







注意,答案只是代表是他人写的代码,正确,但不一定能通过测试(比如超时),列举出来只是它们拥有着独到之处,虽然大部分确实比我的好
168. Excel Sheet Column Title
题目
Given a positive integer, return its corresponding column title as appear in an Excel sheet.
For example:
1 -> A
2 -> B
3 -> C
...
26 -> Z
27 -> AA
28 -> AB
思路与解答
这题我做过啊。。。好像那个是反向的。。。
s = ""
while True:
s = chr(65+(n-1)%26) + s
if n <= 26: return s
n = (n-1)/26当时为了理清逻辑想了好久,(n-1)%26和(n-1)/26分别都是错了一次才反应过来
想想怎么化简
s = ""
while n > 0:
s,n = chr(65+(n-1)%26) + s,(n-1)/26
return s答案
从10个数字转换为26个数字。这个棘手的部分是在26进制系统中缺少等价数字’0’。这个说法很好,使我更清楚的理解这道题
def convertToTitle(self, n):
r = ''
while(n>0):
n -= 1
r = chr(n%26+65) + r
n /= 26
return r其它人的方案
def convertToTitle(self, num):
capitals = [chr(x) for x in range(ord('A'), ord('Z')+1)]
result = []
while num > 0:
result.append(capitals[(num-1)%26])
num = (num-1) // 26
result.reverse()
return ''.join(result)一行方案,又是巧妙的递归调用自己
return "" if num == 0 else self.convertToTitle((num - 1) / 26) + chr((num - 1) % 26 + ord('A'))501. Find Mode in Binary Search Tree
题目
Given a binary search tree (BST) with duplicates, find all the mode(s) (the most frequently occurred element) in the given BST.
Assume a BST is defined as follows:
The left subtree of a node contains only nodes with keys less than or equal to the node’s key.
The right subtree of a node contains only nodes with keys greater than or equal to the node’s key.
Both the left and right subtrees must also be binary search trees.
For example:
Given BST [1,null,2,2],
1
\
2
/
2return [2].
Note: If a tree has more than one mode, you can return them in any order.
Follow up: Could you do that without using any extra space? (Assume that the implicit stack space incurred due to recursion does not count).
思路与解答
创个全局变量字典用来保存个数?遍历用来统计?
居然可能有多个
from collections import defaultdict
class Solution(object):
d=defaultdict(int)
def findMode(self, root):
"""
:type root: TreeNode
:rtype: List[int]
"""
def dfs(r):
if not r: return
self.d[r.val] += 1
dfs(r.left)
dfs(r.right)
dfs(root)
vmax = vmax = sorted(self.d.items(), lambda x, y: cmp(x[1], y[1]), reverse=True)[0][1]
return [k for k in self.d.keys() if self.d[k] == vmax]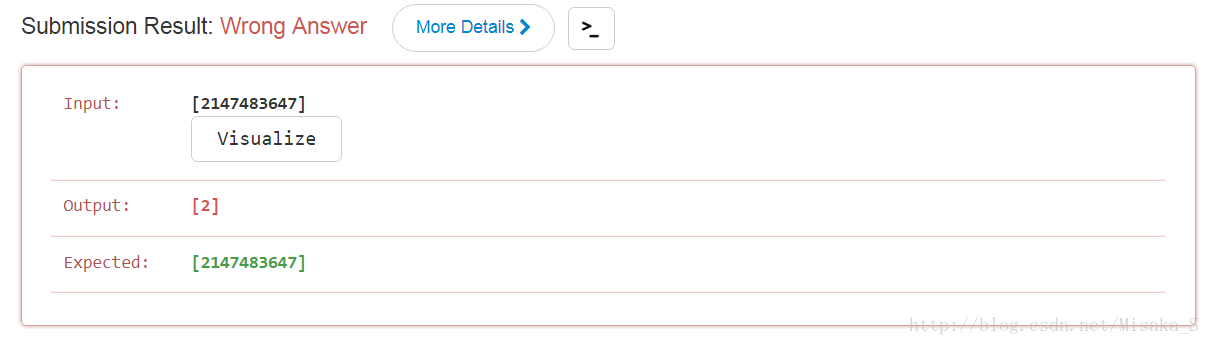
经过我不断的尝试,发现这道题在测试的时候怎么说呢,根本没有间隔,由于我的字典没有办法连续使用,所以产生了GG
于是我在方法开头用d={}重置了字典,结果发现没有defaultdict(int) 效果了,心一横,干脆不用了
class Solution(object):
def findMode(self, root):
"""
:type root: TreeNode
:rtype: List[int]
"""
if not root :return []
d={}
def dfs(r):
if not r: return
d[r.val] = d.get(r.val,0)+1
dfs(r.left)
dfs(r.right)
dfs(root)
vmax = sorted(d.items(), lambda x, y: cmp(x[1], y[1]), reverse=True)[0][1]
return [k for k in d.keys() if d[k] == vmax]至于O(1)的方案?emmmmmm
答案
counter…
count = collections.Counter()
def dfs(node):
if node:
count[node.val] += 1
dfs(node.left)
dfs(node.right)
dfs(root)
max_ct = max(count.itervalues())
return [k for k, v in count.iteritems() if v == max_ct]
Dodalao的O(1)方案自己过去拜读吧
28. Implement strStr()
题目
Implement strStr().
Returns the index of the first occurrence of needle in haystack, or -1 if needle is not part of haystack.
思路与解答
题目在说什么啊???
好像是两个字符串,寻找一个在另一个中的匹配,返回首字母位置
if needle not in haystack:return -1
for i in range(len(haystack) - len(needle)+1):
if haystack[i:i+len(needle)] == needle:
return i答案
不需要前面那个判断啊
for i in range(len(haystack) - len(needle)+1):
if haystack[i:i+len(needle)] == needle:
return i
return -1emmm
def strStr(self, haystack, needle):
if needle == "":
return 0
for i in range(len(haystack)-len(needle)+1):
for j in range(len(needle)):
if haystack[i+j] != needle[j]:
break
if j == len(needle)-1:
return i
return -1661. Image Smoother
题目
Given a 2D integer matrix M representing the gray scale of an image, you need to design a smoother to make the gray scale of each cell becomes the average gray scale (rounding down) of all the 8 surrounding cells and itself. If a cell has less than 8 surrounding cells, then use as many as you can.
Example 1:
Input:
[[1,1,1],
[1,0,1],
[1,1,1]]
Output:
[[0, 0, 0],
[0, 0, 0],
[0, 0, 0]]
Explanation:
For the point (0,0), (0,2), (2,0), (2,2): floor(3/4) = floor(0.75) = 0
For the point (0,1), (1,0), (1,2), (2,1): floor(5/6) = floor(0.83333333) = 0
For the point (1,1): floor(8/9) = floor(0.88888889) = 0
Note:
The value in the given matrix is in the range of [0, 255].
The length and width of the given matrix are in the range of [1, 150].
思路与解答
这题读一遍,好像懂了,又好像没懂,不到1的都舍弃了?
感觉写起来会很麻烦啊
啊啊啊啊啊
看到别人的答案后更不想继续写下去了
答案
喏
N = [[0]*len(M[0]) for i in range(len(M))]
M.insert(0,[-1]*(len(M[0])+2))
M.append([-1]*len(M[0]))
for i in range(1,len(M)-1):
M[i].insert(0,-1)
M[i].append(-1)
for i in range(1,len(M)-1):
for j in range(1,len(M[0])-1):
count = 0
Sum = 0
for k in range(-1,2):
for l in range(-1,2):
if M[i+k][j+l] != -1:
count += 1
Sum += M[i+k][j+l]
N[i-1][j-1] = int(Sum/count)
return N500. Keyboard Row
题目
Given a List of words, return the words that can be typed using letters of alphabet on only one row’s of American keyboard like the image below.
思路与解答
感觉上也是非常简单的
生成基础的字典感觉就好麻烦啊
class Solution(object):
def findWords(self, words):
"""
:type words: List[str]
:rtype: List[str]
"""
ls = ["QWERTYUIOPqwertyuiop", "ASDFGHJKLasdfghjkl", "ZXCVBNMzxcvbnm" ]
dq,da,dz={},{},{}
for s in ls[0]:
dq[s] = s
for s in ls[1]:
da[s] = s
for s in ls[2]:
dz[s] = s
l=[]
for w in words:
f,nf=0,0
for s in w:
if s in dq:nf=1
if s in da:nf=2
if s in dz:nf=3
if f != 0 and f != nf:
break
else:
f = nf
else:
l.append(w)
return l虽然看起来长,但是运行起来还是蛮快的
for循环那里应该还能优化的,可是怎么改呢
答案
6666,set还能这样用
return [word for row in [set('qwertyuiop'), set('asdfghjkl'), set('zxcvbnm')] for word in words if set(word.lower()) <= row]
哦
row1 = set("qwertyuiopQWERTYUIOP")
row2 = set("asdfghjklASDFGHJKL")
row3 = set("ZXCVBNMzxcvbnm")
return filter(lambda x: set(x).issubset(row1) or set(x).issubset(row2) or set(x).issubset(row3), words)咳咳,这是啥?是正则匹配?厉害了
return filter(re.compile('(?i)([qwertyuiop]*|[asdfghjkl]*|[zxcvbnm]*)$').match, words)all函数?话说那三个all条件能放一行的吧
result = []
r1 = str('qwertyuiopQWERTYUIOP')
r2 = str('asdfghjklASDFGHJKL')
r3 = str('zxcvbnmZXCVBNM')
for item in words:
if all((letter in r1) for letter in item):
result.append(item)
elif all((letter in r2) for letter in item):
result.append(item)
elif all((letter in r3) for letter in item):
result.append(item)
return result反而没见到谁用字典了。。。。。














 876
876











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









