






“堆”排序
叠罗汉大家都知道吧,就是把人堆在一起,而这里我们要介绍的“堆”结构相当于把数字堆成一个塔型的结构。如图:
很明显,我们可以发现它们都是 二叉树,如果观察仔细些,还能看出它们都是 完全二叉树。上图中根节点是所有元素中最大的,右图的根节点是所有元素中最小的。再仔细看看,发现左图每个节点都比它的左右孩子要大,右图每个节点都比它的左右孩子要小。这就是我们要讲的堆结构。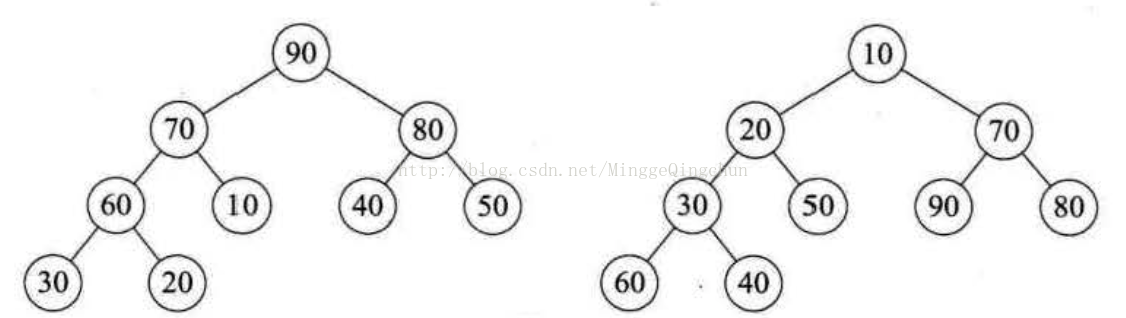
堆 是具有下列性质的完全二叉树:每个节点的值都大于或等于其左右孩子节点的值,称为大顶堆;或者每个节点的值都小于或等于其左右孩子结点的值称为小顶堆。
这里我们需要注意从堆的定义可知,根节点一定是堆中所有节点最大(小)者。较大(小)的结点靠近根节点(但也不绝对,比如右图小顶堆中60、40均小于70,但它们并没有70靠近根节点)。
按照层序遍历的方式给结点从1开始编号,则结点之间满足如下关系:
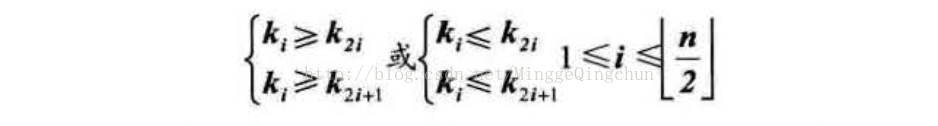
上图的解释如下 完全二叉树的性质 :
i 编号的结点是非叶子结点, 如果i=1 (编号从1开始) , 则结点i是二叉树的根,无双亲;如果i>1,则其双亲是结点[i/2]。那么对于有n个结点的二叉树而言,它的i值自然就是小于等于[n/2]了。
堆排序算法
堆排序(Heap Sort) 就是利用堆(假设利用大堆顶)进行排序的方法。它的基本思想是,将待排序的序列构成一个大顶堆。此时,整个序列的最大值就是堆顶的根节点。将它移走(其实就是将其与堆数组的末尾元素交换,此时末尾元素就是最大值),然后将剩余的n-1个序列重新构造成一个堆,这样就会得到n个元素中的次小值。如此反复执行,便能得到一个有序序列了。
例如下图所示,图①是一个大堆顶,90为最大值,将90与20(末尾元素)互换,如图②所示,此时90就成了整个堆序列的最后一个元素,将20经过调整,使得除90以外的结点都继续满足大顶堆定义(所有结点都大于等于其子孩子),见图③,然后再考虑将30与80互换......


这里大家有些明白堆排序的思想了,不过要实现它还需要解决两个问题:
- 如何由一个无序序列构建成一个堆?
- 如果再输出堆顶元素后,调整剩余元素为一个新的堆?
堆排序代码:
- (void)heapSort:(NSMutableArray *)list { NSInteger i ,size; size = list.count; //找出最大的元素放到堆顶 for (i= list.count/2; i>=0; i--) { [self createBiggesHeap:list withSize:size beIndex:i]; } while(size > 0){ [list exchangeObjectAtIndex:size-1 withObjectAtIndex:0]; //将根(最大) 与数组最末交换 size -- ;//树大小减小 [self createBiggesHeap:list withSize:size beIndex:0]; } NSLog(@"%@",list); } - (void)createBiggesHeap:(NSMutableArray *)list withSize:(NSInteger) size beIndex:(NSInteger)element { NSInteger lchild = element *2 + 1,rchild = lchild+1; //左右子树 while (rchild < size) { //子树均在范围内 if (list[element]>=list[lchild] && list[element]>=list[rchild]) return; //如果比左右子树都大,完成整理 if (list[lchild] > list[rchild]) { //如果左边最大 [list exchangeObjectAtIndex:element withObjectAtIndex:lchild]; //把左面的提到上面 element = lchild; //循环时整理子树 }else{//否则右面最大 [list exchangeObjectAtIndex:element withObjectAtIndex:rchild]; element = rchild; } lchild = element * 2 +1; rchild = lchild + 1; //重新计算子树位置 } //只有左子树且子树大于自己 if (lchild < size && list[lchild] > list[element]) { [list exchangeObjectAtIndex:lchild withObjectAtIndex:element]; } }从代码中可以看出,整个排序过程分为两个循环,第一个循环要完成的就是将现在的待排序序列构建成一个大顶堆。第二个循环要完成的就是逐步将每个最大值的根节点与末尾元素交换,并再调整其成为一个大顶堆。
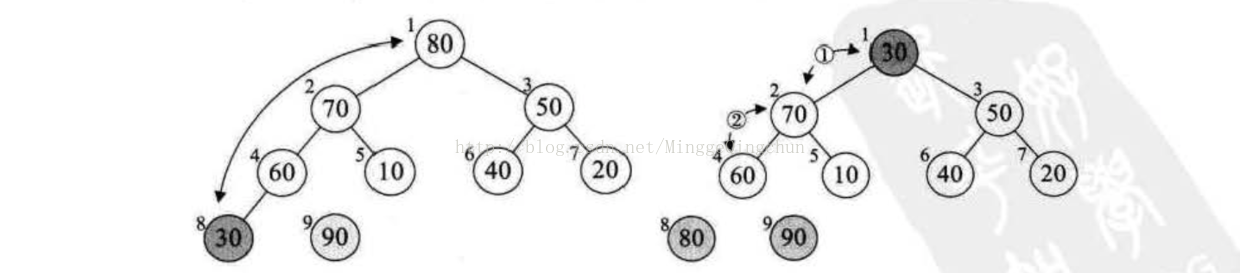
假设我们要排序的序列是(50,10,90,30,70,40,80,60,20)。共9个,那么第一次调整底的位置是从9/2 = 4开始,4->3->2->1的变量变化,为什么不是从1到9或者9到1,而是从4到1呢,看下图就明白了,它们有什么规律?它们都是有孩子的结点。注意灰色结点的下表编号就是1、2、3、4.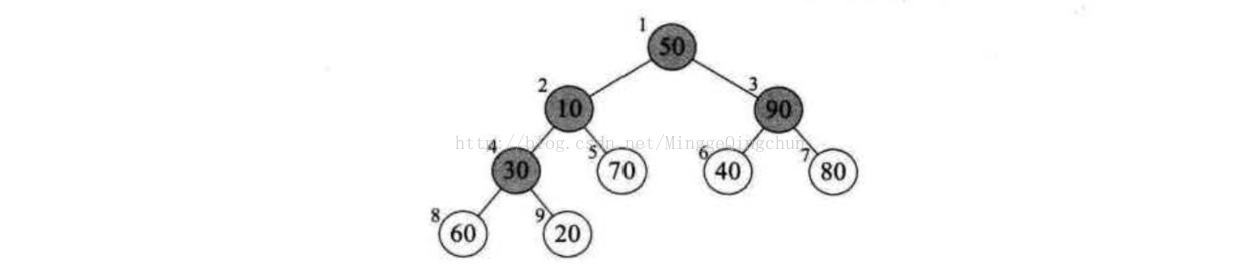
我们所谓的将待排序的序列构建成为一个大顶堆坑,其实就是从下往上、从右到左,将每个非终端节点(非叶结点)当作根节点,将其和其子树调整为大顶堆,i的4->3->2->1的变量变化,其实也就是30、90、10、50的结点调整过程。调整方式便是与自己的左右子树的对比,大的交换位置到堆顶,按次序最终取得最大值。示例图如下:
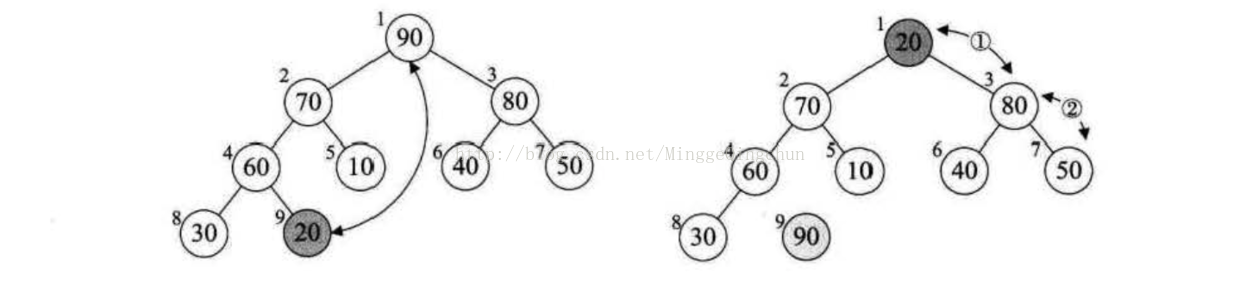
动效图如下:

解释:
1、 从下往上,从右往左的顺序查找每个非叶子结点,对比子结点,与最大结点交换位置,交换的新位置再与其子结点比较、移动,遍历后最终找到最大值。
2、把堆顶和最后的元素交换位置,排除最后的位置,重复1步骤,找到遍历后的最大值,放到倒数第二的位置,依次直到结束。堆排序复杂度分析:
堆排序运行时间主要是消耗在初始构建堆和在重建堆时的反复筛选上。在构建堆的过程中,对每个终端节点最多进行两次比较操作,因此整个排序堆的时间复杂度为O(n)。
在正式排序时,第i次取堆顶记录重建堆需要用O(logi)的时间,并需要取n-1次堆顶记录,因此总体来说,堆排序的时间复杂度为O(nlogn)。由于堆排序对原始数据的排序状态并不敏感,因此它无论是最好、最坏和平均时间复杂度均为O(nlogn)。在这性能上显然要远远好过于冒泡、选择、插入的O(n²)的时间复杂度了。
空间复杂度上,它只有一个用来交换的暂存单元,也是非常不错。不过由于记录的比较和交换是跳跃式进行,因此堆排序也是一种不稳定的排序方法。
另外,由于初始构建堆排序需要的比较次数较多,因此,它不适合待排序序列个数较少的情况。
作者:方圆一里
链接:http://www.jianshu.com/p/fe271bc3e544
來源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
iOS算法总结-堆排序
最新推荐文章于 2019-08-25 16:01:54 发布
















 529
529

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









