







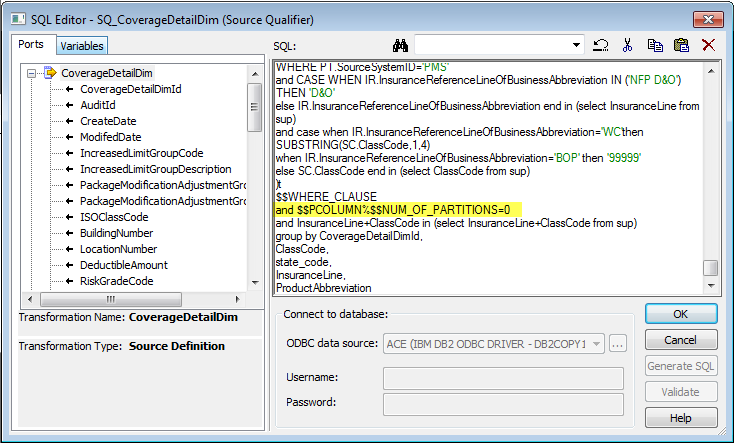
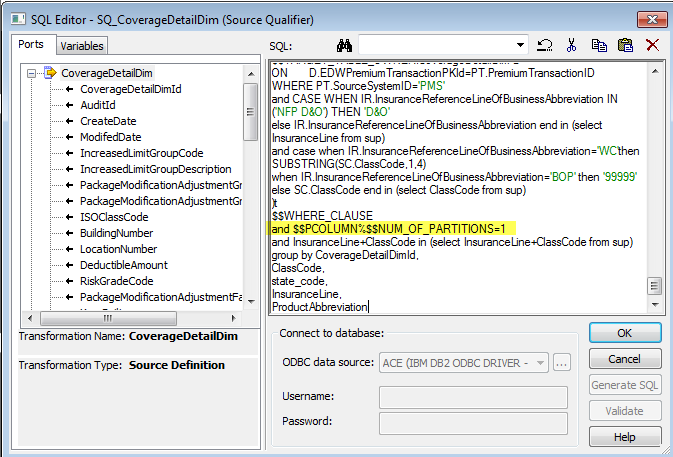
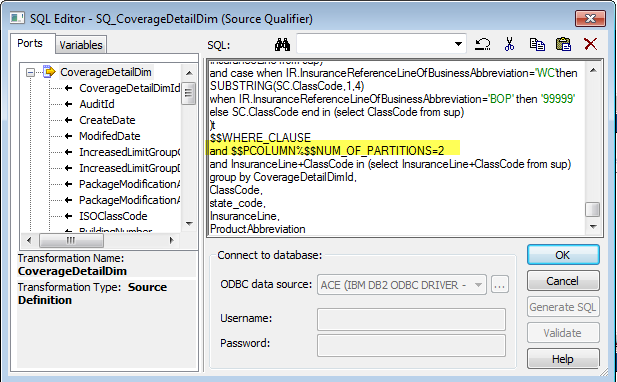
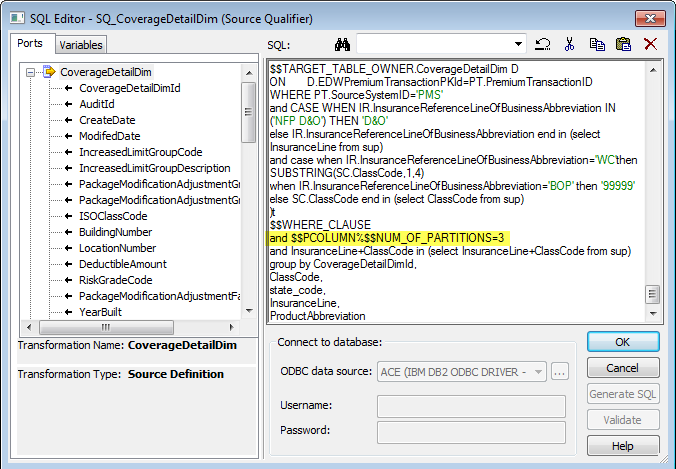
目前已经有很多并行运行工具及系统,但是如何在传统 BI 中实现并行化也是非常重要的。在这里我将总结一下如何在 Informatica 中使用 Partition 来提高数据抽取的性能。
在这里本人只贴图,忘有兴趣的同学自己好好揣摩。
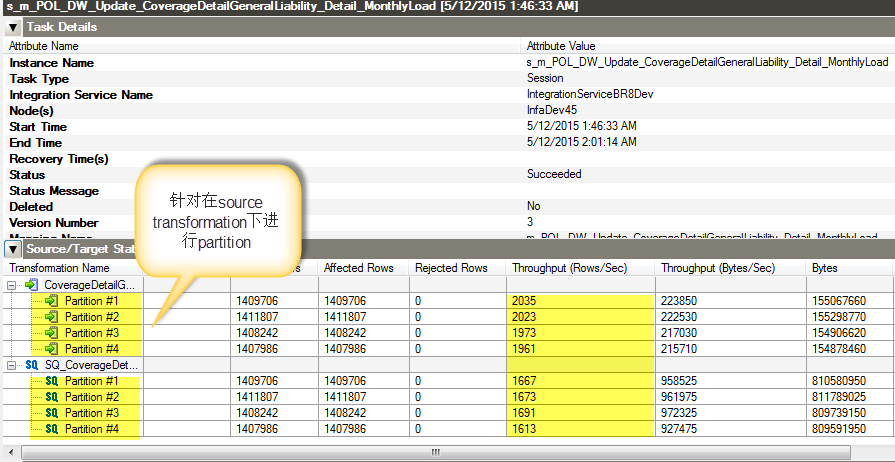
需要注意的是,并不是说分区越多越好,Informatica 做 SQL 抽取的时候是依赖于源数据库的性能,因此分区越多,I/O 也会相应增加,而且中间数据会放在缓存中,随着数据抽取的进行,速度将会逐渐变慢。因此要合理进行分区是非常重要的。



![]()
![]()
![]()
![]()
![]()
![]()
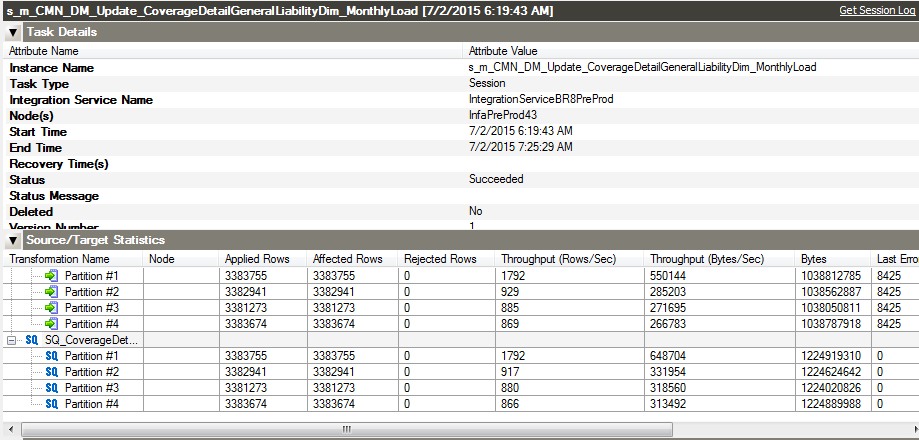
在这里本人只贴图,忘有兴趣的同学自己好好揣摩。
需要注意的是,并不是说分区越多越好,Informatica 做 SQL 抽取的时候是依赖于源数据库的性能,因此分区越多,I/O 也会相应增加,而且中间数据会放在缓存中,随着数据抽取的进行,速度将会逐渐变慢。因此要合理进行分区是非常重要的。
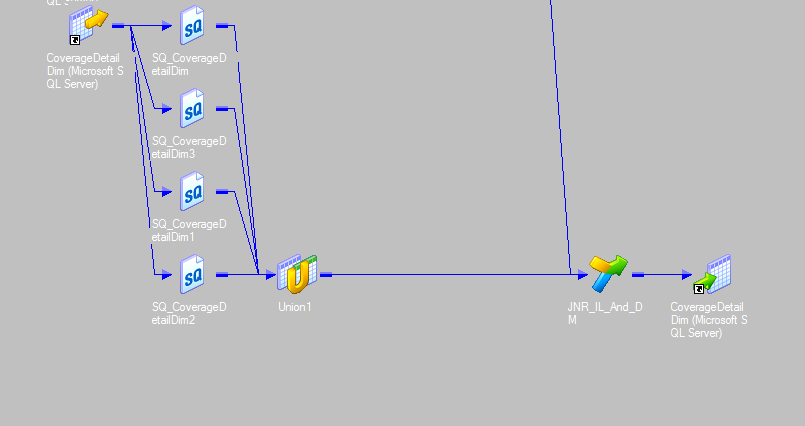
1. 将source qualifier根据 where条件进行拆分成多个单独的部分,但是会受服务器性能的影响
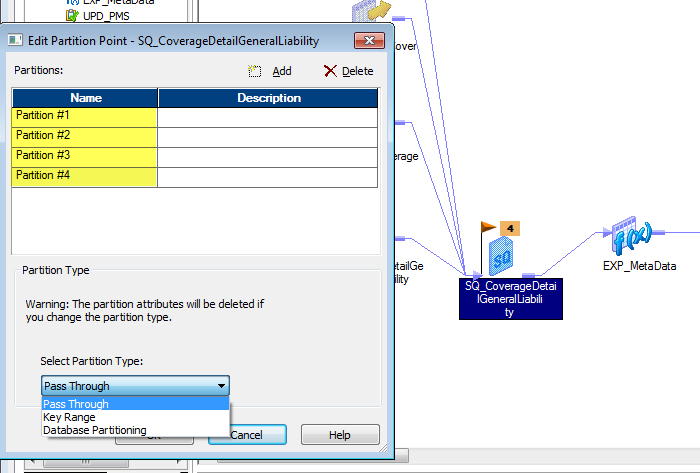
2. 在Session 里面进行配置
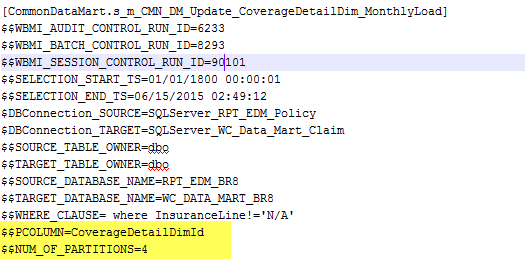
3. 可以通过增加参数来手动控制partition条件
Parameter file :
Session hard code:















 753
753











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









