







简述
Meta 提出了一种训练大语言模型 (Large Language Models, LLMs)的新方法:一次预测多个token,有望实现更快、更智能的 AI 模型,有可能彻底改变当前主流的模型训练方法,该方法在多项任务,尤其是编码任务上取得了重大改进。
摘要
Meta 提出了一种新颖的训练 LLMs 的方法,这种方法在进行模型训练时同时预 测多个 token,而不是传统的每次预测一个token 的方法。这种多 token 模型不仅 将文本生成速度提高了三倍,而且还提高了模型的智能性,MBPP 和 HumanEval 等编码基准的卓越性能证明了这种方法的有效性。新的架构包括额外的输出头, 允许模型在进行预测时考虑后续标记的上下文,从而产生更加连贯和上下文适当 的输出。虽然语言建模的好处不太明显并且需要进一步扩展,但该方法在语法准 确性至关重要的编码等领域显示出极大的提升。多 token 预测方法也符合行业向 更高效解码方法的转变,这是由于需要大量 token 生成以进行用户交互的长推理 模型的出现所必需的。
Meta 通过新的研究提供了一种训练大模型的新方法:模型可以在每次预测中同 时预测多个 token,而不仅仅是一个,并且与之前的方法不同,没有额外的训练 开销。这种方法不仅可以加快模型的文本生成速度,还可以使模型变得更加智能, 这种方法有望成为意前沿人工智能的新训练范式。
弱学习形式
现有的 LLMs 都以同样的、非常低效的方式进行学习。在训练深度神经网络时, 必须人工定义希望模型优化的任务。对于 LLMs 来说,这种任务就是预测下一个 单词;模型接收文本序列形式的一组单词输入,并预测下一个 token (单词或子 单词)。然后,将该 token 添加到前面输入的序列中,并将得到的新序列输入到模 型种,生成下一个 token ……如此循环进行。
与当今的所有神经网络一样,需要找到一种方法来衡量模型的每个预测的好坏, 并使用该衡量的结果 (模型预测的好坏)来随着模型的训练逐步减少这种模型预 测的“误差”。
技术说明
如今,大多数人工智能模型都是类似“参数曲线”形式的,也就是极高维的多元函 数,模型接受一组输入后预测一个或多个输出。从技术角度讲,模型能够工作得益于多层感知机 (Multilayer Perceptron,MLP)的广泛使用。事实上, 可以证明,
每个神经网络都有某种形式的 MLP(在 LLM 的情况下,与注意力机制相结合), 由于通用逼近原理,这个极其复杂的神经网络可以逼近未知的期望函数,或 UAT 。但这些模型不仅仅是预测一个词的合理性,而是对分布进行建模。
由于希望训练好的模型能够对整个书面语言进行建模,并在需要时具有较好的创 造性,因此该预测不仅仅是模型认为最合适的单词,我们强制模型为模型预测的 每个token 分配一个概率。通过这种方式,模型必须考虑自然语言中的不确定性, 因为许多不同的单词可能是任何给定序列的合理延续。例如,对于一个序列“The boy went to the …” ,模型给出的五个选项在语义上都是有效的,但只有一个是标 准答案 (Ground Truth)。

基于以上分析,应该如何衡量模型预测的误差呢?
LLMs 如何学习
在 LLMs 的情况下,通过交叉熵函数(cross-entropy function)来实现模型的学习, 该函数本质上只关注模型分配给真实单词的概率。函数公式如下所示:
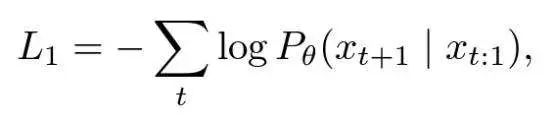
基于上面的示例,我们可以看到模型分配给下一个单词“Playground”的概率是 40% ,由于我们定义“Playground”是标准答案,所以模型预测的概率远低于应该 的数值(100%),因此模型需要调整其参数。
当概率分布不是极度偏向真实情况时(与前面的示例不同, 为该 token 分配了非 常高的值),这里说模型是“困惑”的,或者对其预测表示怀疑。因此,衡量模型错 误的主要指标是模型的“困惑度”,或者说它对下一个单词的确定程度。“困惑度” 值越低,模型越好。这是一个相当缓慢且需要大量数据的过程,因此该模型被馈 送到整个公共互联网,直到它能够始终如一地为正确的单词分配非常高的概率。
如果创建的模型对于几乎任何给定的序列都可以准确地预测接下来会发生什么, 那么我们就可以认为该模型就能够讲该语言、在语言之间进行翻译、执行基本的 推理等。换句话说,预测下一个 token 的任务已经变得普遍,每个人都遵循这种 方法来训练 LLMs。
在推理中,当模型训练完成后,就执行自回归解码 (autoregressive decoding)。通俗地说,该模型将以循环的方式生成序列的下一个 token ,token 总是向后看, 而不是向前看。因此,生成任何给定单词的概率仅取决于较早出现的单词。
然而,以上的这种方法很可能会被 Meta 提出的新方法取代。
一次预测更多的 token
Meta 提出了一种全新的模型训练方法,这也意味着模型的整体架构发生了变化。
简而言之,Meta 修改 LLM 以预测接下来“k”个单词而不是下一个单词(这里的 k 固定为 4)。为此,可以向模型添加更多输出头,每个头执行相同的练习:预测 序列中接下来的 4 个token。
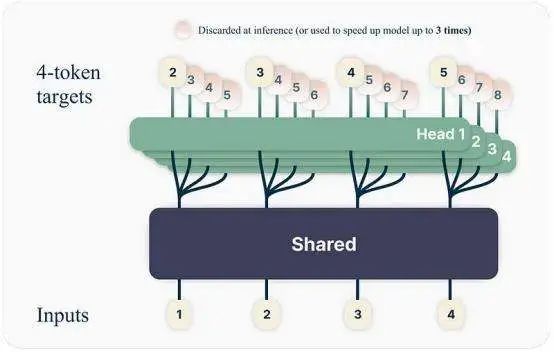
需要注意的是,这并不意味着预测的 token 总数为 16。虽然所有四个头都会产生4 个 token,但模型只保留每个头中的最后一个 token (在上图中表示为单词 5、6 、7 和 8)。
例如,对于著名的披头士乐队主唱约翰·列侬的歌词“You may say I’m a dreamer, but I’m …”, 一般的 LLM 会分别预测“not”,然后是“the”,然后是“only”,最后是“one”。相反, Meta 的模型会在一次预测中给出以上的四个 token,将生成速度提高三倍。
或者,我们可以丢弃额外的头并执行标准的下一个单词预测任务。需要注意的是:虽然我们可以在预测中一次只预测一个 token 并丢弃其他头,但是在模型训练中 同时预测 4 个 token 相对于每次只预测 1 个 token 有着很大的优势。
更智能的学习过程
Meta 提出这种训练模型可以让模型更加聪明。当针对大规模编码任务进行训练 时,这些模型获得了比标准 LLM 架构更好的结果,MBPP 和 HumanEval 编码 基准的结果证明了这一点。当在一定规模 (30 亿个参数以上)进行测量时,每次 预测 4 个token 的大模型的准确度大大超过了每次预测 1 个token 的标准 LLMs。
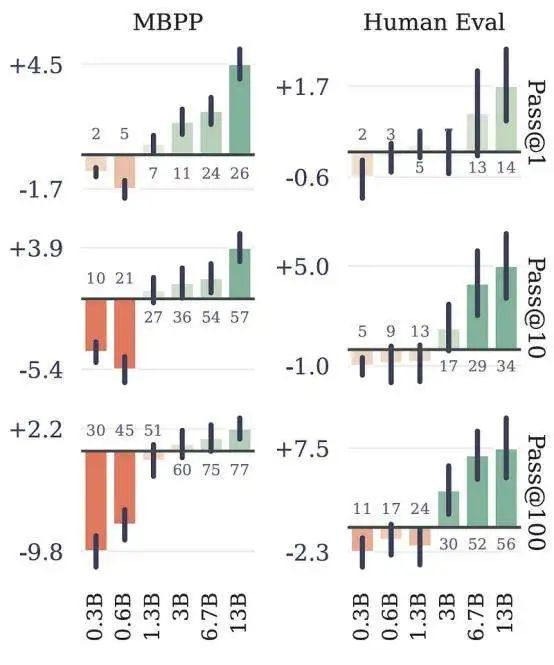
与结果非常清晰的编码不同,当涉及建模语言时,这些好处并不那么明显。研究 人员推测这是由于规模不足造成的,并且这种趋势对于非常大的模型也应该如此。
由此引出一个新的问题:为什么多个下一个标记预测可以创建更好的模型?
并非所有预测都是一样的
所有输出头共享相同的 LLM 主干(在前面的描述中描述为“共 Shared”)。这意味 着所有头都使用相同的表示(具有相同的可用信息)来预测接下来的四个 token 。简而言之,为了使模型发挥良好作用,这种共享表示不仅必须考虑之前的单词, 还必须考虑在任何给定时刻预测的单词可能出现的下一个单词。
当某些单词直接影响下一个单词时(研究人员将这个术语称为“选择点”),这一 点尤其重要。另一方面,在某些情况下,下一个预测的单词可能与接下来的单词 无关。
换句话说,并非所有预测都是一样的,并且在开发序列时,有些预测比其他预测 更重要。这里举例说明:
选择点
给定一个序列“The hero entered the dark cave, unsure what he might find. Suddenly, he heard a …” 。此时,下一个预测的词可以显着影响故事的方向。例如,如果模 型预测“roar”,然后预测“coming from a rat,”,这个预测结果就属于较差的预测。由此可见,“roar”严重制约了接下来的预测。
无关紧要的预测
现在,考虑一个角色执行一项普通任务的上下文:“She picked up the pen and started to …”。在这里,下一个预测的词可能对整体叙述无关紧要。例如, 无论下一个单 词是“write” 、“draw”还是“doodle”,故事都保持不变;结果不会改变,因为在所 有情况下执行的活动都是相似的。
通过以上两个例子想要表达的观点是,通过训练模型来预测接下来的4 个token, 该模型将更有可能意识到如果执行错误(选择点),下一个预测是否是高风险, 从而提高生成质量。
关于为什么下一个令牌预测可以提高性能的另一个直解释是,它强化了本地模式。
语法很微妙
在标准的下一个单词预测中,每个单词都是独立预测的,尽管 LLMs 仍然可以学 习彼此接近的单词之间的模式(模型知道“I play the guitar”是正确的,“Iguitar the play”是不正确的),如果我们强制模型同时预测所有四个,模型将学习按该顺序 生成标记,从而消除第二个生成序列出现的机会。这也解释了为什么在编码中观 察到了最好的结果。
编码中的语法错误更加微妙,并且会产生巨大的负面影响(代码无法运行),这 意味着虽然 LLMs 在自然语言中很少犯语法错误,但模型很少编写完美的代码。
因此,通过多 token 预测,允许 LLMs 学习这些短的局部模式,以便模型可以同时输出整个模式。
但正如之前提到的,这些模型也更快。但依然有办法可以让模型更快!
如果需要更快的模型,可以同时运行所有四个头来一次性预测多个 token 。实现 此目的的一种方法是由 Together.ai 的研究人员创建的 Medusa,与标准 LLMs 相比,它的生成速度提高了三倍。
这在语言生成中似乎没有太大的必要,但如果考虑代码、图像或视频, 吞吐量的 大小就非常重要。此外,即使对于普通的文本情况,在处理大批量的文本时模型 也会变得非常慢。
在 Medusa 中,每个头在生成过程中都被分配一个位置。如果有四个头,则每个 头负责预测一个 token(第一个头预测第一个 token,第二个头预测第二个 token , 依此类推)。
准备好每个位置的 token 的前 k 个预测后,模型将构建一组候选者,并使用以 下启发式方法选择候选者:选择最长的有效候选者。
为了确定候选者是否有效,Meta 研究人员使用一种典型的接受方案,其中候选 一代必须是“典型的”,也就是不一定是理想的,但仍然有效。其他选项可能是使 用非常小的代理模型来验证候选语法并选择最长的语法。
更好的模型,新标准?
总的来说,Meta 的这项研究可能会在模型训练在这方面有所作为。但是仍然需 要更大的模型来证明这种新的训练范式的有效性,但是基于其结果的更好、更智 能的模型将不可避免地迫使业内许多人至少测试这种方法,特别是在编码模型方 面,这种方法被广泛使用的可能性很大。
随着大推理模型的出现,它极大地增强了模型的推理能力,可能将成为人工智能 的下一个前沿,考虑到每次用户交互可能需要数以千计的 token,寻找更有效的 解码方法是可行的,甚至是使这些新模型在技术和经济上可行是必要的。
— 完 —


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









