









无论是传统数据库还是 Hadoop 数据仓库 Hive,我们都会涉及到窗口函数。今天利用 SQL Server 跟大家总结一下这Rank, Dense_rank, Row_number 三种函数的使用场景及区别:
1. Rank() vs Dense_Rank()
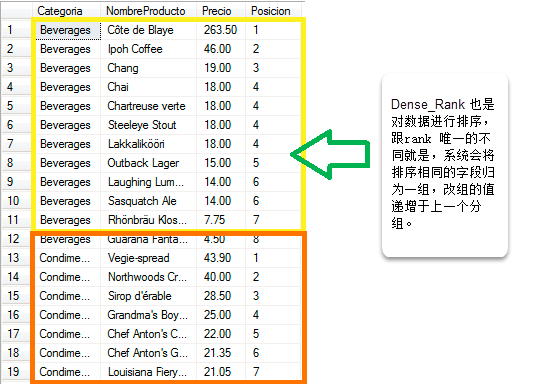
Rank() 会将数据进行排序。同一个分区下的对应的值从1开始递增,对于排序相同的字段拥有相同的排序值。不同的字段对应着自己在分区中排序位置。
Dense_Rank 也是对数据进行排序,跟rank 唯一的不同就是,系统会将排序相同的字段归为一组,改组的值递增于上一个分组。
--数据准备
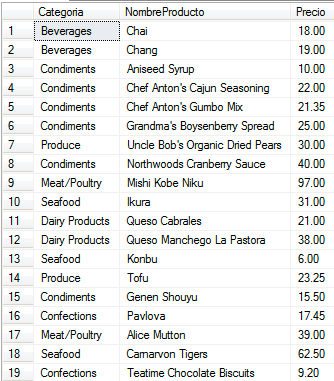
select Categoria, NombreProducto, Precio from Producto;
1.1 Rank()
Select Categoria, NombreProducto, Precio, RANK ()over(partitionby categoria
order by precio desc) as Posicion from Producto
order by precio desc) as Posicion from Producto

1.2 Dense_Rank()
SELECT Categoria, NombreProducto, Precio,dense_rank()over(partitionby categoria orderby precio desc) asPosicion from Producto
2. Row_Number() 的使用场景:
在这里我们挑选了产品表和产品类目表来作为数据源:
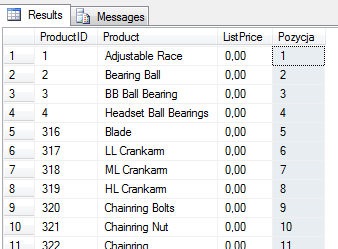
1. 只有 Order by
Use AdventureWorks2008 Go -- działanie ROW_NUMBER() na całym zbiorze SELECT P.ProductID, P.Name Product, P.ListPrice, ROW_NUMBER()OVER(ORDERBY P.ProductID)AS Pozycja FROM Production.Product P |
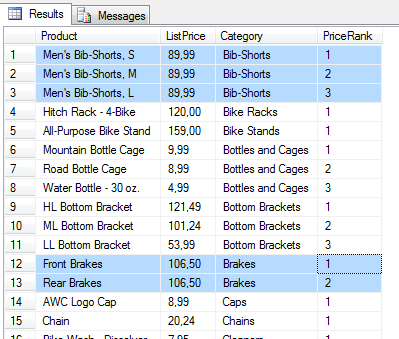
2. 对产品类目进行分区,再根据列表价格进行排序
SELECT P.Name Product, P.ListPrice, PSC.Name Category, ROW_NUMBER()OVER(PARTITION BY PSC.NameORDERBY P.ListPriceDESC)AS PriceRank FROM Production.Product P JOIN Production.ProductSubCategory PSC ON P.ProductSubCategoryID= PSC.ProductSubCategoryID |
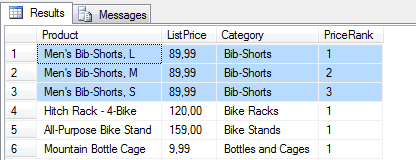
3. 在场景2 的基础上,进一步针对产品名进行排序(默认 ASC)
SELECT P.Name Product, P.ListPrice, PSC.Name Category, ROW_NUMBER()OVER(PARTITION BY PSC.NameORDERBY P.ListPriceDESC , P.Name)AS PriceRank FROM Production.Product P JOIN Production.ProductSubCategory PSC ON P.ProductSubCategoryID= PSC.ProductSubCategoryID |















 276
276

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









