







1.交换排序的基本思想是:两两比较待排序记录的关键字,若反序即进行交换,直到没有反序的记录为止。
static void swap(int *p,int *s )
{
int tmp;
tmp=*p;
*p=*s;
*s=tmp;
}
void exchange_sort(int *arr,int len)
{
for (int i=0;i<len-1;i++)
{
for (int j=i+1;j<len;j++)
{
if (arr[i]>arr[j])
{
swap(&arr[i],&arr[j]);
}
}
}
}应用交换排序基本思想的主要排序方法有:冒泡排序(Bubble sort)和快速排序(Quick sort)。

</pre><pre name="code" class="cpp" style="color: rgb(85, 85, 85);">//冒泡排序
void bubble_sort(int *arr,int len)
{
for (int i=0;i<len-1;i++)
{
for (int j=0;j<len-i-1;j++)
{
if (arr[j]>arr[j+1])
{
swap(&arr[j],&arr[j+1]);
}
}
}
}
//改进版冒泡排序,当一趟比较后没有交换(flag=false)即已经有序,不再进行,直接跳出
void bubble_sort_ex(int *arr,int len)
{
bool flag=true;
for (int i=0;i<len-1 && flag;i++)
{
flag=false;
for (int j=0;j<len-i-1;j++)
{
if (arr[j]>arr[j+1])
{
swap(&arr[j],&arr[j+1]);
flag=true;
}
}
}
}快速排序是对冒泡排序的一种改进,基本思想:通过一趟排序将待排记录分割为独立的两部分,其中一部分记录关键字均比另一部分记录的关键字小,则可对这两部分记录继续进行排序,已达到整个有序。
//快速排序
static int partition(int *arr,int left,int right)
{
int key=arr[left];
while (left<right)
{
while (left<right && arr[right]>=key)
{
right--;
}
arr[left]=arr[right];
while (left<right && arr[left]<=key)
{
left++;
}
arr[right]=arr[left];
}
arr[left]=key;
return left;
}
static void quick(int *arr,int left,int right)
{
if (left<right)
{
int pivo=partition(arr,left,right);
quick(arr,left,pivo-1);
quick(arr,pivo+1,right);
}
}
void quick_sort(int *arr,int len)
{
quick(arr,0,len-1);
}
2.选择排序的基本思想是:每一趟在n-i-1个记录中选取关键字最小的记录作为有序序列中第i个记录。
最简单的是简单选择排序,一趟简单的选择排序的操作为:通过n-i次关键字间的比较,从n-i-1个记录中选择出关键字最小的记录,并和第i个记录交换。
通俗地讲就是,对比数组中前一个元素跟后一个元素的大小,如果后面的元素比前面的元素小则用一个变量k来记住他的位置,接着第二次比较,前面"后一个元素"现变成了"前一个元素",继续跟他的"后一个元素"进行比较如果后面的元素比他要小则用变量k记住它在数组中的位置(下标),等到循环结束的时候,我们应该找到了最小的那个数的下标了,然后进行判断,如果这个元素的下标不是第一个元素的下标,就让第一个元素跟他交换一下值,这样就找到整个数组中最小的数了。然后找到数组中第二小的数,让他跟数组中第二个元素交换一下值,以此类推。
//选择排序
void select_sort(int *arr,int len)
{
int min=arr[0];
int min_index=0;
int i;
int j;
for (i=0;i<len-1;i++)
{
min=arr[i];
min_index=i;
for (j=i+1;j<len;j++)
{
if (min>arr[j])
{
min=arr[j];
min_index=j;
}
}
if(i!=min_index)//下标并没有改变
{
swap(&arr[i],&arr[min_index]);
}
}
} 堆是一个近似完全二叉树的结构,并同时满足堆性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
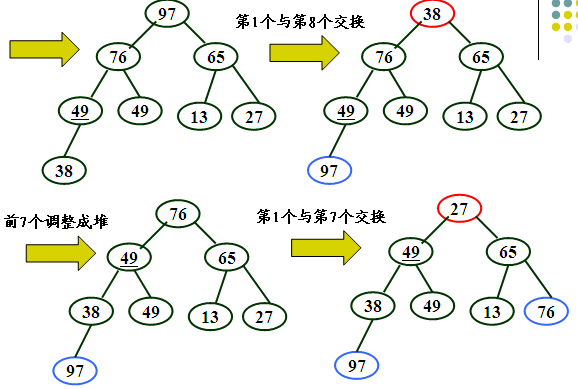
为使记录序列按关键词非递减有序排列,则在堆排序的算法中先建一个“大根堆:,即先选得一个关键字为最大的记录并与序列最后一个记录交换,然后对序列中前n-1个记录进行筛选,重新调整为大根堆,如此反复直至排序结束。
//堆排序
static void heap_adjust(int *arr,int start,int len)
{
int tmp=arr[start];
int i;
while ((i=2*start+1)<len)
{
if (i+1<len && arr[i]<arr[i+1])
{
i++;
}
if (tmp>=arr[i])
{
break;
}
arr[start]=arr[i];
start=i;
}
arr[start]=tmp;
}
void heap_sort(int *arr,int len)
{
for (int start=len/2-1;start>=0;start--)
{
heap_adjust(arr,start,len);
}
for (int i=len;i>1;i--)
{
swap(&arr[0],&arr[i-1]);
heap_adjust(arr,0,i-1);
}
}
//插入排序
//void insert_sort(int *arr,int len)
//{
// int tmp;
// int j;
//
// for (int i=1;i<len;i++)
// {
// tmp=arr[i];
// for (j=0;j<i;j++)
// {
// if (arr[j]>=tmp)
// {
// break;
// }
// }
//
// for (int k=i-1;k>=j;k--)
// {
// arr[k+1]=arr[k];
// }
//
// arr[j]=tmp;
// }
//}
void insert_sort(int *arr,int len)
{
int tmp;
int j;
for (int i=1;i<len;i++)
{
tmp=arr[i];
for (j=i-1;j>=0;j--)
{
if (arr[j]<=tmp)
{
break;
}
arr[j+1]=arr[j];
}
arr[j+1]=tmp;
}
}
void half_insert_sort(int *arr,int len)
{
int tmp;
int j;
int left;
int right;
int mid;
for (int i=1;i<len;i++)
{
tmp=arr[i];
left=0;
right=i-1;
while (left<=right)
{
//mid=(left+right)/2;
mid=(right-left+1)/2+left;
if (tmp<arr[mid])
{
right=mid-1;
}
else
{
left=mid+1;
}
}
for (j=i-1;j>=right+1;j--)
{
arr[j+1]=arr[j];
}
arr[j+1]=tmp;
}
}
//希尔排序
static void shell(int *arr,int len,int gap)
{
int tmp;
int i;
int j;
for (i=gap;i<len;i++)
{
tmp=arr[i];
for (j=i-gap;j>=0;j-=gap)
{
if (arr[j]<tmp)
{
break;
}
arr[j+gap]=arr[j];
}
arr[j+gap]=tmp;
}
}
void shell_sort(int *arr,int len)
{
//for (int gap=len/2;gap>0;gap/=2)
//{
// shell(arr,len,gap);
//}
int gap_index[]={701,301,132,57,23,10,4,1};//特殊序列
int gap_len=sizeof(gap_index)/sizeof(gap_index[0]);
int i;
for (i=0;i<len;i++)
{
if (gap_index[i]<len)
{
break;
}
i++;
}
for (i;i<gap_len;i++)
{
shell(arr,len,gap_index[i]);
}
}
4.归并排序是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
//归并排序
static void merge(int *arr,int len,int gap)
{
int *buff=(int *)malloc(sizeof(int)*len);
assert(buff!=NULL);
int k=0;
int low1=0;
int high1=low1+gap-1;
int low2=high1+1;
int high2=low2+gap-1<len ? low2+gap-1:len-1;//如果越界,进行拉回
while (low2<len)//归并段2只要有,就需要继续归并
{
while (low1<=high1 && low2<=high2)
{
if (arr[low1]<=arr[low2])
{
buff[k++]=arr[low1++];
}
else
{
buff[k++]=arr[low2++];
}
}
while (low1<=high1)
{
buff[k++]=arr[low1++];
}
while (low2<=high2)
{
buff[k++]=arr[low2++];
}
low1=high2+1;
high1=low1+gap-1;
low2=high1+1;
high2=low2+gap-1<len ? low2+gap-1:len-1;//如果越界,进行拉回
}
while (low1<len)//没有归并段2,但有归并段1
{
buff[k++]=arr[low1++];
}
for (int i=0;i<len;i++)
{
arr[i]=buff[i];
}
free(buff);
}
static void merge_ex(int *arr,int len,int gap)
{
int *buff=(int *)malloc(sizeof(int)*gap*2);
assert(buff!=NULL);
int *p=buff;
int m=0;
int low1=0;
int high1=low1+gap-1;
int low2=high1+1;
int high2=low2+gap-1<len ? low2+gap-1:len-1;
while (low1<len)
{
if (low2<len)
{
while (low1<=high1 && low2<=high2)
{
if (arr[low1]<=arr[low2])
{
*buff=arr[low1++];
buff++;
}
else
{
*buff=arr[low2++];
buff++;
}
}
}
while (low1<=high1)
{
*buff=arr[low1++];
buff++;
}
while (low2<=high2)
{
*buff=arr[low2++];
buff++;
}
buff=p;
for (int i=0;i<2*gap && m<len;i++)
{
arr[m]=*buff;
buff++;
m++;
}
buff=p;
low1=high2+1;
high1=low1+gap-1<len ? low1+gap-1:len-1;
low2=high1+1;
high2=low2+gap-1<len ? low2+gap-1:len-1;
}
free(buff);
}
void merge_sort(int *arr,int len)
{
for (int gap=1;gap<len;gap*=2)
{
//merge(arr,len,gap);
merge_ex(arr,len,gap);
//show(arr,len);
}
}















 6784
6784

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









