







初学者要学会基本的爬虫
先要安装包requests
requests的安装
1. 下载requests
打开这个网址,
http://www.lfd.uci.edu/~gohlke/pythonlibs
在这个网站上面有很多 python 的第三方库文件,我们按 ctrl+f 搜索很容易找到 requests 。如下图,

点击那个 .whl 文件然后下载下来。
2. 将 .whl文件下载下来后,将文件重命名,将后缀名从 .whl 改为 .zip ,然后解压文件,我们可以得到两个文件夹,如下图,

我们将第一个文件夹,也就是 requests 文件夹复制到 python 的安装目录下的 lib 目录下
3. 到这里,requests 已经安装完毕,我们可以输入 import requests 命令来试试是否安装成功,

如上图所示,import requests 没有报错,说明 requests 已经成功安装了。
下面开始第一个网页爬虫:
1获取该页面的源代码

2 有些网页禁止使用爬虫访问源代码 所以要加个头的代码让服务器误以为浏览器访问
修改http头绕过简单的反爬虫机制
#-*—coding:utf8-*-
import requests
import re
#下面三行是编码转换的功能,大家现在不用关心。
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
#hea是我们自己构造的一个字典,里面保存了user-agent
hea = {'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.118 Safari/537.36'} #加个头代码
# html = requests.get('http://jp.tingroom.com/yuedu/yd300p/')
html = requests.get('http://jp.tingroom.com/yuedu/yd300p/',headers = hea)
html.encoding = 'utf-8' #这一行是将编码转为utf-8否则中文会显示乱码。
print html.text
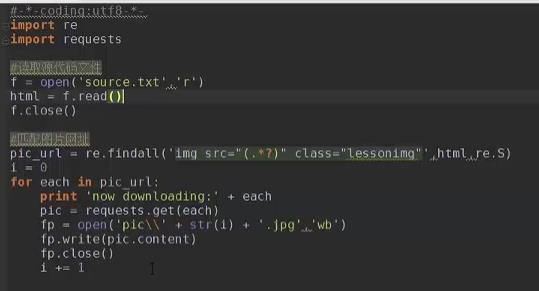
下面是一个实战的文本爬虫:
















 2995
2995

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









