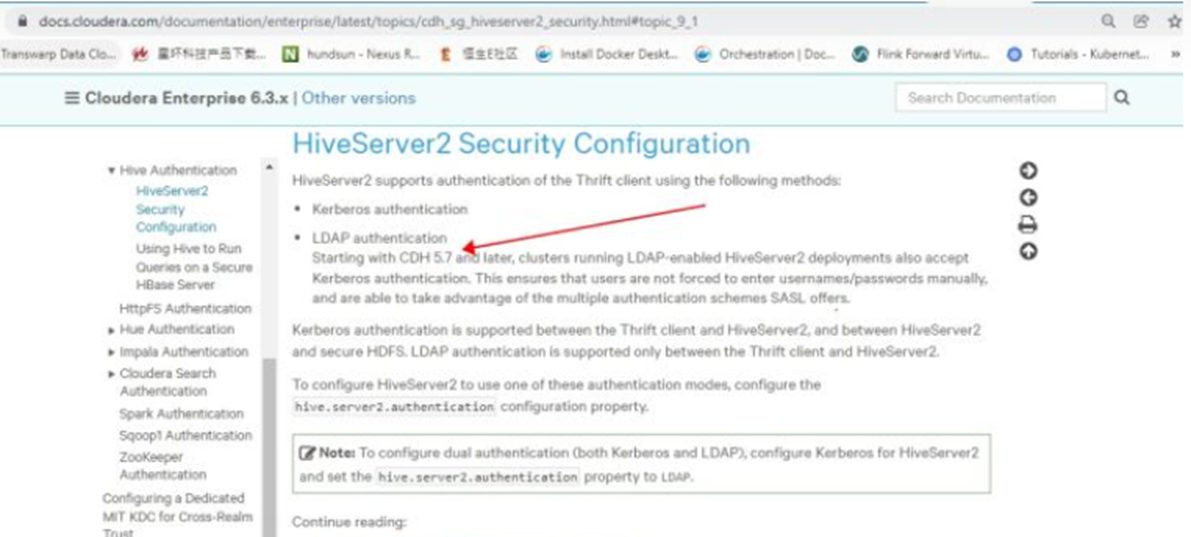
在 CDH/CDP环境下,在 CDH 5.7 及以后的版本中,Cloudera 对hive的安全认证进行了增强:在大数据集群开启了 kerberos 安全认证的环境下,即使 hive 服务端配置了使用ldap (hive.server2.authentication = ldap),客户端也可以通过url指定使用 KERBEROS 认证方式来登录;此时实际的业务用户,是登录前,通过kinit指定的业务用户!!!此时需要注意,url中需要指定principal=HIVE/_HOST@CDH.COM,以示默认的ldap认证方式下,实际使用的是kerberos认证方式!!!
-
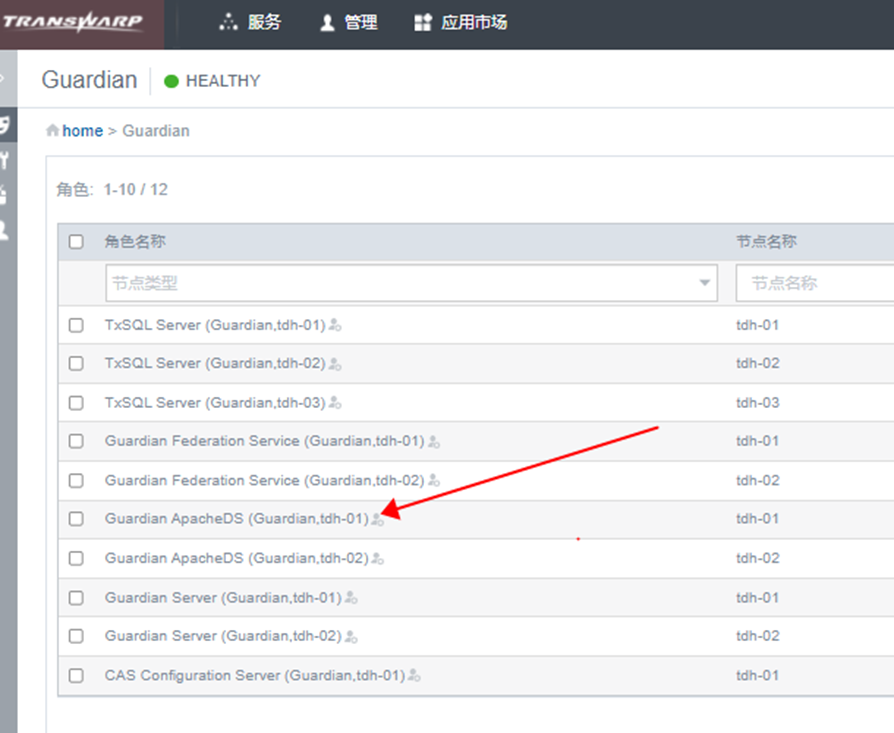
TDH 中,通过安全组件 Guardian 来管理各个组件的安全,Guardian 底层整合了 kerberos 和 ApacheDS; -
TDH中,同样支持以上四种认证方式,其推荐的hive认证方式,其实等同于 “kerberos环境下,hive 的 LDAP 认证方式 : hive.server2.authentication = ldap”; -
在TDH 中配置 inceptor 使用 “开启Kerberos认证和LDAP认证模式” ,并不需要额外安装 OpenLdap/ApacheDS/microsoft AD 等 ldap的具体实现,也不需要跟企业内部统一的 LDAP 服务器打通,也不存在泄露企业域账号用户名和密码的风险,因为底层实际使用的是 Guardien 底层自带的一个 ldap实现(本质是ApacheDS),创建用户更改密码等操作都是在 Guardien 中操作的,跟企业域账户是独立的;
1.7 HIVE认证相关参数
hive-site.xml中,认证相关参数主要有:
-
hive.server2.authentication -
hive.server2.authentication.kerberos.keytab -
hive.server2.authentication.kerberos.principal -
hive.server2.authentication.spnego.keytab -
hive.server2.authentication.spnego.principal -
hive.server2.authentication.ldap.url -
hive.server2.authentication.ldap.baseDN -
hive.server2.authentication.ldap.Domain -
hive.metastore.kerberos.keytab.file -
hive.metastore.kerberos.principal -
hive.server2.enable.doAs/hive.server2.enable.impersnation
2. HIVE 授权详解
先来回顾下 hive 的整体架构:
-
hive整体分为客户端和服务端两部分; -
客户端包括 hive cli, beeline,webui等; -
服务端又分为 hiveserver2 和 hms,以及底层的元数据持久存储 metastore db; -
Hive 又作为 hadoop的客户端,访问底层的 hdfs 和 yarn;
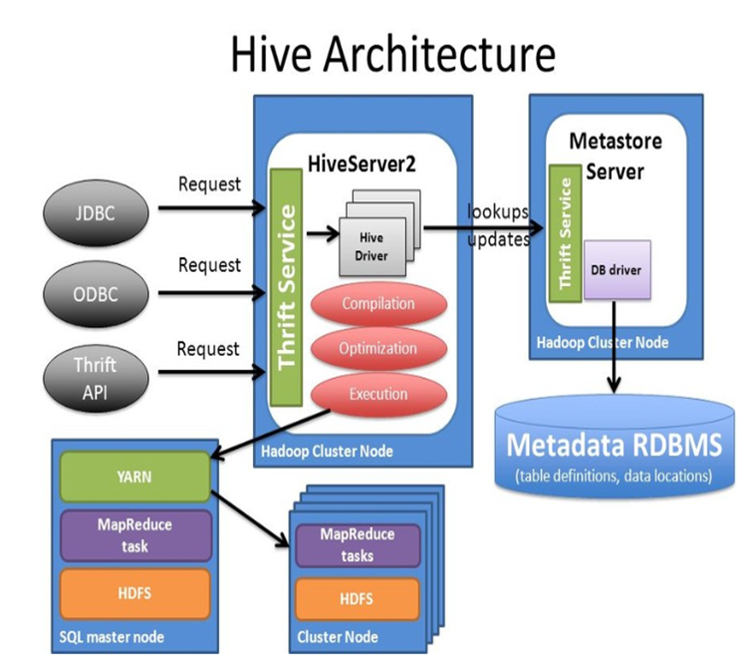
当前市面上HIVE的使用方式分两种:
-
只使用 HMS,将hive 看做是单独的 table format layer,比如 spark/flink on hive: Hive as a table storage layer: These users have direct access to HDFS and the metastore server (which provides an API for metadata access); -
完整地使用 hive, 包括 hiveserver2+ hms, 比如 hive on mr/tez/spark: Hive as a SQL query engine: These users have all data/metadata access happening through HiveServer2. They don't have direct access to HDFS or the metastore. -
第一种只使用 hms 的方式下,spark 等应用会直接访问 hdfs, 所以授权依赖于 hdfs 的 authentication 机制:HDFS access is authorized through the use of HDFS permissions. (Metadata access needs to be authorized using Hive configuration.) -
第二种使用 hiveserver2 的方式,用户通过 hiveserver2 进而访问 hms 和 hdfs/s3,hive 更容易统一管控用户权限,也更容易组织底层文件的layout和存储格式,比如支持 orc acid事务表,从而提供高效的数据服务,是Hive 社区期望的方式;
当前 HIVE 共有四种 authentication 认证机制:
-
Storage Based Authorization in the Metastore Server -
SQL Standards Based Authorization in HiveServer2 -
Authorization using Apache Ranger & Sentry -
Old default Hive Authorization (Legacy Mode)
之所以有这么多 authentication 机制,从根本上来说,还是因为 hive 历史发展的原因:
-
早期的 hive 仅仅是一个简单的存储引擎之上的SQL解析与执行层,对底层存储引擎中的数据没有完整的掌控力,允许外部应用如 spark/presto/flink 等,直接访问 hms获取元数据,并进而读写底层的数据(schema on read); -
后续hive 逐渐迭代,加强了对底层存储引擎中的数据的管控,包括文件的目录结构文件名称存储格式等,并进而支持了 orc acid 事务表等高效的数据存取格式,越来越像一款类似 mysql/oracle 等的数据库,推荐用户使用 hiveserver2 来访问底层数据; -
所以 hive 需要支持外部计算引擎直接使用 hms 与使用 hiveserver2两种方式,需要支持 orc acid 事务表,也需要支持其它格式的各种内部表和外部表;

2.1 HIVE授权详解-Old default Hive Authorization (Legacy Mode)
-
Hive Old Default Authorization 是 hive 2.0 之前默认的 authorization model, 支持类似 RDBMS 中对 user/group/roles 赋予 database/table 各种权限的机制:authorization based on users, groups and roles and granting them permissions to do operations on database or table -
但是 Hive Old Default Authorization 并不是一个完整的权限控制模型:leaving many security gaps unaddressed, for example, the permissions needed to grant privileges for a user are not defined, and any user can grant themselves access to a table or database. -
hive 2.0 之后默认的 authorization model 已经被切换为 SQL standards based authorization mode (HIVE-12429);

2.2 HIVE授权详解 - Storage Based Authorization in the Metastore Server
-
HMS 提供了对 hive metastore db 中的元数据的访问,为保护这些元数据被各种 hms 客户端如 spark/presto/flink 错误地访问和修改,HMS 不能完全依赖这些客户端自身的认证和授权等安全机制,为此 Hive 0.10 通过 HIVE-3705 增加了对 HMS 的 authorization 能力,即 Storage Based Authorization; -
Storage Based Authorization 底层依赖 hdfs permissions 作为 source of truth: it uses the file system permissions for folders corresponding to the different metadata objects as the source of truth for the authorization policy. -
Storage Based Authorization 提供了客户端直接访问 HMS 时,对底层元数据的保护:To control metadata access on the metadata objects such as Databases, Tables and Partitions, it checks if you have permission on corresponding directories on the file system; -
Storage Based Authorization 通过代理机制(hive.server2.enable.doAs =true),也可以提供对客户端通过 hiveserver2 访问HIVE数据时,对底层元数据和数据的保护:You can also protect access through HiveServer2 by ensuring that the queries run as the end user; -
Storage Based Authorization 可以通过 hdfs acl 提供权限的灵活性:Through the use of HDF ACL, you have a lot of flexibility in controlling access to the file system, which in turn provides more flexibility with Storage Based Authorization; 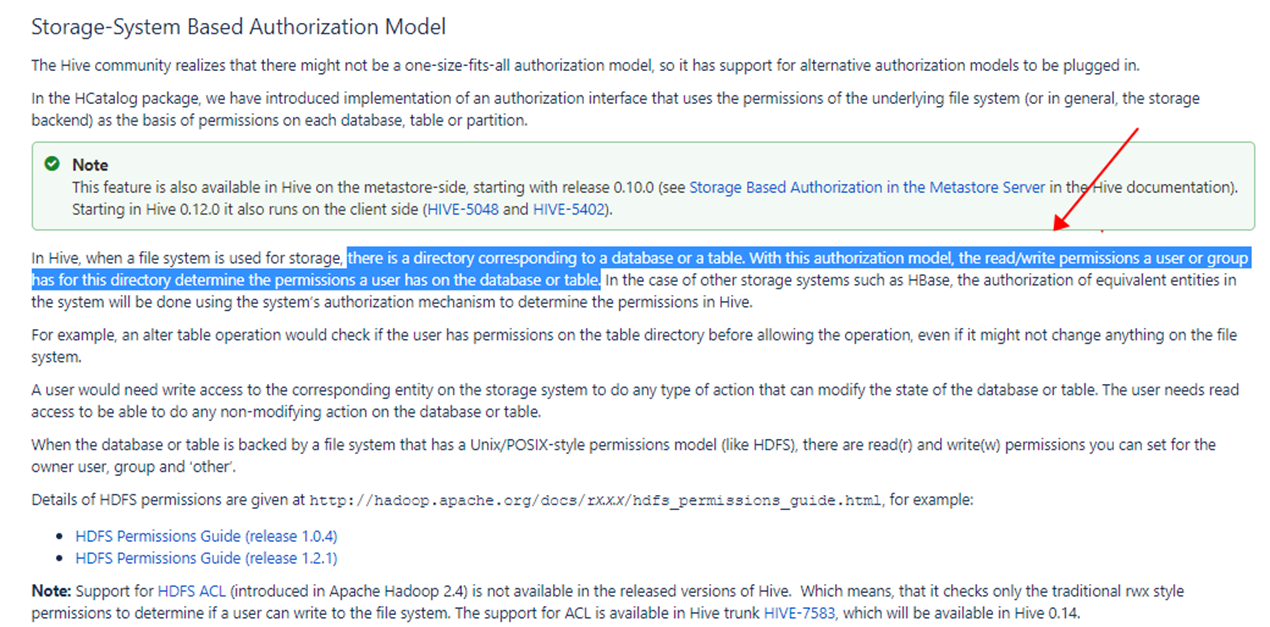
Storage based authorization 因为其自身的机制原理,在使用上也有其局限性:
-
由于Storage based authorization 的底层原理是依赖用户对底层存储系统中数据的访问权限,且该用户在hiveserver2开启代理与不开启代理机制下身份不同,所以其主要用来在用户直接访问 hms 时,提供对底层元数据的保护; -
对于用户使用 hiveserver2 的情况,需要限制 HiveServer2 中可以执行的操作,此时不能单纯依靠 Storage based authorization, 还需要配合 “SQL Standards Based Authorization” 或 “Authorization using Apache Ranger & Sentry,或者配置使用 FallbackHiveAuthorizer:

2.3 HIVE授权详解 - SQL Standards Based Authorization in HiveServer2
-
Storage Based Authorization 只能基于文件系统的目录/文件的权限管理机制提供database/table/partition 粒度的权限管控,为提供更细粒度的权限管控,比如行级别,列级别,视图级别的权限管控, Hive 0.13.0 通过 HIVE-5837 引入了SQL Standards Based Authorization; -
SQL Standards Based Authorization,其作用域是 HiveServer2,可以跟/需要跟 hms 的 storage based authorization 结合使用,以提供对HIVE元数据和数据的全面的安全管控; -
SQL Standards Based Authorization,会在 hiveserver2 解析编译用户的 sql query 语句时,校验提交该 sql query 语句的业务用户的权限, 但是在底层执行该 query 时,使用的是 Hive 系统用户,所以 hive 系统用户需要有对底层数据对应的目录/文件的访问权限; -
由于 SQL Standards Based Authorization 的作用域是 HiveServer2,所以对于直接访问底层hdfs数据的用户,比如 spark on hive/Hive CLI/hadoop jar命令等,需要依赖 hms 的 storage based authorization 来进行安全管控; -
SQL Standards Based Authorization,对 hiveserver2 中能提交的命令,做了限制; -
启用该 authorization 机制时,Dfs/add/delete/compile/reset 等命令时被禁用的; -
使用白名单机制,通过参数 hive.security.authorization.sqlstd.confwhitelist,限制了可以通过 set 覆盖哪些参数配置;
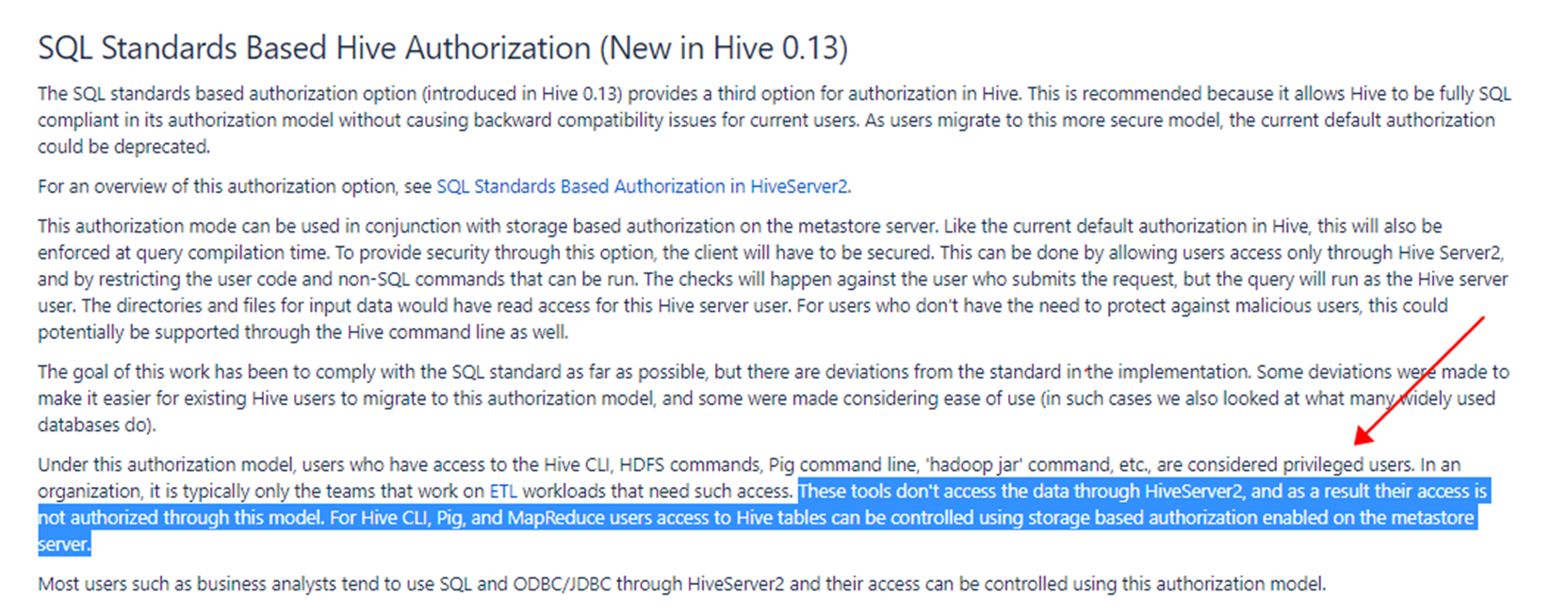
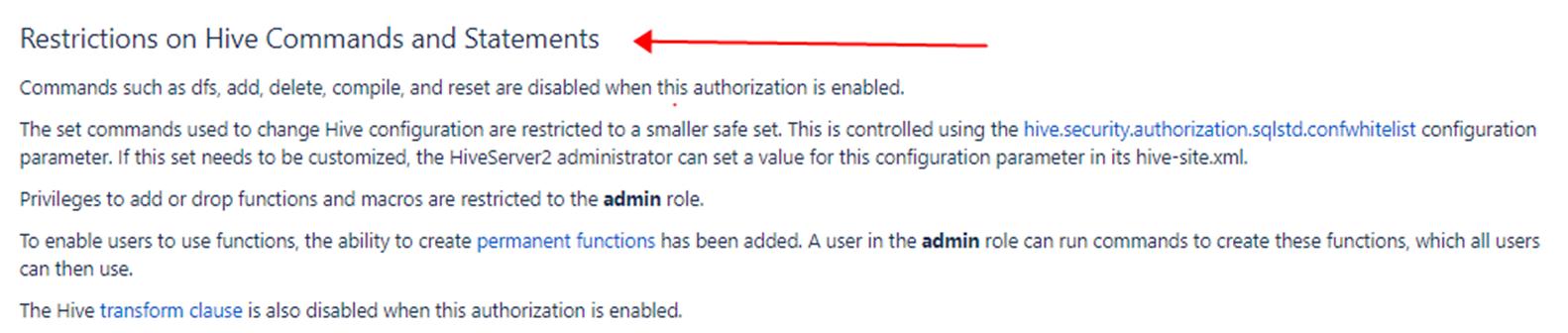
2.4 HIVE授权详解 - Authorization using Apache Ranger & Sentry
-
Apache Ranger 和 Apache Sentry 通过插件机制,提供了对 hive authorization的支持,Sentry和Ranger这两个框架非常类似,都是基于角色的访问控制模型(role-based access control,RBAC),基于角色的访问控制在需要对大量用户进行授权时能大大减轻所需的ACL配置工作; -
Sentry最初是由Cloudera公司内部开发而来的,初衷是为了让用户能够细粒度的控制Hadoop系统中的数据(主要指HDFS,Hive的数据),所以Sentry对HDFS,Hive以及同样由Cloudera开发的Impala有着很好的支持性; -
而Ranger最初是由另一家公司Hortonworks(已经被Cloudera收购)主导开发的,它同样是做细粒度的权限控制,但相比较于Sentry而言,ranger有着更加丰富的策略控制,以及更加通用性的大数据组件支持,包括于HDFS, Hive, HBase, Yarn, Storm, Knox, Kafka, Solr 和 NiFi等在Cloudera公司新推出的大数据平台cdp中,不在提供对sentry的支持而是统一使用了Ranger; -
CDH中默认使用的是 Sentry, HDP 中默认使用的是 Ranger, 由于 sentry 项目已经从 asf 中退役了,目前业界推荐的,CDP中默认的,都是 Ranger; -
Ranger 作为集中式平台,对 Hadoop 生态中的大多数组件,包括hdfs/hive/hbase/yarn/kafka等,综合提供了授权,密钥管理和审计功能; -
Ranger 采用了 ABAC 模型 (Attribute based access control),基于标签策略,根据分类(标记)控制对资源的访问; -
Ranger 提供了很多高级特性,如 web ui直观和细粒度的策略查看和管理,全面的可扩展的审核日志记录,动态的行和列级别的访问控制,动态数据掩码可实时保护敏感数据等。

2.5 HIVE授权详解-总结
-
HIVE的权限管控机制,最常用的是结合 Storage Based Authorization in the Metastore Server 和 SQL Standards Based Authorization in HiveServer2 或 sentry/ranger 插件; -
其中前者基于底层文件系统的权限管理机制,提供对 hms API 的权限管控,比如查看/新增/删除表或分区等; -
后者提供通过 hiveserver2 访问hive数据时,更细粒度的权限管控,比如行级别,列级别,视图级别的权限管控; -
当使用 spark/flink/presto on hive 方案时,应用会直接访问 hms 和 hdfs ,只有 Storage Based Authorization起作用,主要依赖的是 hdfs 的权限管控机制(posix mode + posix acl) -
当使用 hive on mr/tez/spark 方案时,应用通过 hiveserver2 访问 hms 和 hdfs, Storage Based Authorization 和 sentry/range 都起作用 (需要关闭代理功能 hive.server.enable.doAs=false); -
终端业务用户比如 xyz 提交给 HIVESERVER2 的 SQL作业,经过 HIVESERVER2 的解析编译和优化后,一般会生成 MR/TEZ/SPARK 任务(之所以说一般,是因为有的 SQL 是直接在HIVESERVER2中执行的,不会生成分布式的 MR/TEZ/SPARK 任务),这些 MR/TEZ/SPARK 任务最终访问底层的基础设施 HDFS 和 YARN 时,一样要经过这些基础设施 hdfs/yarn的权限校验; -
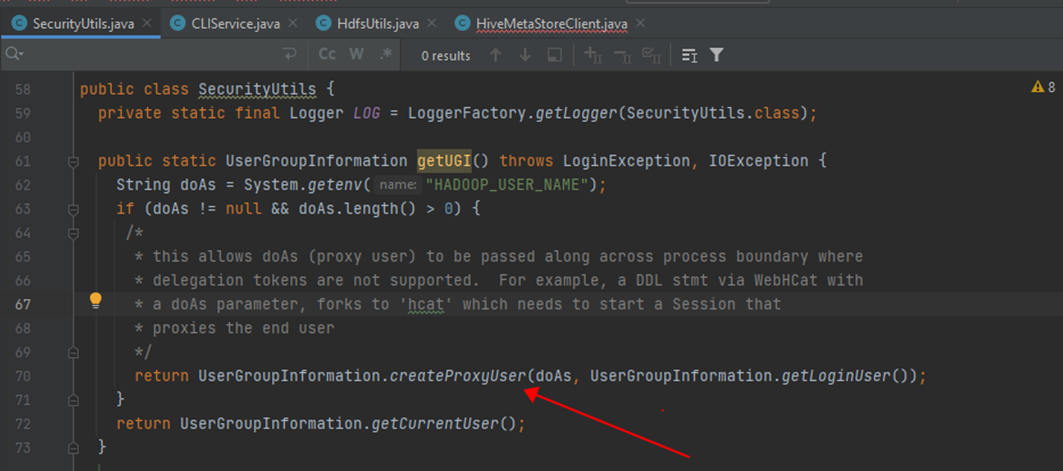
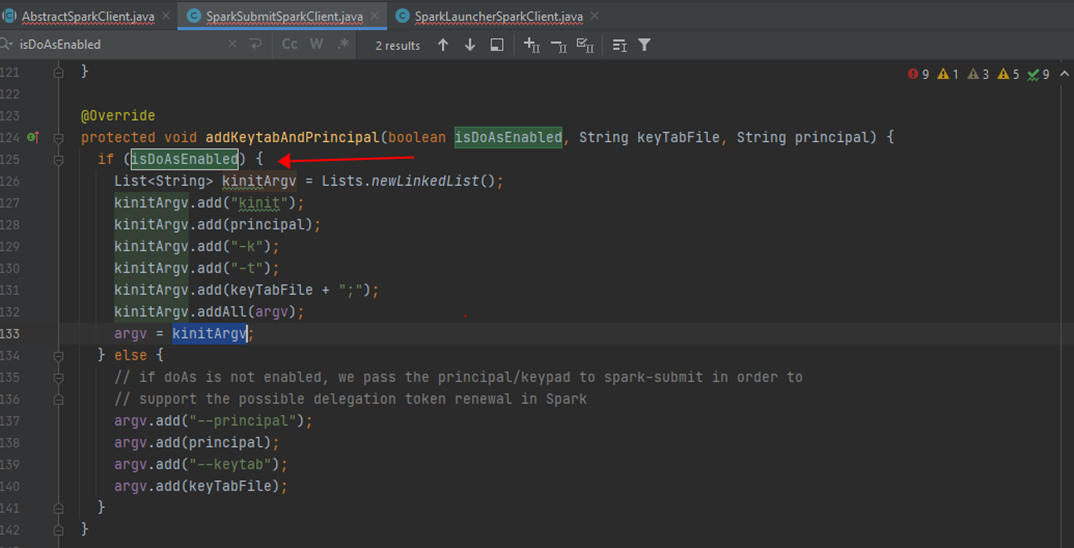
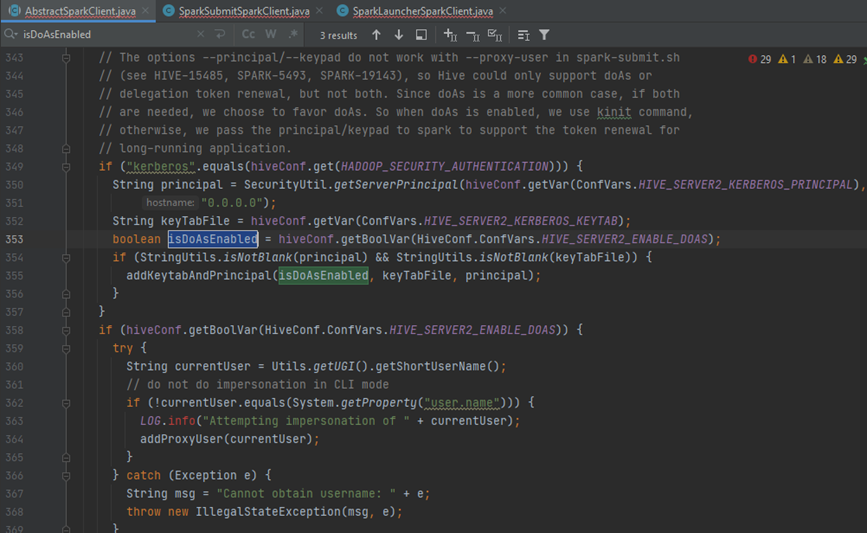
那么这些底层基础设施 hdfs/yarn 进行权限校验时,是针对 hive 系统用户进行校验(hiveserver2 这个服务的系统用户一般是linux操作系统上的用户 hive),还是针对终端业务用户比如 hundsun进行校验呢?这点可以通过参数 hive.server2.enable.doAs进行控制(老版本参数是hive.server2.enable.impersonation):hive.server2.enable.doAs=false/TRUE:“Setting this property to true will have HiveServer2 execute Hive operations as the user making the calls to it.”; -
当启用了 HIVE 的代理机制时(hive.server.enable.doAs=true),业务终端用户如 xyz 提交的 HIVE SQL 作业底层的 MR/TEZ/SPARK 任务访问 HDFS/YARN 时,HDFS/YARN 验证的是业务终端用户 xyz 的身份 (后续 HDFS/YARN 的权限校验,校验的也是 xyz 用户的权限); -
当没有启用 HIVE 的代理机制时(hive.server.enable.doAs=false),业务终端用户提交的 HIVE SQL 作业底层的 MR/TEZ/SPARK 任务访问 HDFS/YARN 时,需要验证的是 hiveserver2 服务对应的用户,即 hive 的身份 (后续 HDFS/YARN 的权限校验,校验的也是 hive 用户的权限);
2.6 HIVE授权详解-相关参数
HIVE授权相关参数主要有:
-
hive.security.authorization.enabled: Enable or disable the Hive client authorization -
hive.security.authorization.manager:org.apache.hadoop.hive.ql.security.authorization.plugin.fallback.FallbackHiveAuthorizerFactory/org.apache.hadoop.hive.ql.security.authorization.StorageBasedAuthorizationProvider/org.apache.hadoop.hive.ql.security.authorization.DefaultHiveMetastoreAuthorizationProvider/org.apache.sentry.binding.hive.authz.SentryHiveAuthorizerFactory; -
hive.metastore.pre.event.listeners: The pre-event listener classes to be loaded on the metastore side to run code whenever databases, tables, and partitions are created, altered, or dropped. Set this configuration property to org.apache.hadoop.hive.ql.security.authorization.AuthorizationPreEventListener in hive-site.xml to turn on Hive metastore-side security; -
hive.security.metastore.authorization.manager: This tells Hive which metastore-side authorization provider to use. Defaults to org.apache.hadoop.hive.ql.security.authorization.StorageBasedAuthorizationProvider . -
hive.security.metastore.authenticator.manager:The authenticator manager class name to be used in the metastore for authentication, defaults to org.apache.hadoop.hive.ql.security.HadoopDefaultMetastoreAuthenticator -
hive.security.authorization.createtable.owner.grants -
hive.security.authorization.sqlstd.confwhitelist -
hive.warehouse.subdir.inherit.perms -
hive.server2.enable.doAs/hive.server2.enable.impersnation
3. 金融行业大数据安全最佳实践
-
在金融行业强调安全的背景下,我们推荐对大数据集群开启kerberos 安全认证, 开启用户权限校验:hadoop.security.authentication=kerberos,dfs.permissions.enabled=true -
HDFS 文件的授权,要遵循最小化原则,不能对目标目录笼统设置777! -
HDFS文件的授权,建议主要使用 POSIX MODE 来进行设置,必要时通过 POSIX ACL 进行补充:dfs.namenode.acls.enabled=true -
业务用户对HDFS文件的使用,建议将所有文件,比如 jar/配置文件/数据字典等,存放在统一的目录下,比如/user/hundsun/dap -
针对HIVE的认证,我们推荐两种方式:只开启Kerberos认证模式/开启Kerberos认证和LDAP认证模式,其中后者的实际含义是“大数据集群(hdfs/yarn/zookeeper/hive等)开启了kerberos安全认证,同时 hive 组件 配置了使用 LDAP认证”; -
具体的LDAP,如果要跟企业域账户打通,则需要使用企业内部统一的 LDAP 服务器;否则建议使用一个单独的 ldap 服务器(比如 OpenLdap/ApacheDS/microsoft AD 等 ldap的某个具体实现),比如在 TDH中,底层实际使用的是 Guardien 底层自带的一个 ldap实现(本质是ApacheDS),创建用户更改密码等操作都是在 Guardien 中操作的,更企业域账户是独立的; -
针对HIVE的授权,我们推荐使用 sentry/ranger等第三方插件统一进行授权和鉴权,此时需要关闭hive的代理功能 Hive.server2.enableDoas=false; -
我们推荐各个业务系统使用该系统对应的业务用户的身份提交业务SQL,而不是各个业务系统统一都使用 HIVE 系统用户; -
业务用户对HIVE表的使用,如果都是通过HIVESERVER2来访问,建议使用 ORC 事务内表;如果通过 SPARK 等计算引擎做 ETL,建议使用 orc/parquet格式的HIVE外表,并存放在统一的目录下,比如/user/hundsun/dap,针对外表目录的授权,需要结合 HDFS POSIX ACL 来进行;
!关注不迷路~ 各种福利、资源定期分享!欢迎小伙伴们扫码添加明哥微信,后台加群交流学习。

本文由 mdnice 多平台发布
















 945
945











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











