







是个apk文件,用jadx打开,找到MainActivity
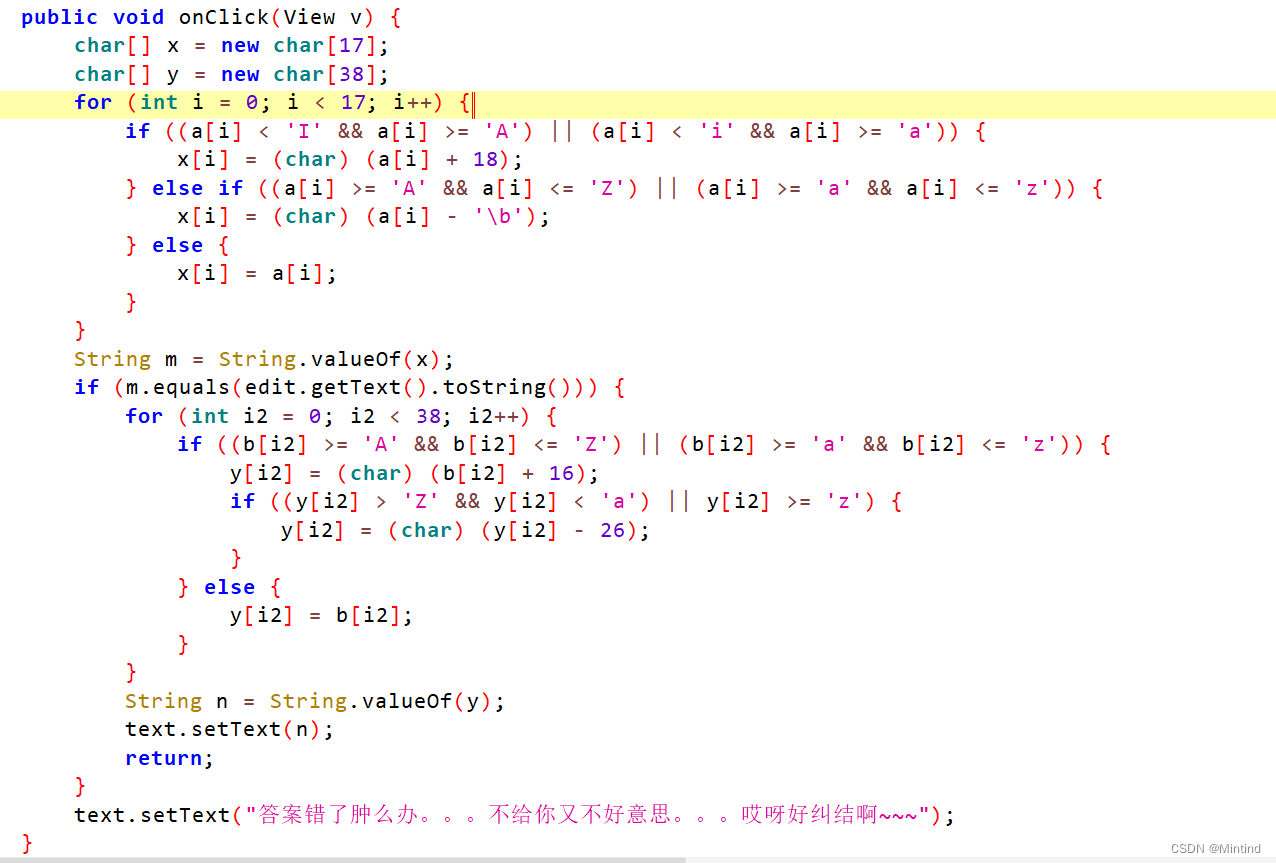 大概逻辑是,由给定的a数组得到x数组,用户输入和x相等时会输出flag——由给定的b数组得到的y数组,不相等则输出提示
大概逻辑是,由给定的a数组得到x数组,用户输入和x相等时会输出flag——由给定的b数组得到的y数组,不相等则输出提示
总之东西都给了,稍微转换一下运行就能得到flag
char a[] = {'T', 'h', 'i', 's', 'I', 's', 'T', 'h', 'e', 'F', 'l', 'a', 'g', 'H', 'o', 'm', 'e'};
char b[] = {'p', 'v', 'k', 'q', '{', 'm', '1', '6', '4', '6', '7', '5', '2', '6', '2', '0', '3',
'3', 'l', '4', 'm', '4', '9', 'l', 'n', 'p', '7', 'p', '9', 'm', 'n', 'k', '2', '8', 'k',
'7', '5', '}'};
char x[17];
char y[38];
for (int i = 0; i < 17; i++) {
if ((a[i] < 'I' && a[i] >= 'A') || (a[i] < 'i' && a[i] >= 'a')) {
x[i] = (char) (a[i] + 18);
} else if ((a[i] >= 'A' && a[i] <= 'Z') || (a[i] >= 'a' && a[i] <= 'z')) {
x[i] = (char) (a[i] - '\b');
} else {
x[i] = a[i];
}
}
//string m = x, input;
//if (m == input) {
for (int i2 = 0; i2 < 38; i2++) {
if ((b[i2] >= 'A' && b[i2] <= 'Z') || (b[i2] >= 'a' && b[i2] <= 'z'))
{
y[i2] = (char) ((int)b[i2] + 16);
if ((y[i2] > 'Z' && y[i2] < 'a') || y[i2] >= 'z')
{
y[i2] = (char) (y[i2] - 26);
}
}
else
{
y[i2] = b[i2];
}
}
cout << endl;
// String n = String.valueOf(y);
// text.setText(n);
cout << x << endl;
cout << y << endl;
//}
结果:
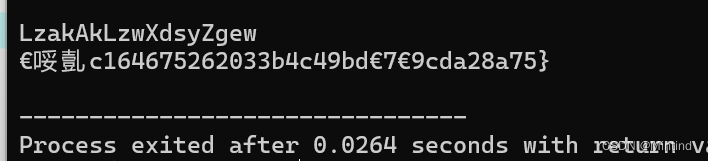 x数组是没问题的,但y数组有乱码,用模拟器打开apk文件输入x可以得到flag:
x数组是没问题的,但y数组有乱码,用模拟器打开apk文件输入x可以得到flag:flag{c164675262033b4c49bdf7f9cda28a75}
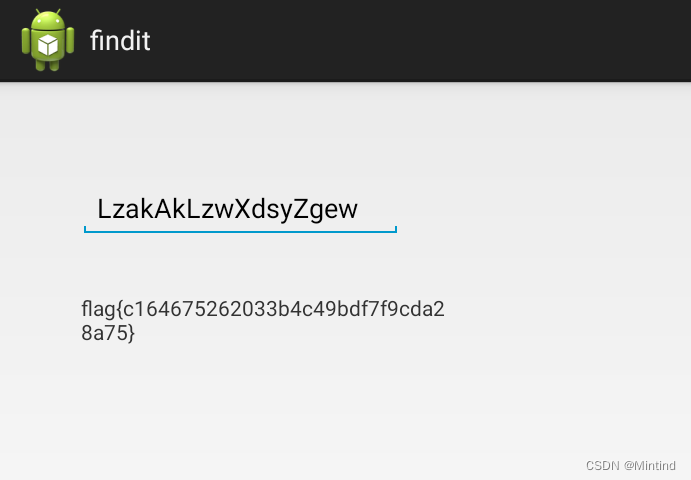 所以运行一下还是很有必要的,省很多时间(汗
所以运行一下还是很有必要的,省很多时间(汗
但是为什么自己写的y数组不正确呢,通过调试发现有情况是y[i2] = (char) ((int)b[i2] + 16)时,数值超过了127,导致了溢出
为什么apk中就能得到正确结果呢
看了别人的题解发现b数组是加密后的数组(确实很像,拼起来可以看到开头四个字母,然后两个大括号把一堆字符括起来),b到y就是凯撒密码解密的过程…
也有像我这样的代码的,但是能得到正确结果,是因为是python吗…不懂















 257
257

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









