







1、集群搭建
1.1、流程
-
关闭防火墙【讲义第9页】
-
在其中一台机器创建文件夹,并且修改所属主和所属组,在其上安装java,hadoop,然后克隆虚拟机,
-
scp:实现服务器与服务器之间的数据和配置拷贝,当时拷贝的安装包,java和hadoop
-
rsync:主要用于备份和镜像,只对差异文件做更新,而scp是把所有文件都复制过去
-
xsync:集群分发的脚本,循环复制文件到所有节点的相同目录下,可以给集群下的所有机器批量分发文件,用于将环境变量分发过去,需要注意的是环境变量中的文档是root用户才可以编写
所以我们需要使用sudo,但是直接sudo xsync是找不到的,因为加上sudo相当于是root用户了,但是我们把xsync建在了why用户下面,所以这个命令不是系统命令,没法直接sudo xsync使用
所以我们应该把命令的路径给他,sudo /home/why_hadoop/bin/xsync,其中这个命令我们是把他建在了主文件夹下面创建的bin中,这个bin不是home根目录下的bin
-
ssh免密:ssh可以登录另一台主机,通过 ssh ip地址
-
集群部署计划:

-
配置文件:
包括自定义配置文件和默认的四个配置文件
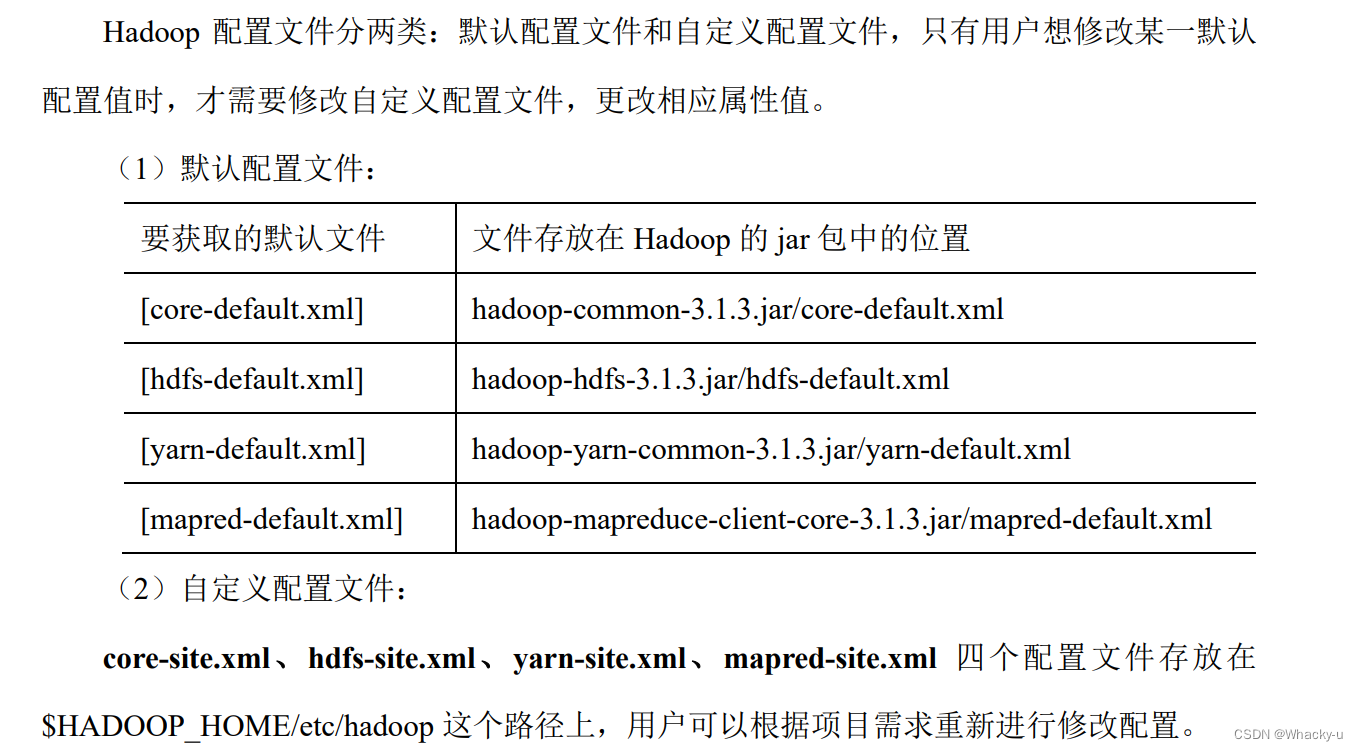
-
配置集群:
配置上述说的几大配置文件(讲义中有详细讲解,23-24页)
流程就是,按照上述第六点的计划,也就是需求,来具体分配配置
-
启动集群之前,需要配置一下workers,集群上有几个节点,就配置几个主机名称
第一次启动的话格式化namenode,之后启动 hdfs,启动yarn
注意是在hadoop103上启动yarn
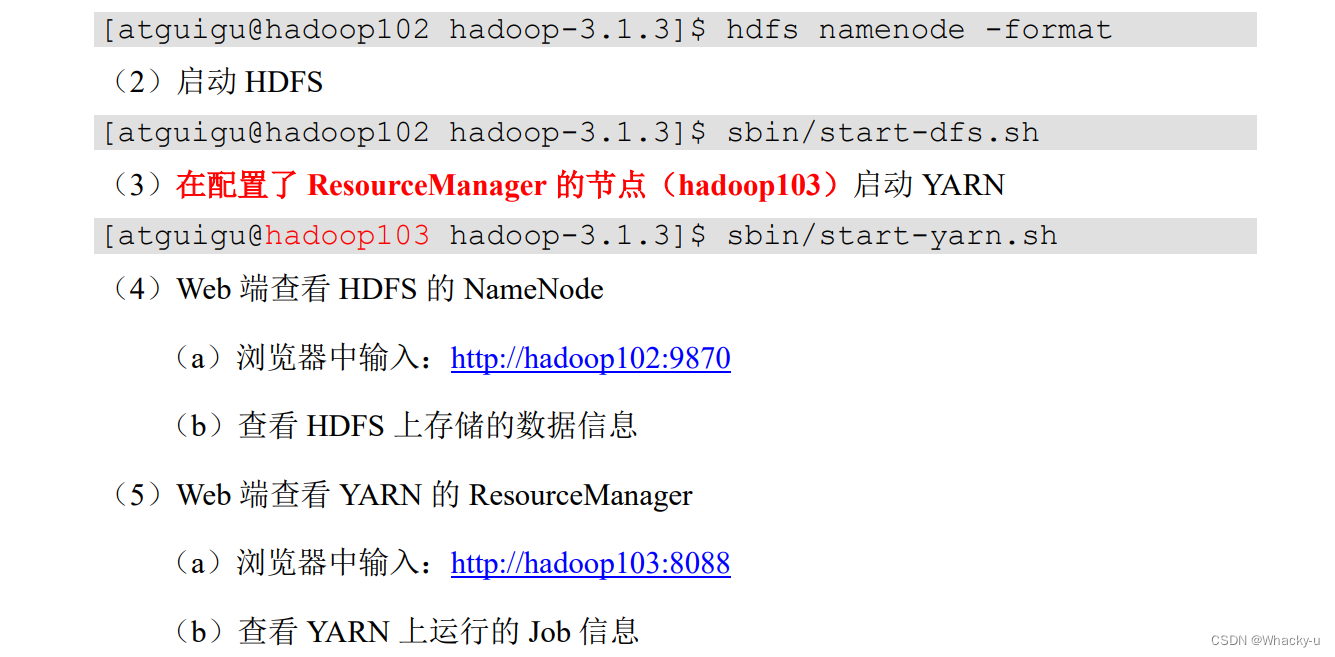
通过jps命令检查节点名称和状态
- hdfs的数据存储位置

-
配置历史服务器【讲义27页】
查看jobhistory: hadoop102:19888
-
配置日志的聚集:日志聚集概念:应用运行完成以后,将程序运行日志信息上传到 HDFS 系统上
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。 注意:开启日志聚集功能,需要重新启动 NodeManager 、ResourceManager 和 HistoryServer。
步骤:
- 配置 yarn-site.xml
- 分发配置
- 关闭 NodeManager 、ResourceManager 和 HistoryServer
- 启动 NodeManager 、ResourceManage 和 HistoryServer
- 删除 HDFS 上已经存在的输出文件
- 执行 WordCount 程序
- 查看日志
-
总结一下:
-
在hadoop102上启动hdfs,和historyserver,在hadoop103上启动yarn
-
Web 端查看 HDFS 的 NameNod:hadoop102:9870
-
Web 端查看 YARN 的 ResourceManager是:hadoop103:8088
-
一般动态的集群使用时候会单独的对组件进行开启和关闭,就是对集群中一台机器中的一个进程进行操作
-

5. **编写统一开启hdfs和yarn的脚本**,其中需要注意主机名和hadoop版本号:**之后可以直接myhadoop.sh start / stop**
6. **编写查看三台服务器 Java 进程脚本**:jpsall
7. 要进入why用户搭建集群,不要进入root用户中
1.2、集群搭建这部分有两个面试题
2.1、常用端口号的说明:
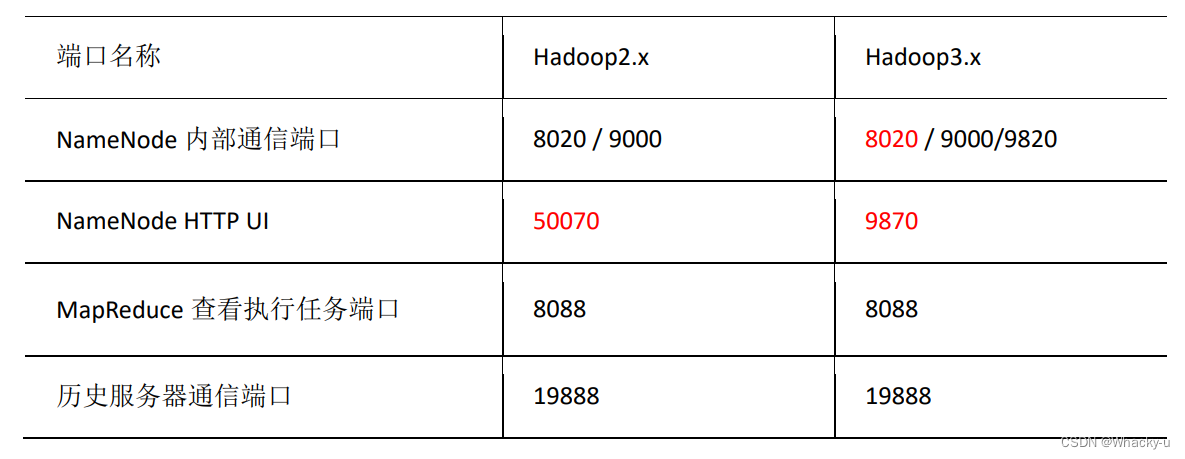
2.2、常用配置文件

1.3、集群时间同步(但没必要)
如果服务器在公网环境(能连接外网),可以不采用集群时间同步,因为服务器会定期 和公网时间进行校准;
如果服务器在内网环境,必须要配置集群时间同步,否则时间久了,会产生时间偏差, 导致集群执行任务时间不同步。
2、HDFS
2.1、HDFS的shell操作(开发重点)
// 具体详细见讲义p4
主要包括三大部分命令:上传、下载、Hdfs直接加载
2.2、HDFS的客户端API
这个主要是为了可以在windows中的HDFS远程客户端代码中,远程连接服务器集群,对其进行数据的增删改查
为了在windows中可以远程连接上这个集群,所以windows中也需要有hadoop的环境变量
// 客户端代码常用套路:
/**
1、获取一个客户端对象
2、执行相关的命令操作
3、关闭资源
**/
注意在maven中写代码,要不记得加上@Test,使用的是Juint,在代码旁边点击按钮运行,要不就是写一个main函数
//参数优先级排序:
(1)客户端代码中设置的值(就是在java文件中定义的configuration) >
(2)ClassPath下的用户自定义配置文件(就是在resource中自己创建的xml中定义的东西) >
(3)然后是服务器的自定义配置(xxx-site.xml) >
(4)服务器的默认配置(xxx-default.xml)
// 这里需要注意的一点,是目标路径如果是win,中间需要转义字符“ \ \ ”,但是如果是hdfs中的则是“/ ”
public class HdfsClient {
private FileSystem fs;
@Before
public void init() throws URISyntaxException, IOException, InterruptedException {
//连接集群的namenode地址
URI uri = new URI("hdfs://hadoop102:8020");
//创建一个配置文件
Configuration configuration = new Configuration();
configuration.set("dfs.replication","2");
//用户
String user = "why_hadoop";
//1、获取到了客户端对象
fs = FileSystem.get(uri,configuration,user);
}
@After
public void close() throws IOException {
//3、关闭资源
fs.close();
}
//创建目录
@Test
public void testmkdir() throws URISyntaxException, IOException, InterruptedException {
//2、创建一个文件夹
fs.mkdirs(new Path("/xiyou/huaguoshan"));
}
//上传
@Test
public void testPut() throws IOException {
// 参数解读:是否删除原数据,是否覆盖,原数据路径win,目的路径HDFS
fs.copyFromLocalFile(false,true,new Path("E:\\Work\\sunwukong.txt"),new Path("/xiyou/huaguoshan"));
}
//下载
@Test
public void testGet() throws IOException {
// 参数解读:原文件是否删除,源文件路径HDFS,目标地址路径win,false表示校验
fs.copyToLocalFile(true,new Path("/xiyou/huaguoshan"),new Path("E:\\Work"),true);
}
//删除
@Test
public void testRm() throws IOException {
// 参数解读:要删除路径,是否递归删除,
// fs.delete(new Path("/jdk-8u212-linux-x64.tar.gz"),false);
//删除空目录
// fs.delete(new Path("/xiyou"),false);
//删除非空目录
//必须要递归删除
fs.delete(new Path("/jinguo"),true);
}
//文件的更名和移动
@Test
public void testmv() throws IOException {
// 参数解读:原文件路径,目标文件路径,
// fs.rename(new Path("/input/word.txt"),new Path("/input/song.txt"));
//文件的移动和更名
// fs.rename(new Path("/input/song.txt"),new Path("/cls.txt"));
//目录的更名
fs.rename(new Path("/input"),new Path("/output1"));
}
//获取文件详细信息
@Test
public void fileDetail() throws IOException {
// 参数解读:原文件路径,是否递归
//这里是一个迭代器,所以写好fs.listFiles后,后面“。var”一下补全代码
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);
//遍历文件
//这么简写:listFiles.hasNext().while
while (listFiles.hasNext()) {
LocatedFileStatus fileStatus = listFiles.next();
System.out.println("======"+fileStatus.getPath()+"=======");
System.out.println(fileStatus.getPermission());
System.out.println(fileStatus.getGroup());
System.out.println(fileStatus.getOwner());
System.out.println(fileStatus.getLen());
System.out.println(fileStatus.getBlockSize());
System.out.println(fileStatus.getPath().getName());
//获取块信息
//fileStatus.getBlockLocations().var
BlockLocation[] blockLocations = fileStatus.getBlockLocations();
System.out.println(Arrays.toString(blockLocations));
}
}
//判断是文件夹还是文件
@Test
public void testFile() throws IOException {
FileStatus[] listStatus = fs.listStatus(new Path("/"));
for (FileStatus status : listStatus) {
if (status.isFile()) {
System.out.println("这是一个文件,"+status.getPath().getName());
}else{
System.out.println("这是一个目录,"+status.getPath().getName());
}
}
}
}
2.3、面试重点:读写流程
详细看讲义
对讲义进行了标注
2.4、NN和2NN(了解)
详细看讲义
对讲义进行了标注
2.5、DataNode工作机制(了解)
详细看讲义
对讲义进行了标注
3、MapReduce
1、mapreduce主要分为两部分:Map阶段和Reduce阶段
2、map阶段的并发MapTask,完全并行运行,互不相干
3、reduce阶段的并发Reduce Task,完全互不相干,但是他们的数据是依赖于上一阶段的所有Map Task并发实例的输出
4、MapReduce编程模型只能包含一个Map阶段和一 个Reduce阶段,如果用户的业务逻辑非常复杂,那 就只能多个MapReduce程序,串行运行
下面是通常情况下的步骤
- map阶段的输入一个键值对,输出也是一个键值对
- map输出的键值对用作reduce阶段的输入键值对,最后还是输出一个键值对kv
- 第三个阶段,Driver阶段,相当于YARN集群的客户端,用于提交我们整个程序到YARN集群,提交的是 封装了MapReduce程序相关运行参数的job对象
可以看讲义,里面有一个wordcount的案例

// 需要注意的是在idea中使用补全代码功能的时候,一定要看清导的包是什么,重名的很多
3.1、序列化
1、概念

如果在传输过程中,key-value涉及到多个字段,一开始最简单的,key是偏移量,value就是简单的名称
但是经过map阶段后,输出的key-value,中value可能有多个字段
这种时候就需要自定义序列化
封装一个类,用来实现序列化
2、实现(举例)
就是多了自定义 bean 对象实现序列化接口(Writable)

3.2、核心框架原理
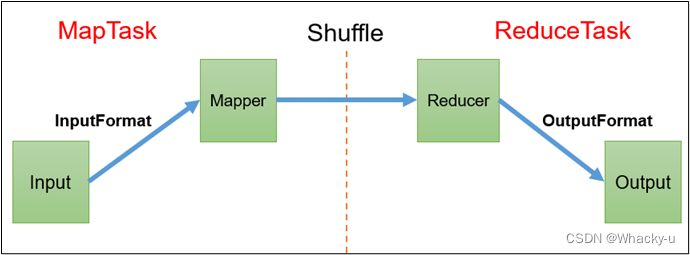
/*
正常来说map阶段输入进来的key是int类型的表示偏移量,v就是输入文件中一行一行的内容
然后reduce的输入就是经过map处理的,比如最简单的wordcount,记录次数,那么key就是数字名字,v就是一个集合<次数,次数>,就全部是1,因为它相当于在中间的shullfe阶段对其中相同key的值进行了一个统计,出现一次,就往其对应的v的集合中加一个1
所以在reduce阶段的代码中,如果对value进行for循环,意思是对key1对应的value集合先进行循环,再去看key2的
但是如果key1对应的value我们再map阶段设置成了NULLwritable,而且其次数还不唯一,那么本来假如是sun <1,1>,但是我们设置成null
就是sun <null,null>,如果在reduce阶段直接context.write,那么就会只记录其出现了一次
【具体的可以见讲义38页在讲output的时候遇到了】
*/
1、InputFormat
- 主要涉及的是切片和MapTask的并行度决定机制
一个切片对应一个MapTask,其中切片是在job提交的过程中完成的,需要注意的是切片的规划是对每一个文件规划一次,而不是考虑数据集整体
- Fileinputfromat 切片具体流程如下所示【但是还有别的切片方法和处理方式,比如combineTextinputformat等】

/**
去看讲义的3.1部分
**/
这里面还介绍了combineTextInputFormat的切片,就是引入一个虚拟存储过程
实际在代码中就是在driver中添加两行代码
// 如果不设置InputFormat,它默认用的是TextInputFormat.class
job.setInputFormatClass(CombineTextInputFormat.class);
//虚拟存储切片最大值设置20m
CombineTextInputFormat.setMaxInputSplitSize(job, 20971520);
2、Shuffle机制
需要注意的是,如果没有reducer就没有数据混洗的过程,就是下面说的shuffle机制
// 是在map之后,reduce之前的数据处理过程
// 在讲义的22页开始
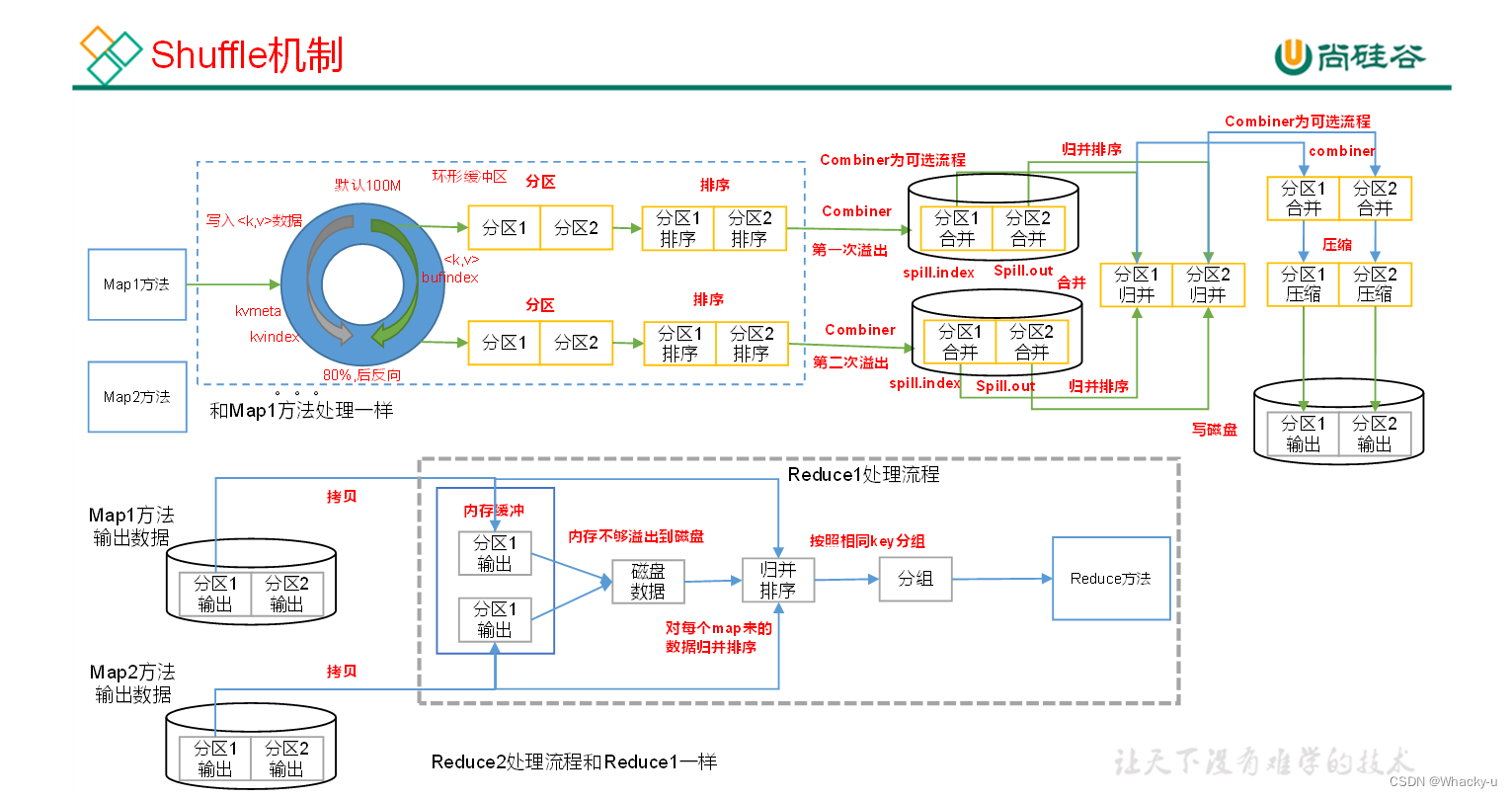
shuffle其实就是在mapper中出来,然后进入环形缓冲区中,对数据进一步的处理,比如排序,编号,从内存到硬盘,从硬盘到内存,合并,压缩等过程
1. 其中主要包括的是partitioner分区,就是选择具体划分给几个reducer //讲义23页-26页
这里主要就是需要单独写一个继承partitioner的类,内容就是重写getPartition
根据需求指定什么情况返回值是几,返回值是几就表明最后哪种情况给分配的reducer是第几个
然后最后在driver中set一下
//8 指定自定义分区器
job.setPartitionerClass(ProvincePartitioner.class);
//9 同时指定相应数量的ReduceTask
job.setNumReduceTasks(5);
2. 以及排序,对分区内的数据进行排序,这里是继承WritableComparable的接口,内部排序 //讲义27页-33页
3. Combiner合并操作 //讲义34页-36页
因为reducer的个数相较mapper的个数要少很多,所以如果数据量很大的情况下
如果执行了combiner操作,那么在mapper阶段相当于对数据进行了整合,最后给reducer的数据就会相对少一些,可以减轻负担
其实其本质也是在mapper阶段,后面再写一个类,继承了reducer然后进行数据的一些整合,需要注意的就是数据的泛型定义【或者方法二,可以看讲义,其实就是利用之前的写好的thing reducer的类】
另外在最后的driver中加一行setcombine巴拉巴拉的就好
// 需要注意的是,combiner不能乱用,前提是不能影响业务逻辑,别如求和可以,但是求平均就不可以,因为数据总量会进行改变
3、OutputFormat数据输出
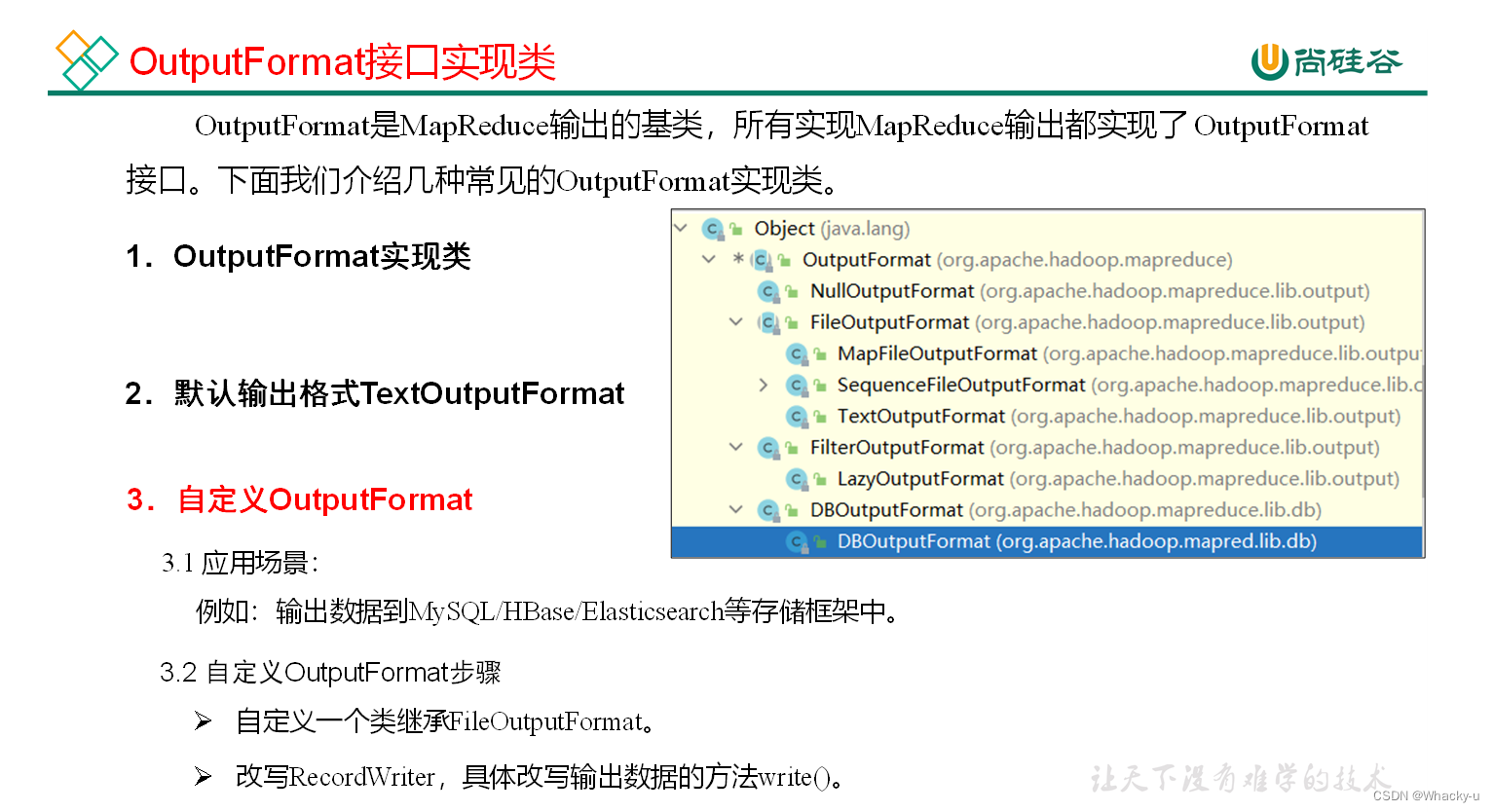
- 自定义一个outputformat类,继承Fileoutputformat
- 里面内容是,重写recordWriter类型的getrecordWriter,在里面实现设置文件的输出流
- 上面重写的那个方法,需要一个recordWriter类型的返回值,那么就需要再写一个类继承recordWriter
- 在继承了recordWriter的类里面重写输出流,需要注意的是里面的抛异常,不要向上抛了,在内部抛异常即可,最后记得关流
- 最后在driver驱动类中setOutputFormatClass
4、Reduce Join
Map端的主要工作:为来自不同表或文件的key/value对,打标签以区别不同来源的记录。然后用连接字段作为key,其余部分和新加的标志作为value,最后进行输出。
Reduce端的主要工作:在Reduce端以连接字段作为key的分组已经完成,我们只需要在每一个分组当中将那些来源于不同文件的记录(在Map阶段已经打标志)分开,最后进行合并就ok了。
// 这里在讲义里的第47页,举例子里面
之所以获取文件名字不是在map函数里面
单独写了一个setup函数,是因为每一个文件只需要获取一次的文件名
如果获取文件名的那个filespilt方法写在了map里面,那就是相当于在读取文件每一行的过程中都会获取一次文件名字
所以我们用的是setup方法【不过这里听疑惑的,估计是源码里知道有这个方法,但是我没注意,所以不知道为什么可以可以直接就去重写setup方法】
//算是一种优化
需要注意的是在这里面,就是reduce部分,想要从value中取值,进行处理,需要注意,这里和java的迭代器不一样
如果直接从for循环中的value中取出来的值,将其赋值给类对象,hadoop这里进行了更改
只是赋给其地址,所以我们需要单独创建一个tmp,将values中for出来的值赋值给那个tmp,再将tmp赋值给最终需要整合的对象里面
5、Map Join
如果合并的操作是在Reduce阶段完成,Reduce端的处理压力太大,Map节点的运算负载则很低,资源利用率不高,且在Reduce阶段极易产生数据倾斜。
因为map task可以有多个,而且每一个map Task的大小都是128左右,但是可以有很多个map Task,所以我们还是希望join的操作是在map阶段
5.1、使用场景
Map Join适用于一张表十分小、一张表很大的场景。
具体的意思是,Map Join适合处理两张表的工作,其中一张是比较小的 ,可以缓存至内存;另外一张特别大的可以用在map Task中
5.2、优点
- 在Map端缓存多张表,提前处理业务逻辑,这样增加Map端业务,减少Reduce端数据的压力,尽可能的减少数据倾斜。
5.3、具体方法**:采用DistributedCache**
(1)在Mapper的setup阶段,将文件读取到缓存集合中。
(2)在Driver驱动类中加载缓存。
//缓存普通文件到Task运行节点。
job.addCacheFile(new URI("file:///e:/cache/pd.txt"));
//如果是集群运行,需要设置HDFS路径
job.addCacheFile(new URI("hdfs://hadoop102:8020/cache/pd.txt"));
====================== 那具体怎么做呢? =====================================================
5.4、思路流程
- 这里主要的问题是两个,一个是数据文件加载到内存,这个是写在驱动类中,就是上面5.3中介绍到的,分两种情况,写下其中一种代码。同时Map端Join的逻辑不需要Reduce阶段,设置reduceTask数量为0
job.setNumReduceTasks(0);
- 另外一个就是在Mapper阶段怎么将文件,读取到缓存集合中,这里主要涉及到的是IO流的知识:
-
通过context从cache中获取加载进去的文件,这里返回的是一个地址集合
//通过缓存文件得到小表数据pd.txt URI[] cacheFiles = context.getCacheFiles(); -
然后我们path一下,获取上面的地址集合中我们想要的,其实也就是path[0]
Path path = new Path(cacheFiles[0]); -
下面需要考虑的就是我们怎么从地址中获取数据,那么就需要创建一个IO流
//获取文件系统对象,并开流 FileSystem fs = FileSystem.get(context.getConfiguration()); FSDataInputStream fis = fs.open(path); -
获取到了流数据后,我们怎么读取呢,这里用到了BufferedReader转换一下
//通过包装流转换为reader,方便按行读取 BufferedReader reader = new BufferedReader(new InputStreamReader(fis,"UTF-8")); -
之后就是逻辑操作
//逐行读取,按行处理 String line; while (StringUtils.isNotEmpty(line = reader.readLine())) { //切割一行 //01 小米 String[] split = line.split("\t"); pdMap.put(split[0], split[1]); } -
最后记得关流
IOUtils.closeStream(reader);
6、数据清洗ETL
在运行核心业务MapReduce程序之前,往往要先对数据进行清洗,清理掉不符合用户要求的数据。清理的过程往往只需要运行Mapper程序,不需要运行Reduce程序。
抽取(Extract)、转换(Transform)、加载(Load)至目的端的过程。ETL一词较常用在数据仓库,但其对象并不限于数据仓库
hadoop只是ETL的工具之一
// 讲义第53页
3.3、MR总结
1、输入数据接口:InputFormat
(1)默认使用的实现类是:TextInputFormat
(2)TextInputFormat的功能逻辑是:一次读一行文本,然后将该行的起始偏移量作为key,行内容作为value返回。
(3)CombineTextInputFormat可以把多个小文件合并成一个切片处理,提高处理效率。
2、逻辑处理接口:Mapper
用户根据业务需求实现其中三个方法:map() setup() cleanup ()
3、Partitioner分区
(1)有默认实现 HashPartitioner,逻辑是根据key的哈希值和numReduces来返回一个分区号;key.hashCode()&Integer.MAXVALUE % numReduces
(2)如果业务上有特别的需求,可以自定义分区。
4、Comparable排序
(1)当我们用自定义的对象作为key来输出时,就必须要实现WritableComparable接口,重写其中的compareTo()方法。
(2)部分排序:对最终输出的每一个文件进行内部排序。
(3)全排序:对所有数据进行排序,通常只有一个Reduce。
(4)二次排序:排序的条件有两个。
5、Combiner合并
Combiner合并可以提高程序执行效率,减少IO传输。但是使用时必须不能影响原有的业务处理结果。
6、逻辑处理接口:Reducer
用户根据业务需求实现其中三个方法:reduce() setup() cleanup ()
7、输出数据接口:OutputFormat
(1)默认实现类是TextOutputFormat,功能逻辑是:将每一个KV对,向目标文本文件输出一行。
(2)用户还可以自定义OutputFormat。
4、Hadoop数据压缩
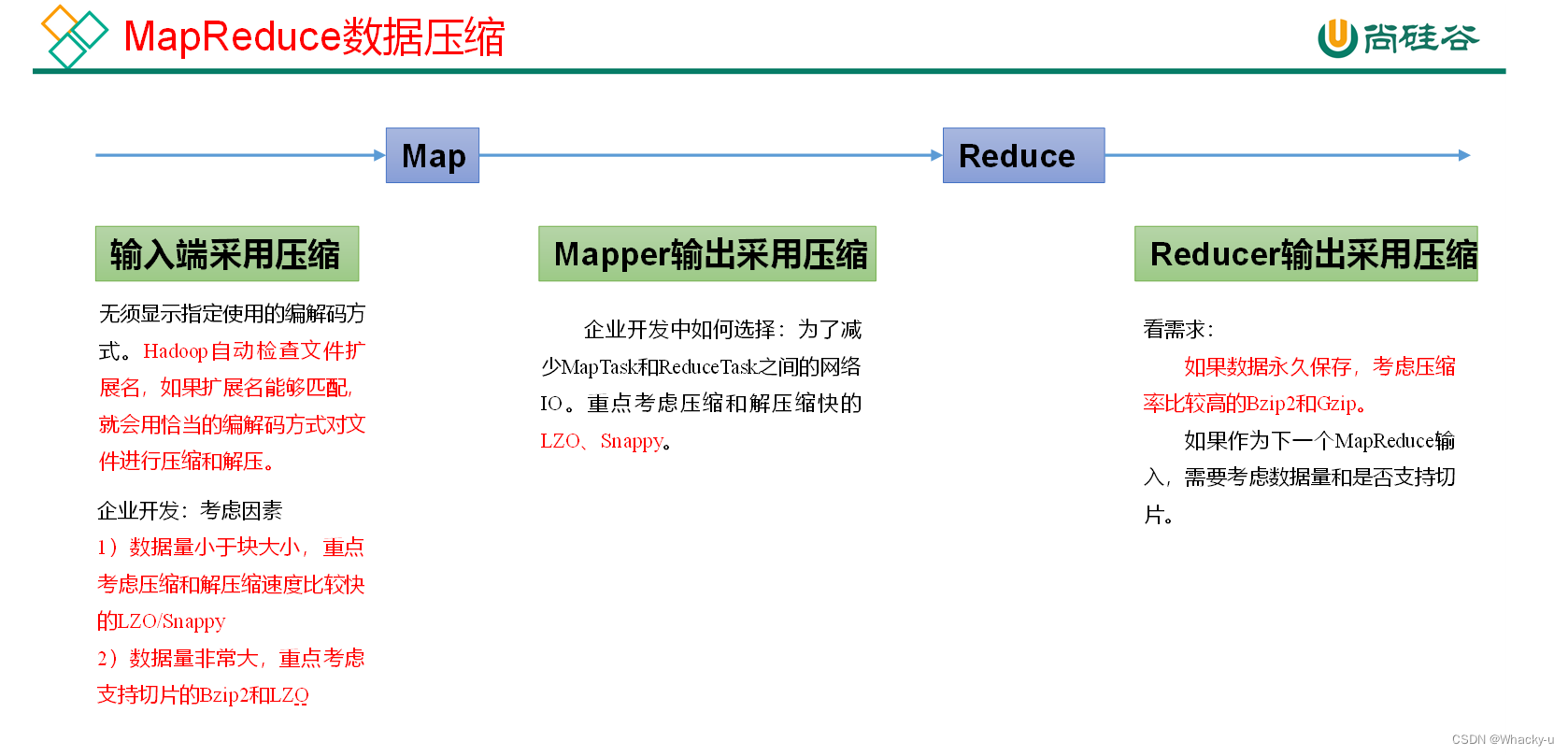
// 重点看讲义56页之后
主要涉及到的就是上面图中的三个位置
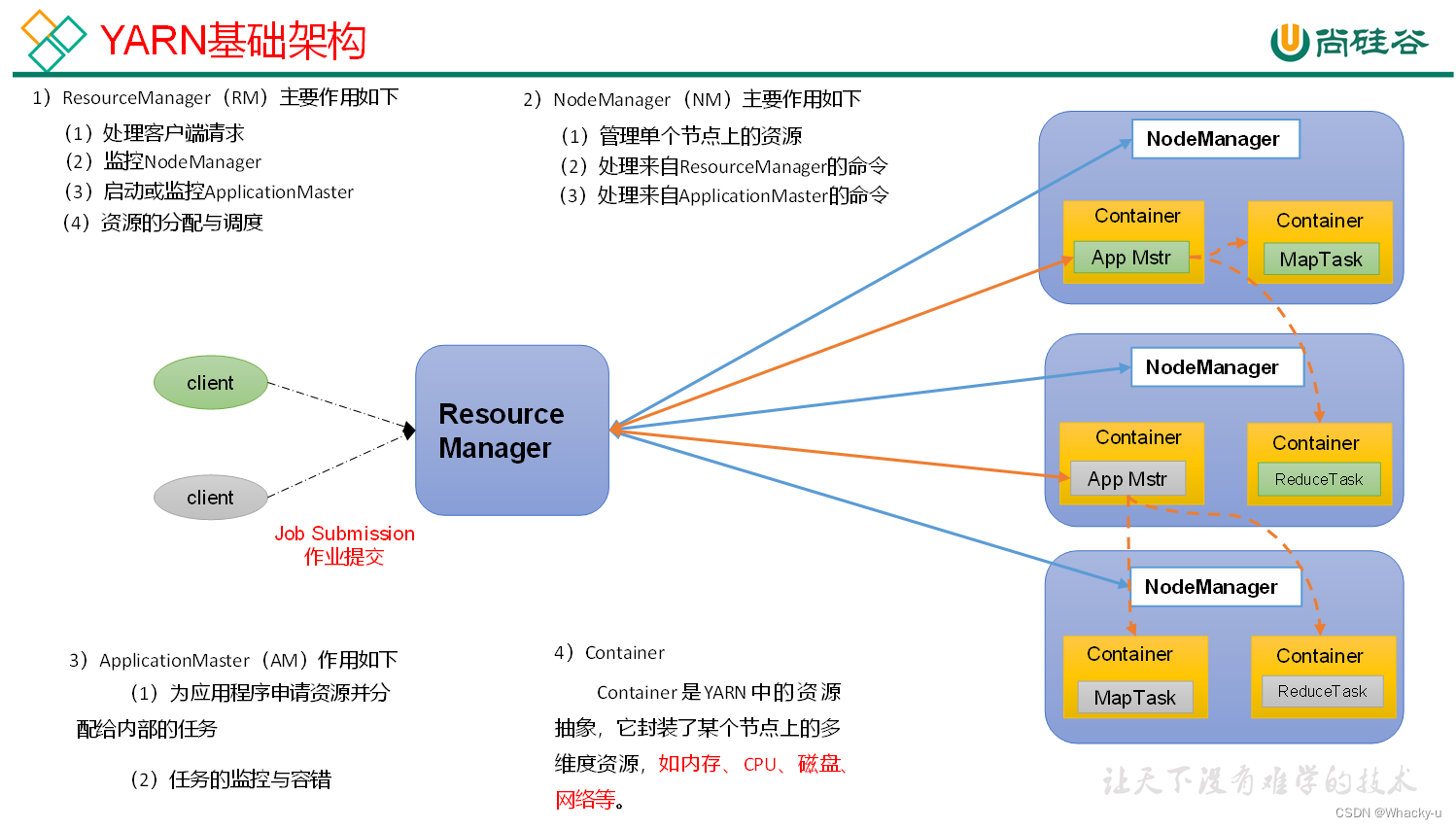
5、Yarn
YARN主要由ResourceManager、NodeManager、ApplicationMaster和Container等组件构成。
主要是负责资源调度的
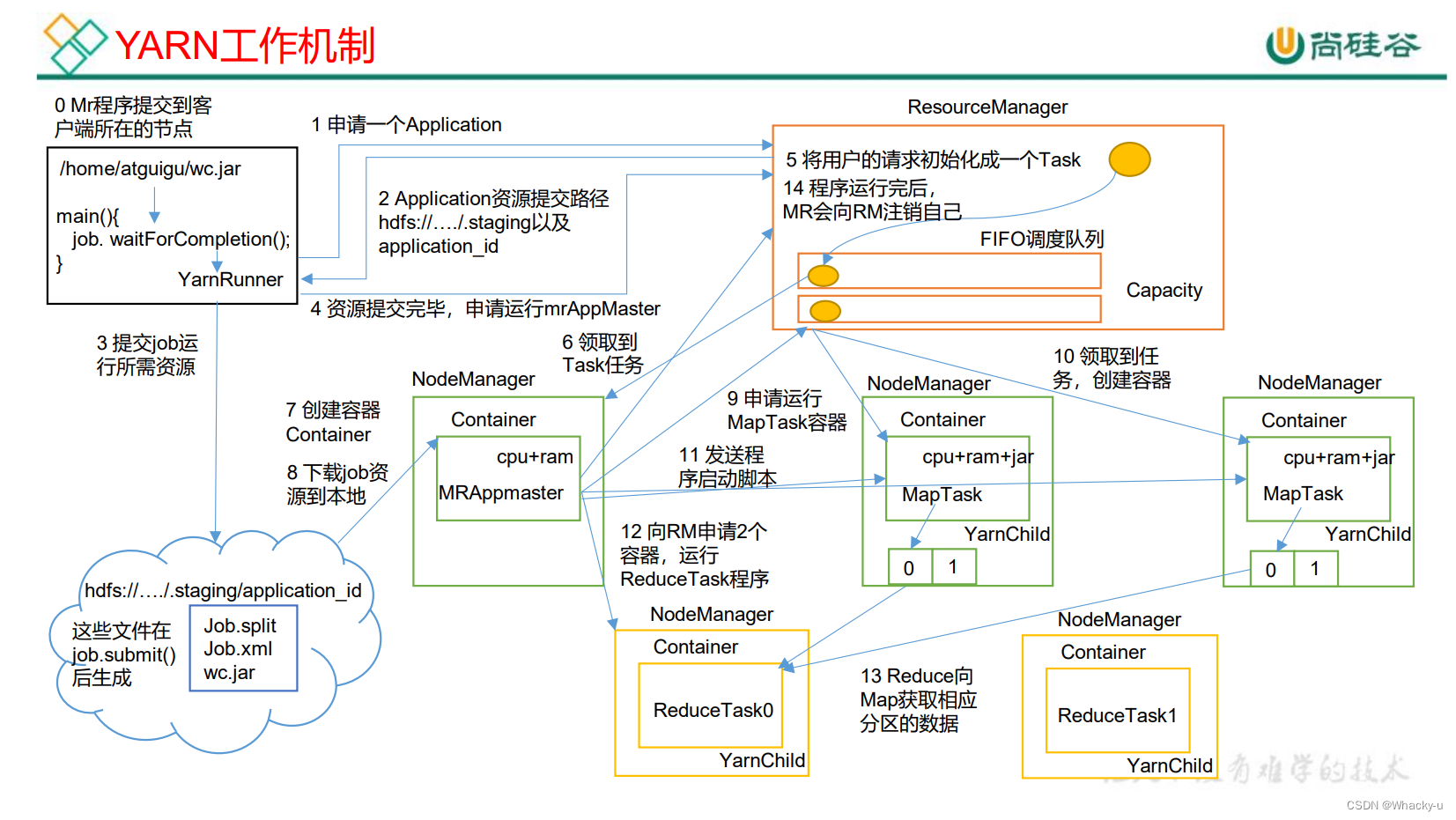
5.1、基础架构 & 工作机制
5.2、Yarn调度器和调度算法【重点搞清原理】
目前,Apache Hadoop3.1.3默认的资源调度器是Capacity Scheduler(容量调度器)。
Hadoop作业调度器主要有三种:
- FIFO
- 容量(Capacity Scheduler)
- 公平(Fair Scheduler)。
CDH框架默认调度器是Fair Scheduler(公平调度器)。
其中FIFO先进先出不适合大数据中的高并发,所以只是用作引入了解
重点学习掌握容量和公平两个调度器
// 重点看讲义第6页到第10页
是面试重点,也是理论基础
容量调度器的特点,公平调度器的特点
两个共同之处是多队列、容量保证、灵活性、多租户
//不同之处是容量调度器优先选择资源利用率第低的队列、但是公平调度器优先选择对资源缺额比较大【这里就需要重点看一下缺额是什么】
//另外两种调度器每个队列的设置的资源分配方式也不一样,公平调度多了一个Fair策略
除了特点需要明白,还需要明白两种调度器的:
资源分配方式 //三个维度:针对队列、作业、容器
资源分配算法
5.3、Yarn命令
// 主要见讲义的第10页到12页
- yarn application查看任务
- yarn logs查看日志
- yarn applicationattempt查看尝试运行的任务
- yarn container查看容器
- yarn node查看节点状态
- yarn rmadmin更新配置
- yarn queue查看队列
5.4、Yarn生产环境核心参数【非常重要】
如果对并发度要求比较高,那么选择公平调度器
如果并不是很高,那就是容量调度器,Apache默认就是容量调度器
下图中的参数在实际生产中是必须要注意和配置的,因为默认的配置很有可能会与我们的集群设配不符合
如果不进行配置,那么很容易造成集群崩掉
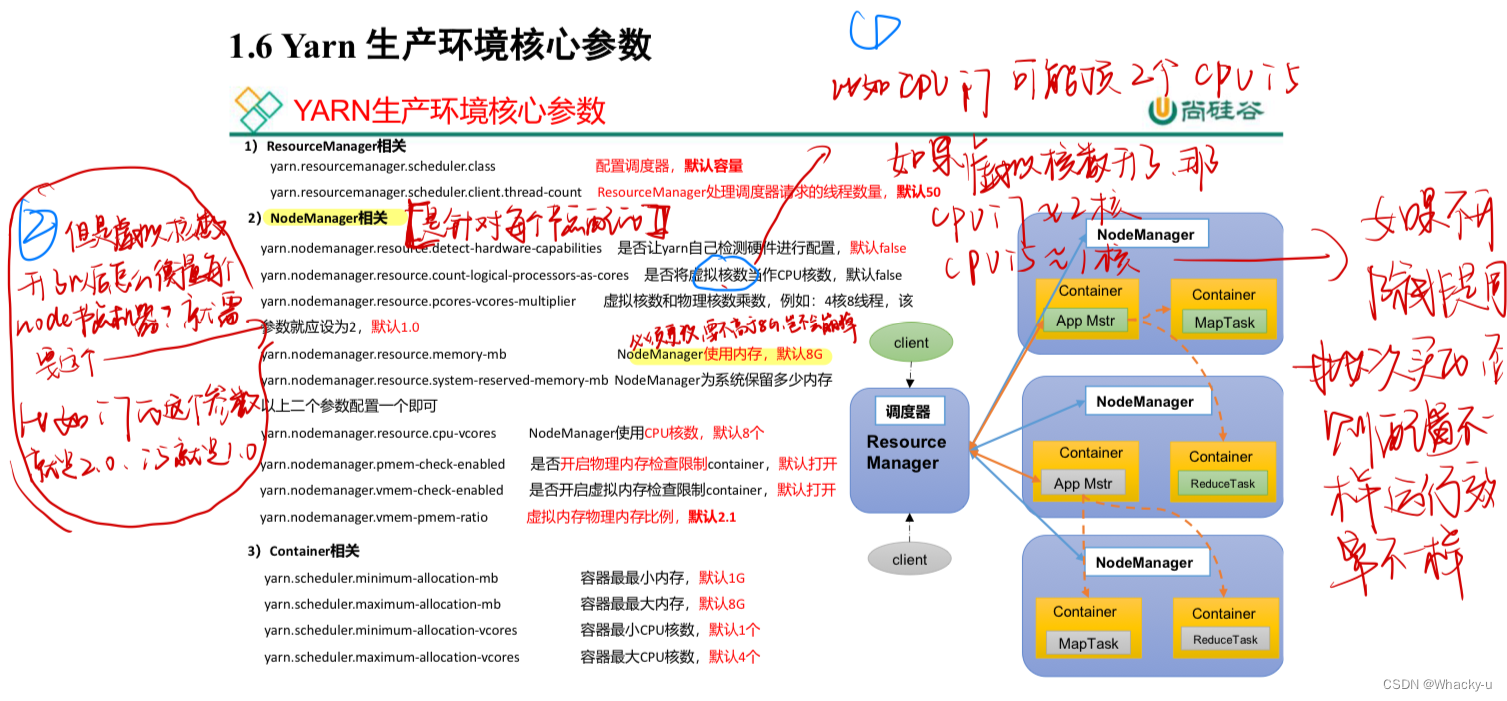
// 也可以看讲义13页-16页的实例进行巩固理解
这里的例子讲解了怎么根据实际的需求去具体的更改配置
注:调整下列参数之前尽量拍摄Linux快照,否则后续的案例,还需要重写准备集群。
5.5、容量调度器的多队列
1)在生产环境怎么创建队列?
- 调度器默认就1个default队列,不能满足生产要求。
- 按照框架:hive /spark/ flink 每个框架的任务放入指定的队列(企业用的不是特别多)
- 按照业务模块:登录注册、购物车、下单、业务部门1、业务部门2
2)创建多队列的好处?
-
因为担心员工不小心,写递归死循环代码,把所有资源全部耗尽。
-
实现任务的降级使用,特殊时期保证重要的任务队列资源充足。11.11 6.18
-
业务部门1(重要)=》业务部门2(比较重要)=》下单(一般)=》购物车(一般)=》登录注册(次要)
// 具体怎么设置多队列以及配置使用哪个队列,因为默认是default队列
// 可以见讲义17-19页
// 优先级配置的例子在讲义第20页
一般默认是没有设置优先级,都是0
需要在yarn-site文件里面配置一下
5.6、公平调度器案例
// 一般用作中大型公司
//见讲义21页例子
5.7 Tool接口
在想要给mapreduce程序分配队列时候,我们命令行里面并不是只有输入路径,输出路径
还会有个选择哪个资源队列的参数
这时候如果不设置Tool接口,那么系统会默认第一个参数,就是上面选择哪个资源队列的参数为输入路径了
这就是问题所在
-
我们在写mapreduce的流程需要更改一些:写map和reduce的时候变成内部类
-
我们需要单独写一个类,实现了接口Tool,在里面重写run等三个核心驱动方法,并且map和reduce写在里面的内部类
【就是public static class mapper ,reducer等】
这里面的conf不是new出来的,是之后有一个专门的驱动类里面的Torunner给他传进来
所以这里面我们只要写好getConf,setConf,和run,假设我们现在已经取得了conf信息了
public class WordCount implements Tool { private Configuration conf; //核心驱动(conf需要传入) @Override public int run(String[] args) throws Exception { Job job = Job.getInstance(conf); job.setJarByClass(WordCountDriver.class); job.setMapperClass(WordCountMapper.class); job.setReducerClass(WordCountReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); return job.waitForCompletion(true) ? 0 : 1; } @Override public void setConf(Configuration configuration) { this.conf = conf; } @Override public Configuration getConf() { return conf; } //mapper ... //reducer ... } } -
另外驱动类也需要更改一下
public class WordCountDriver { private static Tool tool; public static void main(String[] args) throws Exception { // 1. 创建配置文件 Configuration conf = new Configuration(); // 2. 判断是否有tool接口 switch (args[0]){ case "wordcount": tool = new WordCount(); //这里是判断集群中的命令行第一个参数是什么,如果是yarn命令, //就执行上面定义的方法 break; default: throw new RuntimeException(" No such tool: "+ args[0] ); } // 3. 用Tool执行程序 // Arrays.copyOfRange 将老数组的元素放到新数组里面 int run = ToolRunner.run(conf, tool, Arrays.copyOfRange(args, 1, args.length)); System.exit(run); } }5.8、总结
// 1. 创建配置文件 Configuration conf = new Configuration();
// 2. 判断是否有tool接口 switch (args[0]){ case "wordcount": tool = new WordCount(); //这里是判断集群中的命令行第一个参数是什么,如果是yarn命令, //就执行上面定义的方法 break; default: throw new RuntimeException(" No such tool: "+ args[0] ); } // 3. 用Tool执行程序 // Arrays.copyOfRange 将老数组的元素放到新数组里面 int run = ToolRunner.run(conf, tool, Arrays.copyOfRange(args, 1, args.length)); System.exit(run); }}
## 5.8、总结
















 2093
2093











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









