







文章目录
- 前言
- 参考目录
- 学习笔记
- 0:符号表(ST)实现小结
- 1:哈希函数
- 1.1:计算哈希函数
- 1.2:Java中的哈希码规范
- 1.2.1:哈希码实现:integers、booleans、doubles
- 1.2.2:哈希码实现:strings
- 1.2.3:哈希码实现:用户自定义类型
- 1.3:哈希码设计
- 1.4:模块化哈希
- 1.5:均匀哈希假设
- 2:分离链接 / 独立链表 Separate Chaining
- 2.1:哈希碰撞(哈希冲突)
- 2.2:分离链接 ST
- 2.3:Java 实现:查找、插入
- 2.4:分离链接分析
- 2.5:(补充)Java 实现:调整大小
- 2.6:(补充)Java 实现:删除
- 2.7:ST 实现小结
- 3:线性探测 Linear Probing
- 3.1:碰撞解决方案:开放式寻址
- 3.2:demo 演示:插入
- 3.3:demo 演示:搜索
- 3.4:线性探测小结
- 3.5:Java 实现:查找、插入
- 3.6:键簇
- 3.7:停车问题
- 3.8:线性探测分析
- 3.9:(补充)Java 实现:调整大小
- 3.10:(补充)Java 实现:删除
- 3.11:ST 实现小结
- 4:哈希背景
- 4.1 哈希算法变体
- 4.2 哈希表 vs 平衡查找树
前言
说起来挺丢脸的哈哈哈,在打开这一章之前,或者说是打开这一章节视频(官网)之前,我不知道 散列表 居然就是 Hash Tables,也就是每一个会敲代码的人应该都用过的哈希表(属实是汗流浃背了朋友们)。所以我特意在本篇的标题后面打了个括号:(Hash Tables)。
继续批评一下自己,说明基础太薄弱了,还得继续学习。不过说实话散列表说起来确实是不太习惯,所以 在本篇中还是尽量使用哈希来代替中文翻译的散列。
Ok,回到正题,本篇的主要内容包括:哈希函数、分离链接(Separate Chaining,这个书里面中文翻译成 拉链法)、线性探测 以及一点点关于哈希的 背景(context) 介绍。
参考目录
- B站 普林斯顿大学《Algorithms》视频课
(请自行搜索。主要以该视频课顺序来进行笔记整理,课程讲述的教授本人是该书原版作者之一 Robert Sedgewick。) - 微信读书《算法(第4版)》
(本文主要内容来自《3.4 散列表》) - 官方网站
(有书本配套的内容以及代码)
学习笔记
注1:下面引用内容如无注明出处,均是书中摘录。
注2:所有 demo 演示均为视频 PPT demo 截图。
注3:如果 PPT 截图中没有翻译,基本会在下面进行汉化翻译(除非很简单一眼懂就不翻译了),因为内容比较多,本文不再一一说明。
开篇的时候,Prof. Sedgewick 是这样介绍哈希表的:
Which is another approach to implementing symbol tables that can also be very effective in a practical applications.
这是实现符号表的另一种方法,在实际应用中也非常有效。
0:符号表(ST)实现小结
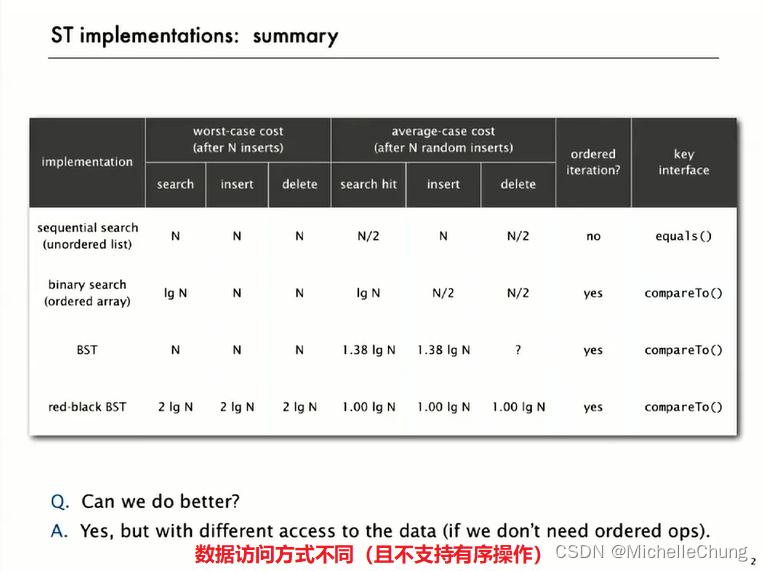
哈希表的简单引出:

将项目存储在 键索引表 中(索引是基于键的一个函数)。
哈希函数。用于从键计算数组索引的方法。
涉及的问题:
- 计算哈希函数(设计并实现一个有效的哈希函数以将键转化为数组索引。)
- 等价性测试:一种方法用于检查两个键是否相等。
- 冲突解决:当两个键通过哈希函数映射到同一个数组索引时,所采用的算法和数据结构来处理这种冲突。
经典的空间-时间权衡:
- 无空间限制情况:可以使用简单的哈希函数,直接将键作为数组索引。
- 无时间限制情况:可以采用顺序搜索进行最直观的冲突解决,无需特别的数据结构优化。
- 空间和时间受限情况:在实际应用中,需要兼顾时间和空间效率,这时就需要运用到真正的哈希技术。
1:哈希函数
1.1:计算哈希函数

理想目标:对键进行均匀随机打乱以生成表索引。
- 计算效率高。
- 对于每个键,每个表索引具有同等的概率被生成。(这是一个经过深入研究但仍存在实际应用问题的难题)
示例 1:电话号码。
- 不好:前三位。
- 更好:最后三位数字。
美国的电话前三位是区号,可以考虑日常生活中的电话号码,前三位一般是所属运营商,通常情况下会使用后四位数字进行简单区分(例如取快递报手机号后四位)。
示例 2:社会保险号。
- 不好:前三位。(573 = 加利福尼亚州,574 = 阿拉斯加(按地理区域内的时间顺序分配)
- 更好:最后三位数字。
书里面的相关描述:

实际挑战:每种密钥类型需要不同的方法。
1.2:Java中的哈希码规范

所有 Java 类都继承了一个方法 hashCode(),该方法返回一个 32 位整数。
要求:如果 x.equals(y),则 (x.hashCode() == y.hashCode())。
高度期望:如果 !x.equals(y),则 (x.hashCode() != y.hashCode())。
默认实现:返回对象x的内存地址。
合法(但较差)的实现:始终返回 17。
定制化实现示例:Integer、Double、String、File、URL、Date 等。
用户自定义类型:对于用户自定义的类型(需要自行设计和实现)。
1.2.1:哈希码实现:integers、booleans、doubles

找了一下 jdk 包的源码:
Oracle OpenJDK version 11.0.6
java.lang.Integer#hashCode
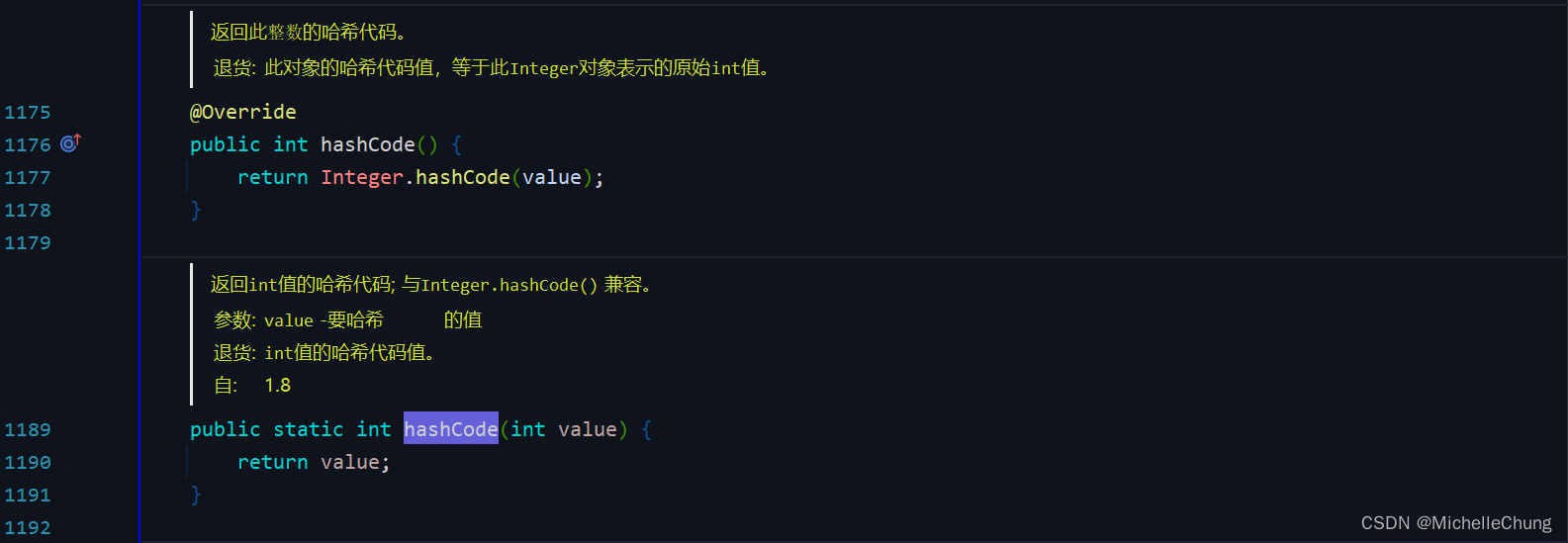
java.lang.Boolean#hashCode

java.lang.Double#hashCode

1.2.2:哈希码实现:strings
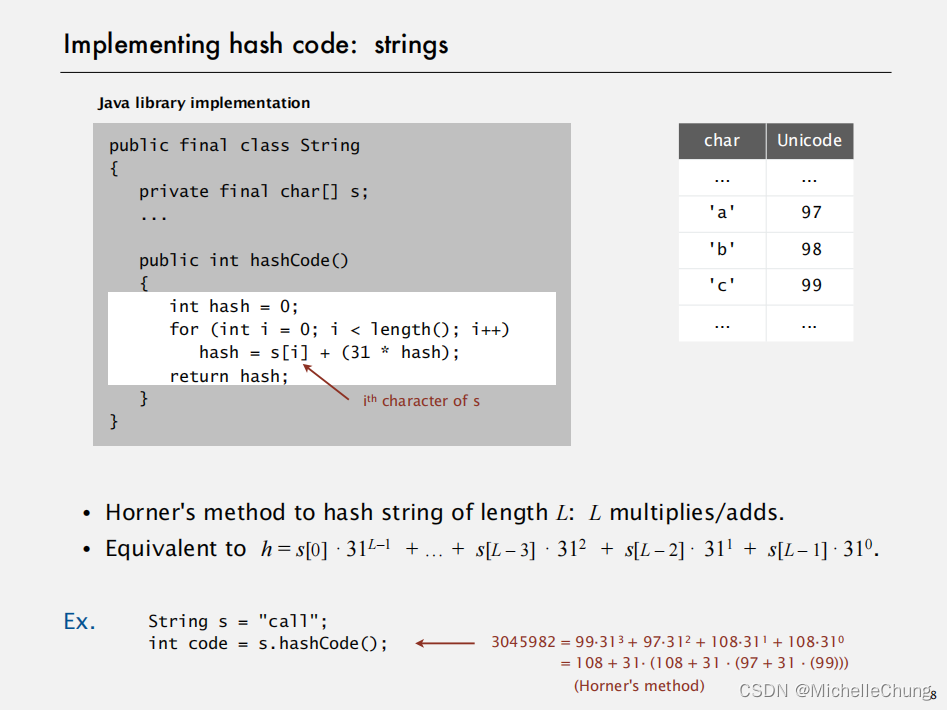
霍纳法则(Horner’s method)用于计算长度为L的字符串哈希值:需要进行L次乘法和加法操作。

同样地,找了一下 jdk 包的源码(不过版本差异因此实现有出入,这里看一下 jdk 11 以及 jdk 8 的实现):
Oracle OpenJDK version 11.0.6
java.lang.String#hashCode
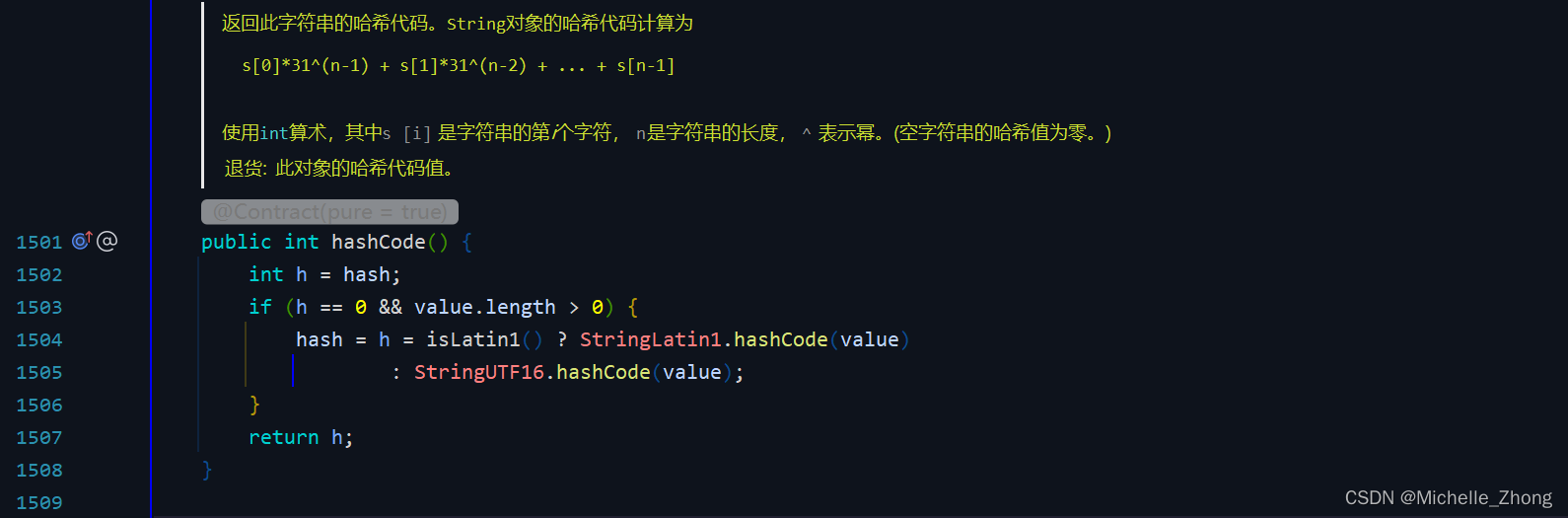
jdk 11 区分了不同的字符集 StringUTF16 以及 StringLatin1:
java.lang.StringUTF16#hashCode

java.lang.StringLatin1#hashCode

来看看 jdk 8 的实现:
java version 1.8.0_192
Java.lang.String#hashCode

1.2.3:哈希码实现:用户自定义类型
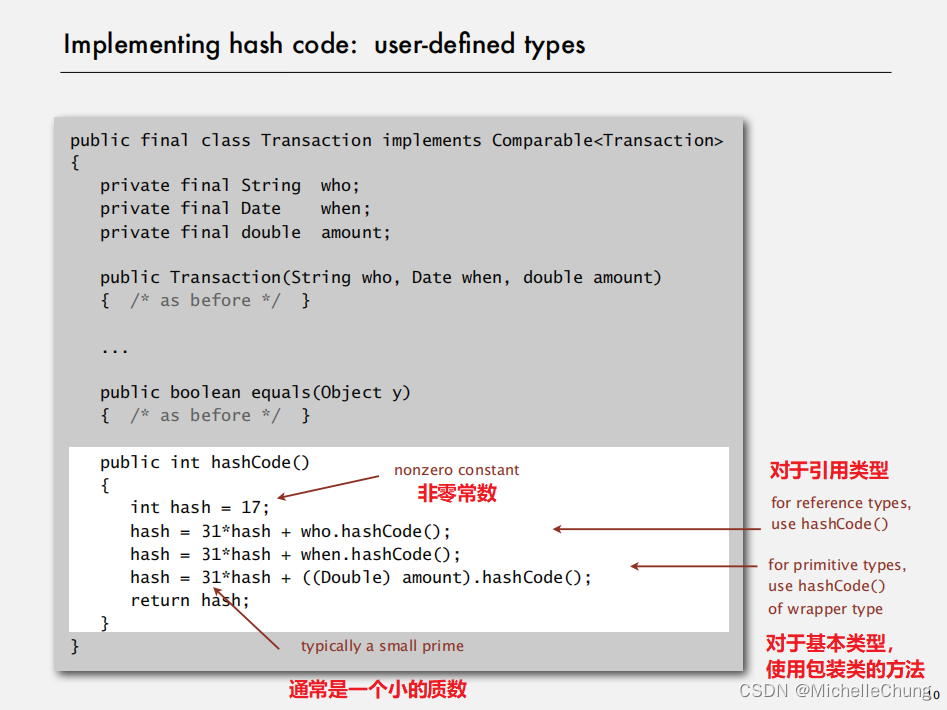
1.3:哈希码设计

用户自定义类型的“标准”设计方法:
- 采用
31x + y规则组合每个有意义的字段。 - 如果字段是基本类型,则使用包装器类型的 hashCode() 方法计算。
- 如果字段为 null,则返回0。
- 如果字段是引用类型,则使用 hashCode() 方法(递归应用,对引用对象进行同样规则的计算)。
- 如果字段是数组,则对每个元素应用此规则。(或者可以使用 Arrays.deepHashCode() 方法)
实际应用中,这个方法在 Java 库中被广泛采用,并且表现相当不错。
理论上,键被视为比特串;存在“通用”的哈希函数。
基本原则:计算哈希码时需要使用整个键;
若要获取最先进的哈希码计算方法,请咨询专家。
1.4:模块化哈希
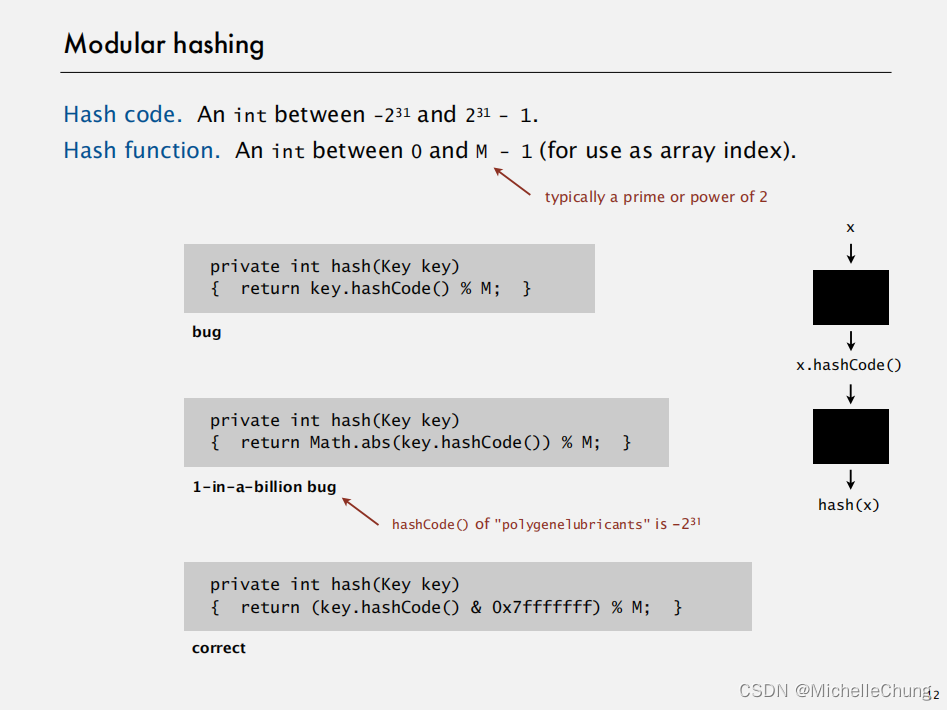
1.5:均匀哈希假设

均匀哈希假设:任何给定的键都具有相等的概率映射到从 0 到 M-1 之间的任何一个哈希槽(桶)内。
桶与球模型:假设我们将球均匀随机地投入 M 个桶中。
生日问题:当随机向 M 个桶中抛掷约 √(πM/2) 次时,预计会出现至少有两个球落入同一桶的情况。
优惠券收集者问题:在大约 MlnM 次投掷之后,可以期望每个桶里至少有一个球。
负载均衡:在进行M次投掷操作后,预期最繁忙的桶所容纳的球的数量大约为 Θ(log M / log log M)。
2:分离链接 / 独立链表 Separate Chaining
对应章节:3.4.2 基于拉链法的散列表
2.1:哈希碰撞(哈希冲突)

哈希碰撞。两个不相同的键被散列至同一个索引位置。
- 根据生日问题理论,除非拥有极其庞大的(平方级别的)内存空间,否则无法完全避免碰撞。
- 结合优惠券收集者问题和负载均衡原则,可以确保碰撞在各个索引位置上均匀分布。
挑战:如何高效地应对这种碰撞情况。
2.2:分离链接 ST

采用一个包含M(M小于N)个链表的数组实现。[该方法由H. P. Luhn于1953年在IBM公司提出]
- 哈希函数:将键转换为介于 0 和 M-1 之间的某个整数索引 i。
- 插入操作:将新元素添加到第 i 个链表的头部(若该元素不在链表中)。
- 查找操作:仅需在第 i 个链表中进行搜索。
2.3:Java 实现:查找、插入
edu.princeton.cs.algs4.SeparateChainingHashST
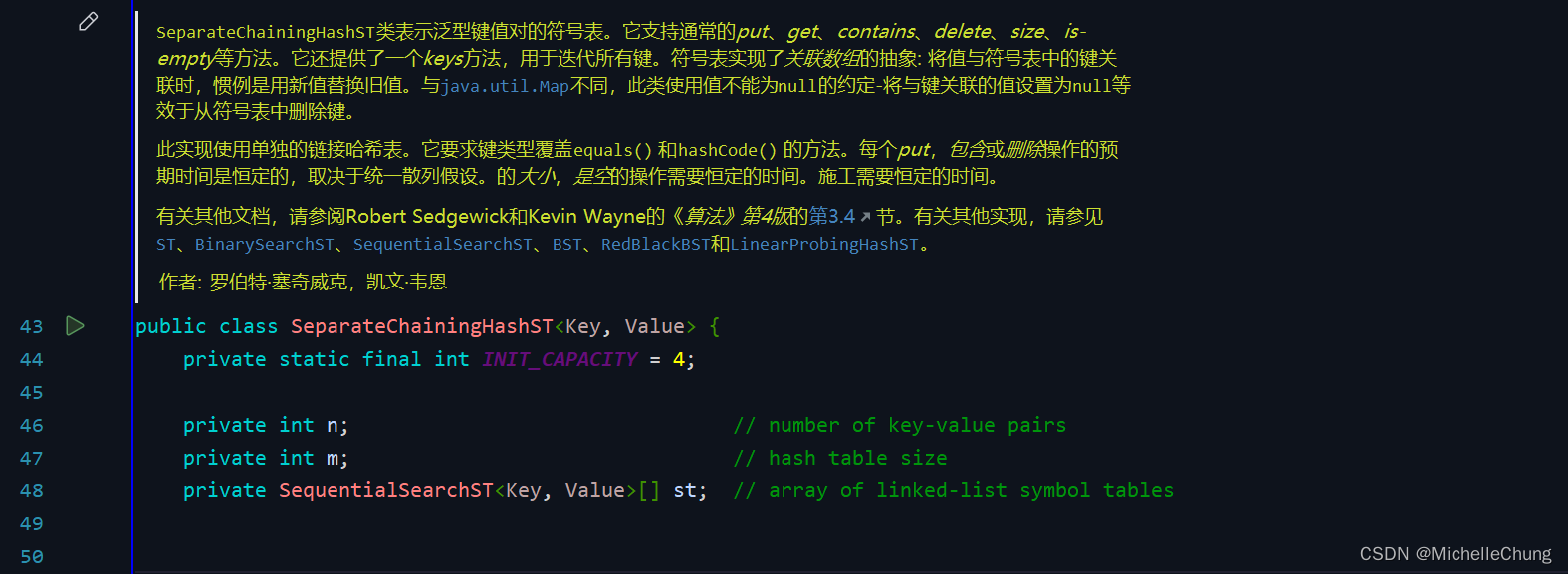
edu.princeton.cs.algs4.SeparateChainingHashST#get

edu.princeton.cs.algs4.SeparateChainingHashST#put

2.4:分离链接分析

这里对应的是书本里面的几个假设以及性质:
假设J(均匀散列假设)。我们使用的散列函数能够均匀并独立地将所有的键散布于0到M-1之间。
命题K。在一张含有M条链表和N个键的的散列表中,(在假设J成立的前提下)任意一条链表中的键的数量均在N/M的常数因子范围内的概率无限趋向于1。
性质L。在一张含有M条链表和N个键的的散列表中,未命中查找和插入操作所需的比较次数为~N/M。
感兴趣的朋友可以去书里面看一下证明的方法,这里不再赘述。
2.5:(补充)Java 实现:调整大小
注:教授在视频里面没有讲到这一小节,根据资料和书本进行补充。
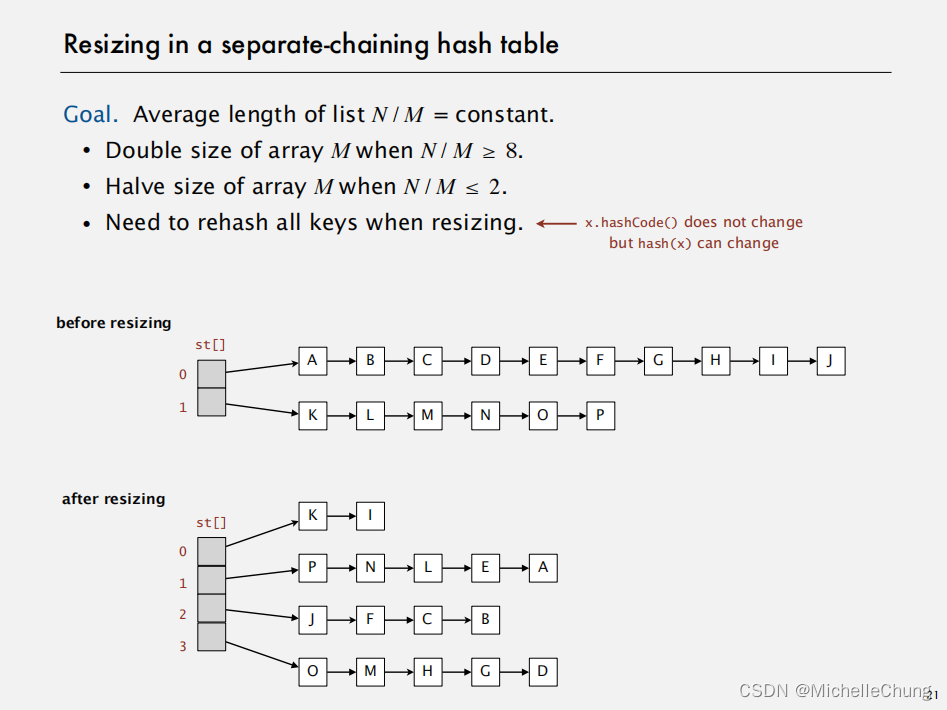
目标:使得链表平均长度(即元素总数N除以桶数量M)维持恒定。
- 若链表平均长度 N / M 大于等于8,则将数组M的容量加倍。
- 若链表平均长度 N / M 小于等于2,则将数组M的容量减半。
- 每当调整数组大小时,必须对所有键执行重新哈希操作。
edu.princeton.cs.algs4.SeparateChainingHashST#resize

2.6:(补充)Java 实现:删除
注:教授在视频里面没有讲到这一小节,根据资料和书本进行补充。

edu.princeton.cs.algs4.SeparateChainingHashST#delete

2.7:ST 实现小结

3:线性探测 Linear Probing
对应章节:3.4.3 基于线性探测法的散列表
3.1:碰撞解决方案:开放式寻址

书中关于开放寻址线性探测的描述:

3.2:demo 演示:插入

哈希:通过计算将给定键映射为一个介于 0 和 M-1 之间的整数索引 i。
插入操作:若哈希表中索引为i的位置未被占用,则将元素存入该位置;否则,依次检查 i+1、i+2 等后续位置,直到找到一个空闲的槽位来存放该元素。
线性探测哈希表:

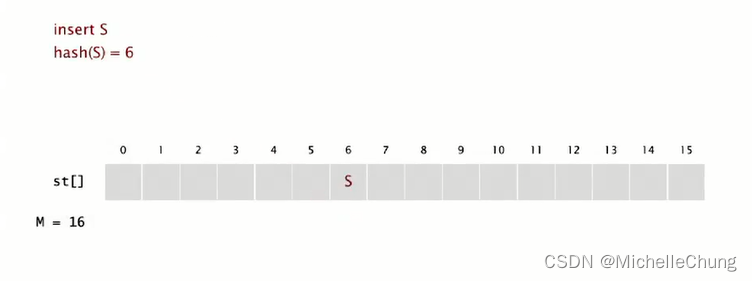
插入 S,hash(S) = 6:
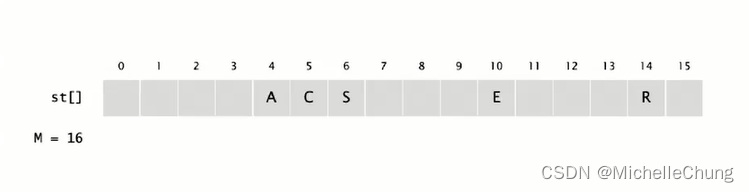
插入 E,hash(E) = 10;
插入 A,hash(A) = 4;
插入 R,hash(R) = 14;
插入 S,hash(R) = 5;
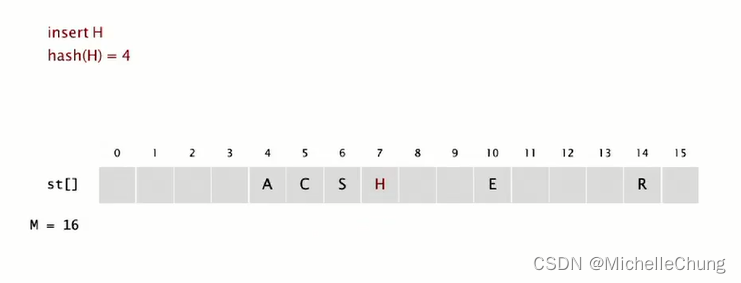
插入 H,hash(A) = 4:

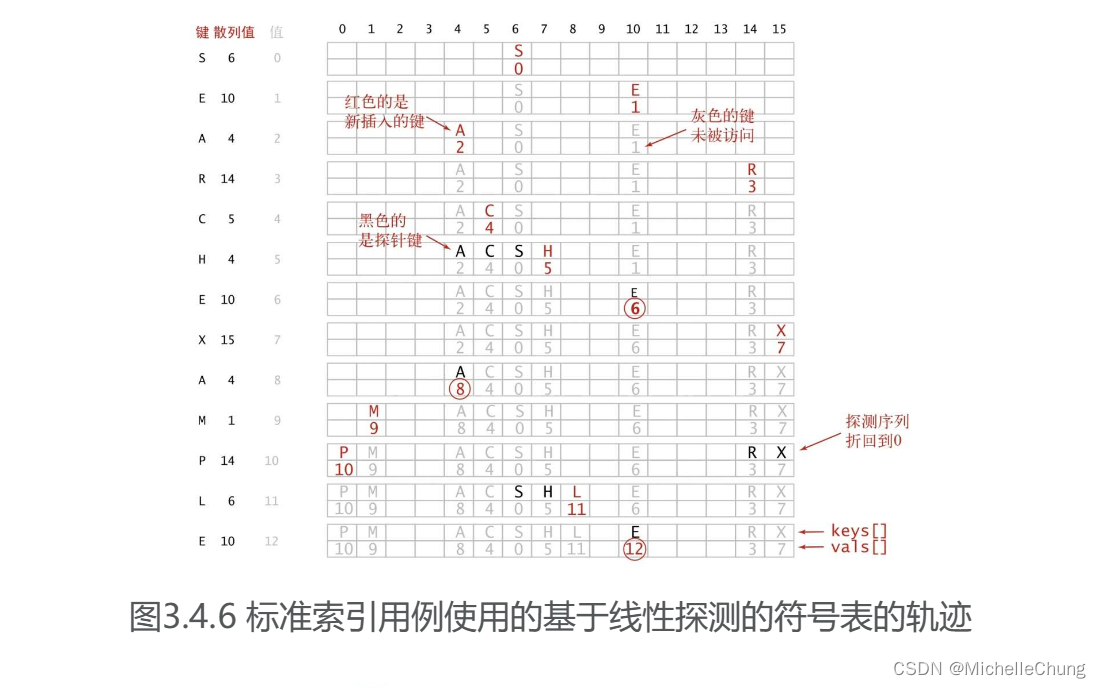
插入 X,hash(X) = 15;
插入 M,hash(M) = 1;
插入 P,hash(P) = 14:


插入 L,hash(L) = 6,冲突,最终插入 8:

书本的轨迹图可以参考一下:
3.3:demo 演示:搜索

哈希:通过计算将给定键转换为一个位于 0 到 M-1 之间的整数索引 i。
搜索操作:首先查找哈希表中对应索引 i 的槽位,若该位置已存在元素但不匹配目标键,则依次检查 i+1、i+2 等后续槽位,直至找到匹配项或确定不存在匹配项为止。
搜索 E,hash(E) = 10:
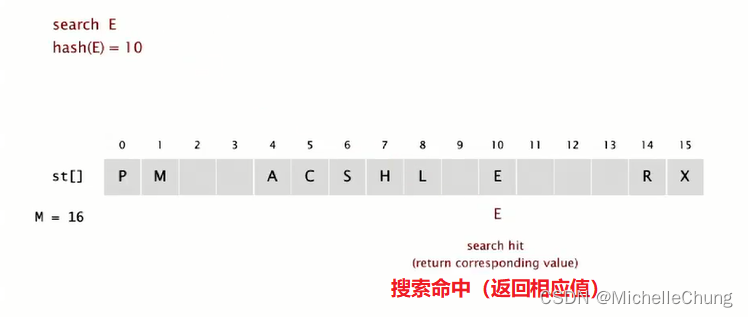
搜索 L,hash(L) = 6:

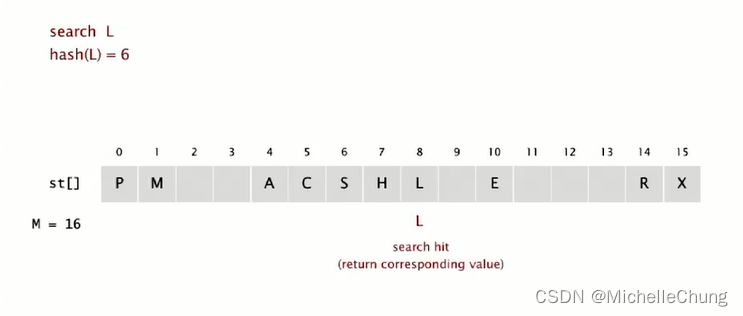
搜索 K,hash(K) = 5:

当探测遇到空槽:

3.4:线性探测小结

哈希:通过计算将给定键映射为一个介于 0 和 M-1 之间的整数索引 i。
插入操作:若哈希表中索引为i的位置未被占用,则将元素存入该位置;否则,依次检查 i+1、i+2 等后续位置,直到找到一个空闲的槽位来存放该元素。
搜索操作:首先查找哈希表中对应索引 i 的槽位,若该位置已存在元素但不匹配目标键,则依次检查 i+1、i+2 等后续槽位,直至找到匹配项或确定不存在匹配项为止。
注意:数组大小 M 必须大于键值对数量 N。
3.5:Java 实现:查找、插入
edu.princeton.cs.algs4.LinearProbingHashST

edu.princeton.cs.algs4.LinearProbingHashST#get
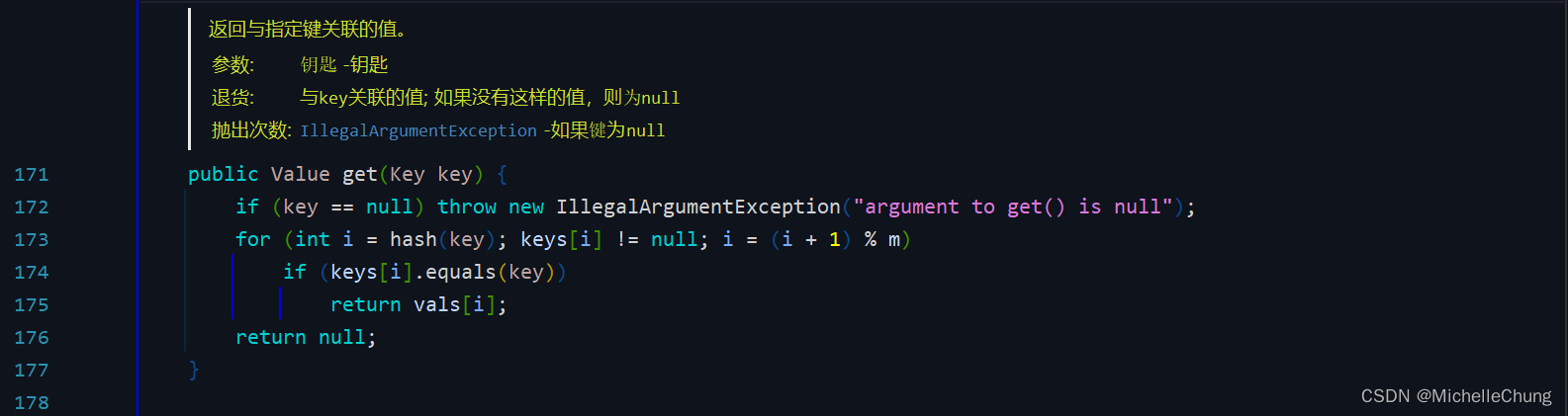
edu.princeton.cs.algs4.LinearProbingHashST#put

3.6:键簇
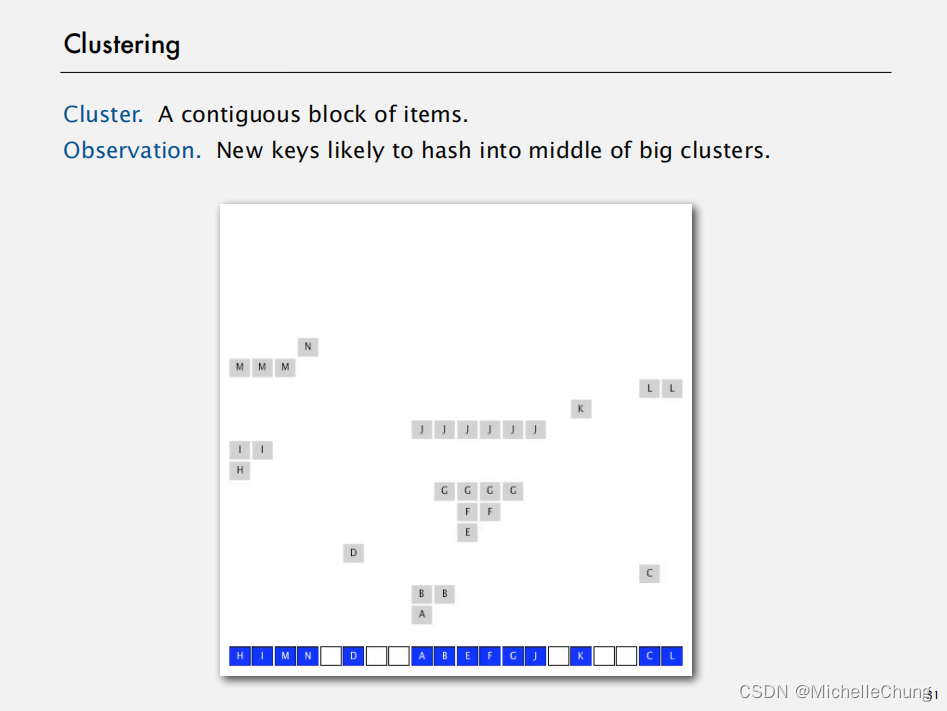
键簇:连续的一组数据项。
观察发现:新添加的键在哈希过程中,有较大几率被分配到已存在的大型数据簇的中部。
3.7:停车问题

3.8:线性探测分析

这里对应的是书本里面的性质:

3.9:(补充)Java 实现:调整大小
注:教授在视频里面没有讲到这一小节,根据资料和书本进行补充。
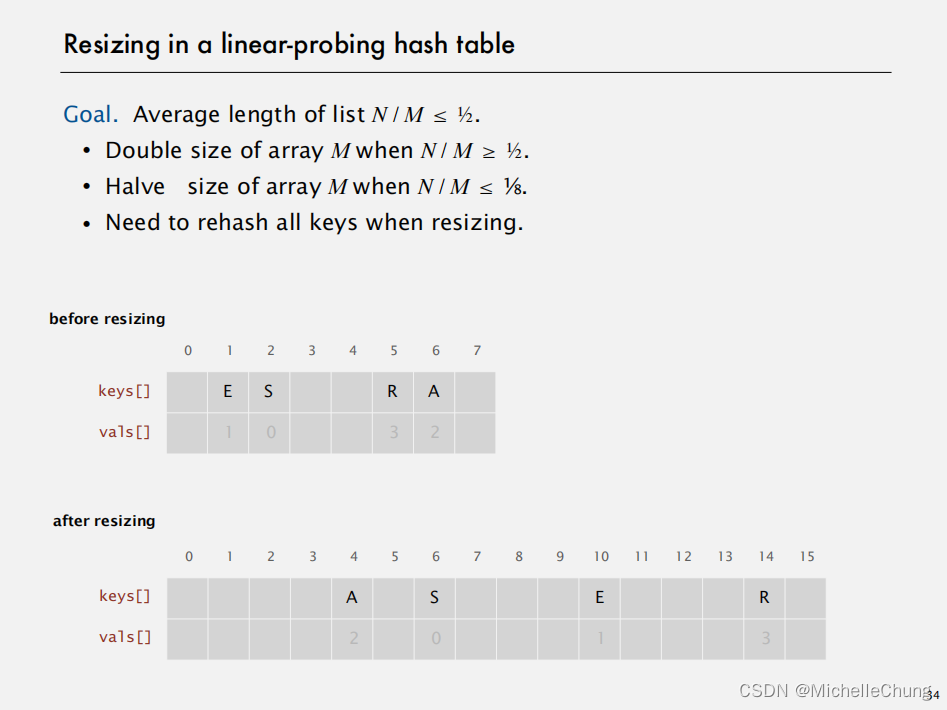
目标:使得链表平均长度(元素总数N除以桶数量M)不超过1/2。
- 若链表平均长度 N / M 大于等于1/2,则将数组M的容量加倍。
- 若链表平均长度 N / M 小于等于1/8,则将数组M的容量减半。
- 每当需要调整数组大小时,必须对所有键执行重新哈希操作。
edu.princeton.cs.algs4.LinearProbingHashST#resize
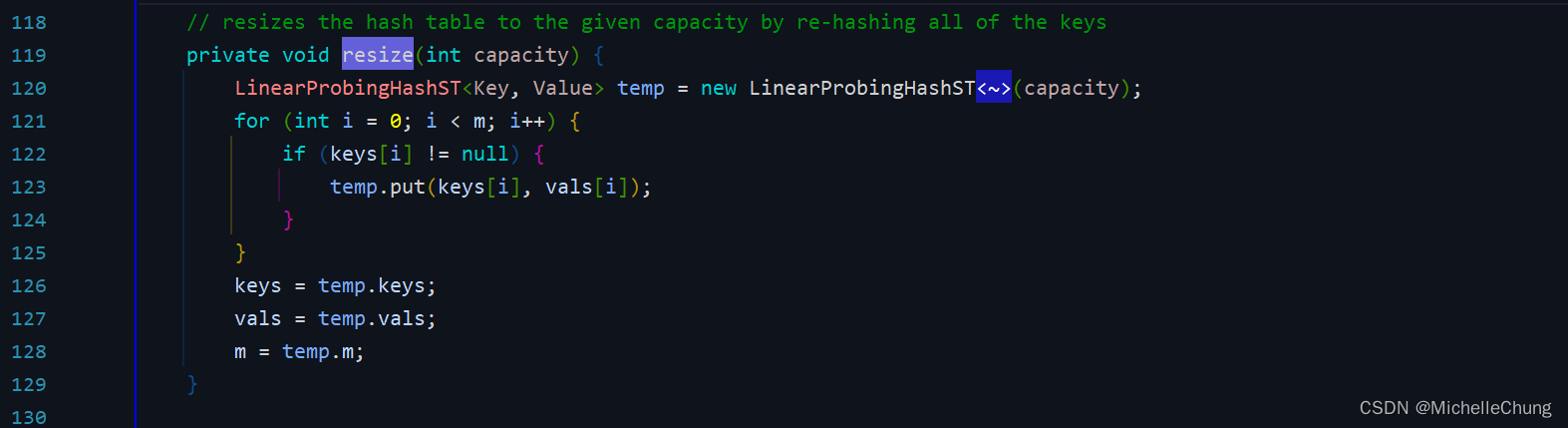
3.10:(补充)Java 实现:删除
注:教授在视频里面没有讲到这一小节,根据资料和书本进行补充。

edu.princeton.cs.algs4.LinearProbingHashST#delete
源码太长了不好截图,直接贴一下:
/**
* Removes the specified key and its associated value from this symbol table
* (if the key is in this symbol table).
*
* @param key the key
* @throws IllegalArgumentException if {@code key} is {@code null}
*/
public void delete(Key key) {
if (key == null) throw new IllegalArgumentException("argument to delete() is null");
if (!contains(key)) return;
// find position i of key
int i = hash(key);
while (!key.equals(keys[i])) {
i = (i + 1) % m;
}
// delete key and associated value
keys[i] = null;
vals[i] = null;
// rehash all keys in same cluster
i = (i + 1) % m;
while (keys[i] != null) {
// delete keys[i] and vals[i] and reinsert
Key keyToRehash = keys[i];
Value valToRehash = vals[i];
keys[i] = null;
vals[i] = null;
n--;
put(keyToRehash, valToRehash);
i = (i + 1) % m;
}
n--;
// halves size of array if it's 12.5% full or less
if (n > 0 && n <= m/8) resize(m/2);
assert check();
}
3.11:ST 实现小结

4:哈希背景
本小节省略了一些内容介绍,如果对原内容感兴趣的朋友建议移步原视频学习。
4.1 哈希算法变体

两探针哈希(Two-probe hashing)[ 分离链接(separate-chaining)变种 ]:
- 将键散列到两个位置,并将键插入较短的那个链表中。
- 可以将最长链的预期长度降低至 log log N。
双重哈希(Double hashing)[ 线性探测法(linear-probing)变种 ]:
- 使用线性探测方法,但每次不只跳过1个位置,而是根据一个变量值跳跃。
- 实质上消除了聚集现象。
- 允许哈希表接近满载状态。
- 实现删除操作较为复杂。
布谷鸟哈希(Cuckoo hashing)[ 线性探测法(linear-probing)变种 ]:
- 将键散列到两个位置,将键插入其中一个空闲位置;如果该位置已被占用,则将被替换的键重新插入其备选位置(并递归执行此过程)。
- 在最坏情况下搜索的时间复杂度为常数。
4.2 哈希表 vs 平衡查找树

哈希表:
- 编码更简单。
- 对于无序键,没有有效的替代方案。
- 对于简单键(只需执行几次算术操作,而非 log N 次比较),查找速度更快。
- 在 Java 中对字符串提供更好的系统支持(例如,缓存哈希码)。
平衡搜索树:
- 提供更强的性能保证。
- 支持有序集合操作(如插入、删除和查找)。
- 实现 compareTo() 方法相对于 equals() 和 hashCode() 方法来说更容易正确完成。
Java 系统同时包含两者:
- 红黑树(Red-black BSTs):java.util.TreeMap 和 java.util.TreeSet。
- 哈希表(Hash tables):java.util.HashMap 以及根据对象标识进行散列的 java.util.IdentityHashMap。
















 4792
4792











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











