






row_number开窗连续问题
案例1 计算连续登录天数:
linux本地下创建测试数据 logintest.txt
linux>vi logintest.txt
zhangsan,2022-09-11,1
zhangsan,2022-09-12,1
zhangsan,2022-09-13,1
zhangsan,2022-09-14,1
zhangsan,2022-09-15,1
zhangsan,2022-09-16,1
zhangsan,2022-09-17,1
lisi,2022-08-11,1
lisi,2022-08-12,1
lisi,2022-08-13,0
lisi,2022-0814,1
lisi,2022-08-15,1
lisi,2022-08-16,0
lisi,2022-08-17,1
lisi,2022-08-18,0
wangwu,2022-09-12,1
wangwu,2022-09-13,1
wangwu,2022-09-14,1
wangwu,2022-09-15,0
wangwu,2022-09-16,1
wangwu,2022-09-17,1
wangwu,2022-09-18,1hive创建表并加载数据
hive>create table login_test(
name string,
login_date string,
login int
)
row format delimited
fields terminated by ',';
hive>load data local inpath '/root/data/logintest.txt' into table login_test;hive row_number开窗 1表示登录,0表示未登录
where 条件login=1表示登录
date_sub返回开始日期startdate减少days天后的日期
hive>with temp as(
select
name,
login_date,
login,
row_number() over(partition by name order by login_date) as rn
from
login_test
where login=1
),
result as(
select
name,
date_sub(login_date,rn) as dt
from temp
)
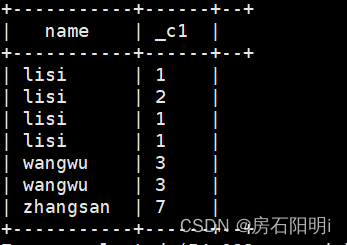
select name,count(1)
from result
group by name,dt;结果
案例2 连续登录超过大于或等于3天的
Linux 本地下创建数据文件 Fruits.txt
linux>vi Fruits.txt
苹果,1990
梨子,1991
梨子,1992
梨子,1993
梨子,1994
香蕉,1995
香蕉,1996
梨子,1997
梨子,1998
橘子,1999
香蕉,2000
香蕉,2001
梨子,2002
梨子,2003
橘子,2004
橘子,2005
橘子,2006
榴莲,2007
香蕉,2008hive创建表并导入数据
hive>create table Fruits_test(
Fruits string,
year int
)
row format delimited
fields terminated by ',';
hive>load data local inpath '/root/data/Fruits.txt' into table Fruits_test;hive计算
year字段 - row_number 别名 result
条件连续登录大于或等于3
hive>with temp as(
select
Fruits,
year,
(year-row_number() over(partition by Fruits order by year)) as result
from Fruits_test
)
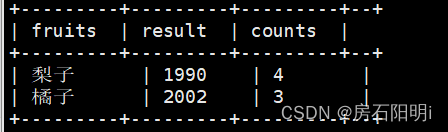
select
Fruits,result,count(1) as counts
from temp
group by Fruits,result
having counts>=3
结果
列转行统计案例案例:
Linux本地创建数据文件
linux> vi test1.txt
u1,Android
u1,ios
u1,Android
u1,mac
u1,windows
u1,windows
u1,mac
u1,Android
u1,Android
u2,ios
u2,Android
u2,windows
u2,Android
u2,mac
u2,Android
u2,windows
u2,Android
u2,ios
u3,Android
u3,Android
u3,ios
u3,windows
u3,mac
u3,ios
u3,Android
u3,windows
hive创建表并导入数据
hive>create table test1(
userid string,
type string
)
row format delimited fields terminated by ',';
hive>load data local inpath '/root/data/test1.txt' into table test1;hive 计算 方法1
hive>with tmp as(
select
userid,
case when type='ios' then 1 else 0 end as ios,
case when type='Android' then 1 else 0 end as Android,
case when type='windows' then 1 else 0 end as windows,
case when type='mac' then 1 else 0 end as mac
from test1
)
select
userid,
sum(ios) as ios,
sum(Android) as Android,
sum(windows) as windows,
sum(mac) as mac
from tmp group by userid;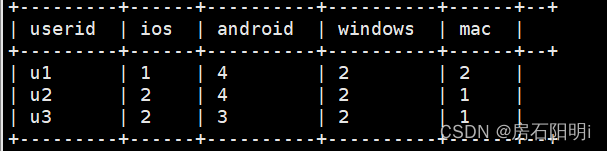
hive 计算 方法2
hive>select userid,
count(if(type='ios',1,null)) as ios,
count(if(type='Android',1,null)) as Android,
count(if(type='windows',1,null)) as windows,
count(if(type='mac',1,null)) as mac
from test1
group by userid;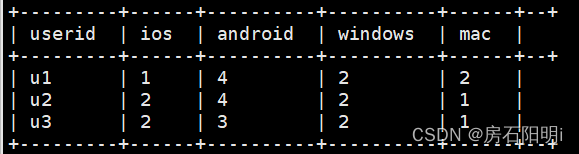
结果一样
hive 计算 方法3
分解式1 : 如果分类个数未知
hive>select
userid,
type,
count(1) as event_counts
from test1
group by userid,type;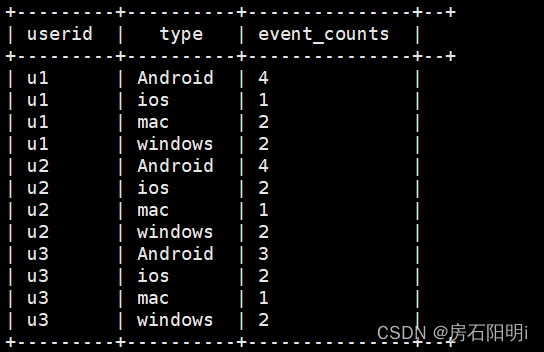
分解式2 :
--中间结果
CONCAT_WS 字符拼接
使用函数CONCAT_WS()。使用语法为:CONCAT_WS(separator,str1,str2,…)
CONCAT_WS() 代表 CONCAT With Separator ,是CONCAT()的特殊形式。第一个参数是其它参数的分隔符。分隔符的位置放在要连接的两个字符串之间。分隔符可以是一个字符串,也可以是其它参数。如果分隔符为 NULL,则结果为 NULL。函数会忽略任何分隔符参数后的 NULL 值。但是CONCAT_WS()不会忽略任何空字符串。(然而会忽略所有的 NULL
hive>select
userid,
concat_ws(':',type,cast(count(1) as string)) as info
from test1
group by userid,type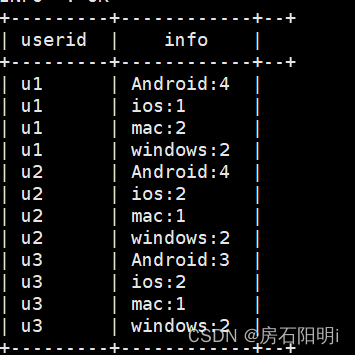
分解式3 :
collect_set函数:列转行专用函数,有时为了字段拼接效果,多和concat_ws()函数连用;
它的主要作用是将某字段的值进行去重汇总,产生array类型字
--最终结果
hive>with temp as(
select
userid,
concat_ws(':',type,cast(count(1) as string)) as info
from test1
group by userid,type
)
select userid,collect_set(info)
from temp group by userid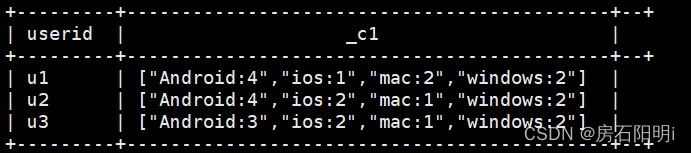
分解式 4 :
hive>with temp as(
select
userid,
concat_ws(':',type,cast(count(1) as string)) as info
from test1
group by userid,type
),
result as(
select userid,collect_set(info) as cols
from temp group by userid
),
cte as(
select userid,str_to_map(concat_ws(',',cols),',',':') as maps
from result
)
select
userid,
maps['ios'] as ios,
maps['Android'] as Android,
maps['windows'] as windows,
maps['mac'] as mac
from cte;















 2526
2526











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









