







数据库执行DQL语句不会对数据进行改变,而是让数据库发送结果集给客户端
结果集
通过查询语句查询出来的数据以表的形式展示我们称为虚拟结果集,存放在内存中。
查询返回的结果是一张虚拟表
查询所有列
SELECT * FROM 表名;
查询指定列的数据
SELECT 列名1,列名2... FROM 表名;
SELECT id,stu_age FROM student;
条件查询
条件查询就是在查询时给出 WHERE 子句,在WHERE子句中使用一些运算符及关键字。
运算符及关键字
= 等于, != 不等于 ,<> 不等于, < 小于, <= 小于等于, > 大于, >= 大于等于
SELECT * FROM student WHERE stu_gender != '男';
SELECT * from student WHERE stu_age>=5 and stu_age<=30;
BETWEEN...AND...; 值在什么范围
SELECT * FROM student WHERE stu_age BETWEEN 5 and 30;
IN(set): set为固定的范围值
SELECT * from student WHERE id in(1001,1002,1003);
IS NULL; 为空 IS NOT NULL 不为空
SELECT * FROM student WHERE id IS NULL;
SELECT * FROM student WHERE id IS NOT NULL;
AND 与
SELECT * FROM student WHERE stu_gender='男' AND stu_age=40;
OR 或
SELECT * FROM student WHERE id=1001 or id=1002 or id=1003;
NOT 非
模糊查询
根据关键字进行查询
使用 LIKE 关键字后跟通配符
通配符
_ 任意一个字母,表示单个字符,不一定是字母,可以是单个汉字
%任意0-n 个字母
查询姓名由5个字母构成的学生记录 (5个下划线)
SELECT * FROM student where stu_name LIKE '_____';
查询姓名由5个字母构成,并且第5个字母为 ‘s’的学生记录 (4个下滑线 + s)
SELECT * FROM student where stu_name LIKE '____s';
查询以 ‘m’ 开头的学生记录
SELECT * FROM student where stu_name LIKE 'm%';
查询姓名中第二个字母为’u’ 的记录
SELECT * FROM student where stu_name LIKE '_u%';
查找姓名中包含 ‘s’ 字母的学生记录
SELECT * FROM student where stu_name LIKE '%s%';
字段控制查询
某个字段有重复值,查询时去除重复
SELECT DISTINCT stu_name from student;
两个字段(列)对应项相加,并生成一个新的字段(列), 新的字段是临时的,并没有存储
SELECT *,stu_age+stu_score FROM student;

如上补充: 将结果为null的,变成0, 思想是变成数值运算
IFNULL 如果 stu_age 是null, 那个为0
SELECT *,IFNULL(stu_age,0)+IFNULL(stu_score,0) FROM student;

生成的字段名称 更改成其他名称,
SELECT *,IFNULL(stu_age,0)+IFNULL(stu_score,0) AS total FROM student;

AS 也可给查询的字段起别名
SELECT stu_name AS renames FROM student;
对查出来的结果及性能排序
使用关键字 OPDER BY
SELECT * FROM employee ORDER BY salary; ## 默认升序排序
ASC 升序,从小到大,默认
DESC 降序,从大到小
SELECT * FROM employee ORDER BY salary ASC;
SELECT * FROM employee ORDER BY salary DESC;
工资进行降序之后,id 再进行降序
SELECT * FROM employee ORDER BY salary DESC,id DESC;
聚合函数
对查询结果进行统计
count() 统计指定列不为NULL的记录行数
统计表中的记录数
SELECT COUNT(*) FROM employee;
统计月薪大于2500的人数
SELECT count(*) FROM employee WHERE salary>2500;
统计月薪和绩效之和大于5000的人数
SELECT count(*) FROM employee
where IFNULL(salary,0)+IFNULL(performance,0) > 5000;
统计不同字段的人数
SELECT COUNT(performance),COUNT(manage) FROM employee;
max() 计算指定列的最大值,如果指定列是字符串类型,那么使用字符串排序运算
SELECT MAX(salary) from employee;
min() 计算指定列的最小值,如果指定列是字符串类型,那么使用字符串排序运算
SELECT MIN(salary) from employee;
sum() 计算指定列的数值和,如果指定列不是数值类型,那么计算结果为0
SELECT sum(salary) from employee; #单字段求和
SELECT sum(salary),sum(performance) from employee; #多字段求和
SELECT sum(salary + IFNULL(performance,0)) from employee; #有效非空字段相加 再求和
avg() 计算指定列的平均值,如果指定列不是数值类型,那么计算结果为0
SELECT AVG(salary) from employee;
分组查询
GROUP BY
将查询结果按照1个或多个字段进行分组,字段值相同的为一组
SELECT * FROM employee
GROUP BY gender;
此用法只显示分组的第一条记录

一般来说,在使用分组时,select 后面直接跟的字段一般都出现在 group by 后
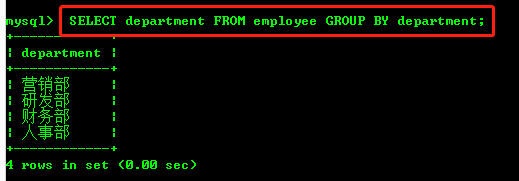
部门分组, 与去重是有区别的
SELECT department FROM employee
GROUP BY department;
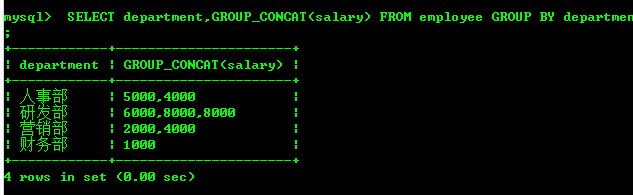
查看每一组中的内容 GROUP_CONCAT()
SELECT department,GROUP_CONCAT(`name`) FROM employee
GROUP BY department;

SELECT department,GROUP_CONCAT(salary) FROM employee
GROUP BY department;
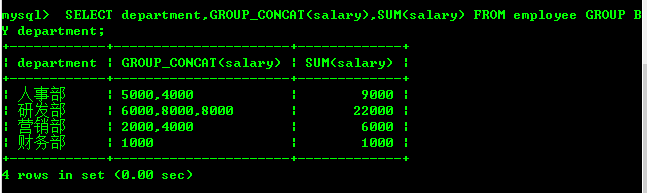
部门分组的薪资进行求和
SELECT department,GROUP_CONCAT(salary),SUM(salary) FROM employee
GROUP BY department;
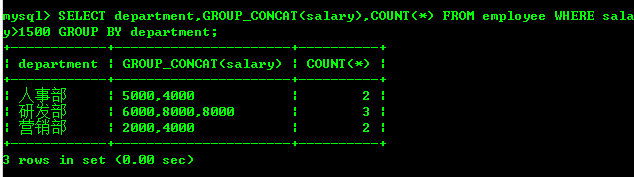
查询每个部门的名称 及每个部门工资大于1500的人数
SELECT department,GROUP_CONCAT(salary),COUNT(*) FROM employee
WHERE salary>1500
GROUP BY department;
#等价于
SELECT department,GROUP_CONCAT(salary),COUNT(salary)
FROM employee WHERE salary>1500
GROUP BY department;
where是分组之前进行筛选数据
having 是分组之后进行筛选,having后可使用聚合函数
分组查询后指定一些条件输出查询结果 having
having 在 where 之后
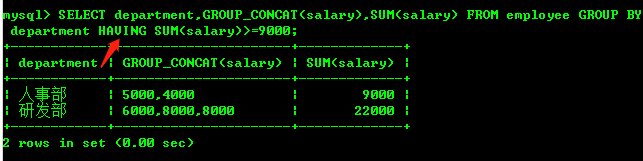
查询工资总和大于9000的部门名称以及工资和
SELECT department,GROUP_CONCAT(salary),SUM(salary) FROM employee
GROUP BY department
HAVING SUM(salary)>=9000;
having 前

having 后
练习:查询工资大于2000的,工资总和大于9000的部门名称及工资和
SELECT department,GROUP_CONCAT(salary),SUM(salary) from employee
where salary>2000
GROUP BY department
having SUM(salary)>6000
ORDER BY SUM(salary) DESC;
从哪行开始查,要查多少行 limit
limit 参数1,参数2, 脚标默认从0开始
参数1 开始行的脚标
参数2 总共要查询的行数
查看 前 3 行的数据
SELECT * FROM employee LIMIT 0,3; #前三行
SELECT * FROM employee LIMIT 3,3; # 第四行到第六行

网站分页调用数据库思想
int curPage = 1; #当前页
int pageSize = 3; #每页展示多少条数据
#当前页为1第一页从0开始,(1-1)*3 = 0
#当前页为2第一页从3开始,(1-1)*3 = 3
#当前页为3第一页从6开始,(1-1)*3 = 6
#当前页为4第一页从9开始,(1-1)*3 = 9
SELECT * FROM employee LIMIT (curPage-1)*pageSize,pageSize;
使用的例子,创建表
CREATE TABLE employee (
id INT(11) NOT NULL ,
name VARCHAR(50) DEFAULT NULL,
gender VARCHAR(1) DEFAULT NULL,
hire_date date DEFAULT NULL,
salary decimal(10,0) DEFAULT NULL,
performance double(255,0) DEFAULT NULL,
manage DOUBLE(255,0) DEFAULT NULL,
department VARCHAR(255) DEFAULT NULL
)ENGINE INNODB DEFAULT CHARSET=utf8;
INSERT INTO employee values
(1001,'张三','男','1991-07-25',2000,200,500,'营销部'),
(1002,'李四','男','2017-07-05',4000,500,NULL,'营销部'),
(1003,'王五','女','2018-05-01',6000,100,NULL,'研发部');
(1004,'赵六','男','1991-06-01',1000,1000,4000,'财务部'),
(1005,'孙七','女','2018-03-23',8000,1000,NULL,'研发部'),
(1006,'马八','男','2010-09-08',5000,500,1000,'人事部'),
(1007,'吴九','女','2017-07-05',8000,600,NULL,'研发部'),
(1008,'郑十','男','2014-04-06',4000,1800,NULL,'人事部');

查询Timestamp时间截
SELECT * from t_order_info
where DATE_FORMAT(create_time,'%Y-%m-%d')>= '2019-06-18' AND DATE_FORMAT(create_time,'%Y-%m-%d')<= '2019-06-18';
















 229
229











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









