







个人理解的Python爬虫流程(通俗版–案例NASDAQ)
目录:
- 准备阶段:python安装,相关packages安装。
- 先拿一个目标做测试、编程研究。
- 组装整体框架。
- 结果输出。
- 优化"算法"。
- 应对“反爬虫”技术。
1.准备阶段:python安装,相关packages安装
(1) python安装:Python安装大部分帖子都有涉及到,但是选择好的语言环境更方便于日后的工作。个人更加喜欢Anaconda。主流的IDE有PyCharm, VScode, Jupyter等,笔者用的是Jupyter和VScode, 感觉Jupyter做测试、实验,vscode来做project。
(2) packages:一般来讲需要的packages有: urllib3, BeautifulSoup, selenium等,如果需要加工results,可能会需要Pandas, Numpy等。如果需要解析特殊的WEB 可能会用到json,cookiejar等,具体问题具体分析。
A.如果你是用anaconda, 安装packages很方便,在environment里右上交搜索相应的packgae,应用安装即可。(如图1-1)
图1-1:

之后在jupyter中引用的时候,直接import即可(如图1-2):
图1-2:

B. 如果你是选择vs code,需要用pip install命令,但是先要调配好pip。如果是linux系统,就更加方便了,笔者是linux系统+vscode, 直接用conda 语言环境,activate即可。
2. 先拿一个目标做测试、编程研究
写一整个爬虫程序会很复杂,所以要事先明确目标。每个web的框架,编写逻辑都不一样,甚至同时需要翻到很多个href去运行。所以我会习惯先拿一个目标做做样子~
下面以NASDAQ的web为例,我们来看如何预先“做样子”:
图2-1:

见图2-1,我们想要摘取这家公司的所有相关信息,比如CIK,share price, symbol, 地址,电话等,这些就是尝试。最后我们可能要爬去成百上千家公司的同样信息,每家公司的web框架一样,那么只要做出一家基本上就可以以此类推。
第一步,我们要做的就是将这个web转化成机器可以读懂的代码形式,我们需要运用urllib和beautifulsoup。(如图2-2)基本思路是定义url地址,发出request,打开网页,解码,beautifulsoup,最后print。
图2-2:
##example of how we use headers, to mimic human searching avoid being detected as machine.
url100='https://www.thestreet.com/quote/SCTY.html'
req100=urllib.request.Request(url100)
req100.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36')
html100=urllib.request.urlopen(req100,timeout=500).read()
html100 = bytes.decode(html100,encoding="utf-8")
图2-3:

看一下这个网站的代码,还是很规矩的(后面我们会降到不规则的web代码),每一个span, td 对应每一层,爬虫的根本方法在于,定位你所需要的内容,然后获取信息。get_text(). 所以我们在应用爬虫之前,最好懂得一些html, javascript, css,vue.js, json等基础的前端语言,SQL PHP等服务端语言可能用到的不多。
接着刚才的讲,(a)因为我们要抓取很多个web,所以输出时候最好建一个list来存储,尤其在def的时候尤为重要。(b)如果抓取的信息不规矩,我们还要通过正则来清洗。如图2-4。
图2-4:
##create necessary information list we need, otherwise the loop only rememebr the last call.
symbol_list=list()
name_list=list()
address_list=list()
phone_list=list()
employees_list=list()
issueprice_list=list()
shareoutstanding_list=list()
CIK_list=list()
years_list=list()
for item1 in target_list:
response1=urllib.request.urlopen(item1)
soup1=BeautifulSoup(response1, 'html.parser')
for title1 in soup1.find_all('title'):
title1_txt=title1.get_text()
symbol=re.findall(r'[(](.*?)[)]', title1_txt) ##pulling out the value here between "()" to get symbol.
for table1 in soup1.find_all('table'):
table1_txt=table1.get_text()
if('Company Name' in table1_txt):
td1=table1.find_all('td')
for i in range(len(td1)):
tdtext1=td1[i].get_text()
if('Company Name' in tdtext1):
name=td1[i+1].get_text()
address=td1[i+3].get_text()
phone=td1[i+5].get_text()
employees=td1[i+11].get_text()
issueprice=td1[i+23].get_text()
shareoutstanding=td1[i+35].get_text()
CIK=td1[i+43].get_text()
years=td1[i+17].get_text()
name_list.append(name)
address_list.append(address)
phone_list.append(phone)
employees_list.append(employees)
issueprice_list.append(issueprice)
shareoutstanding_list.append(shareoutstanding)
CIK_list.append(CIK)
years_list.append(years)
symbol_list.append(symbol)
3. 组装整体框架
现在我们开始做整体考虑,我们的目标是要抓取2010年到2018年所有上市公司的信息,那么需要get到很多的href。
图3-1:

这个网址为NASDAQ网页,如图3-1, 我们要获取每一个公司的信息。我们发现有几个特点,(a) url末尾2018-12标明的是IPO日期,那么我们想要获取2010年到2018年的IPO信息,只要创建一个日期自动变换的list即可。(b) 找到如何跳转网页的方法。
图3-2:
##creating an url list, which can help us to open hundreds of web pages to search for IPO companies from 2010 to 2018.
y=['2010','2011','2012','2013','2014','2015','2016','2017','2018']
m=['01','02','03','04','05','06','07','08','09','10','11','12']
##url_list=prior url +year+month.
url_list=['https://www.nasdaq.com/markets/ipos/activity.aspx?tab=pricings&month='+a+'-'+b for a in y for b in m]
for item in url_list:
print(item)
我们创建好日期更换的list,直接引用到def就可以了。那么,如何找到网页跳转的方法呢。看图3-3,我们发现每一个
<a href:“https://…”>(.*?)</a
都是跳转到你所点击的公司信息网址,那么我们只要get到那个网址就可以。具体代码参考图3-4。
图3-3:

图3-4:
target_list=list()
for item0 in url_list:
html0=urllib.request.urlopen(item0).read()
soup0 = BeautifulSoup(html0)
soup0.prettify()
for anchor in soup0.find_all('a', href=True): ##find the link to open new page from the previous one.
a=anchor['href']
if('https://www.nasdaq.com/markets/ipos/company/' in a):
target=a
target_list.append(target)
最后还是建议多运用class和def,我最开始特别不习惯运用def 和class,后来发现,不得不用的时候,才会觉得面向对象的编程,会让思路逻辑更清晰。(图3-5)还有可以适当存档之前的输出结果,运用dic字典也可以更加方便。记住在loop里,脚本语言默认输出最后一个值,要想输出整体list,还是要选择合适的return。
图3-5:
dic={}
with open('longterm.csv', newline='') as csvfile:
reader = csv.DictReader(csvfile)
for row in reader:
dic[row['Stockgroup']]=row['Normalgroup']
def resultstock():
stocklist=list()
for k,v in dic.items():
url1="https://www.nasdaq.com/symbol/"+k
p=get_price(url1)
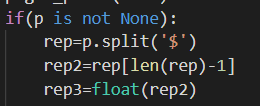
if(p is not None):
rep=p.split('$')
rep2=rep[len(rep)-1]
rep3=float(rep2)
stocklist.append(rep3)
return [a for a in stocklist]
def resultnormal():
normallist=list()
for k,v in dic.items():
url2="https://www.nasdaq.com/symbol/"+v
p2=get_price(url2)
if(p2 is not None):
Opp=p2.split('$')
Opp2=Opp[len(Opp)-1]
Opp3=float(Opp2)
normallist.append(Opp3)
return [b for b in normallist]
def stockgraph():
mean1, std1=norm.fit(resultstock())
plt.hist(resultstock(), color='gold',density=True)
xmin1, xmax1 = plt.xlim()
x1 = np.linspace(xmin1, xmax1, 100)
y1 = norm.pdf(x1, mean1, std1)
plt.plot(x1, y1,color='red')
plt.xlabel('stockprices')
plt.ylabel('Probability Density')
plt.title('Stock Group Current Price')
def normalgraph():
mean2, std2=norm.fit(resultnormal())
plt.hist(resultnormal(),color='green', density=True)
xmin2, xmax2 = plt.xlim()
x2 = np.linspace(xmin2, xmax2, 100)
y2 = norm.pdf(x2, mean2, std2)
plt.plot(x2, y2,color='blue')
plt.xlabel('sotckprices')
plt.ylabel('Probability Density')
plt.title('Normal Group Current Price')
def timer(n):
while True:
T=time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) ##get local time
print(T)
plt.show(stockgraph())
plt.show(normalgraph())
time.sleep(n)
4. 结果输出
笔者最后选择输出csv格式,但是很多人也可以直接在python里运用numpy, pandas去做运算加工。也可以链接数据库,具体才考大神的笔录。读取/存储csv有几个常用方法,如图4-1:
图4-1:
读取:
url_list=list()
with open('CIKlist.csv', newline='', encoding='UTF-8') as csvfile:
reader=csv.reader(csvfile)
for p in reader:
u=str(p) ##we need to makee those string
prunedd=u.strip(string.punctuation) ##sttrip all the unnecessary pounctuation.like ''.
url='https://www.sec.gov/cgi-bin/browse-edgar?action=getcompany&CIK=000'+prunedd+'&type=S-1&dateb=&owner=exclude&count=40'
url_list.append(url)
存储:
with open('yahooeps.csv','w') as yahoo:
yahoo_csv = csv.writer(yahoo)
yahoo_csv.writerow(name_list)
yahoo_csv.writerow(CIK_list2)
yahoo_csv.writerow(EPSlist2)
with open('currentprice20190602.csv','w') as f:
f_csv = csv.writer(f)
for i in range(len(price_list)):
f_csv.writerow([CIK_list[i], Time_list[i], price_list[i]])
import pandas as pd
dataframe.to_csv('result.csv')
5. 清理数据,优化"算法"
清理数据,优化算法很重要,往往更精准,更省时间。笔者一开始写的要花费要几个小时去run,尽量减少Loop和不必要的定义就好。其次要选择机器计算最省事的方法。图5-1:消除index error, value error, 去掉空值,去掉没用的符号和空字符串,不会导致自己白等那么多时间结果出现error,笔者之前很懒,不愿意去考虑这些,总会导致重复工作。
图5-1
stockoption_list=list()
CIKlist=list()
for k,v in dic.items():
response7=urllib.request.urlopen(v)
soup7 = BeautifulSoup(response7,features="lxml")
td7=soup7.find_all('td')
for l in range(len(td7)):
tdtxt7=td7[l].get_text()
if('weighted average exercise price' in tdtxt7):##by searching weighted average excerse price we can have the stock option, incentive plan information with outstanding or granted prices.
try:
tdn7=td7[l].get_text()
except IndexError:
pass
stockoption_list.append(tdn7)
CIKlist.append(k)

优化算法这点,我很垃圾,以前听过大神讲,我写的东西废话太多,所以我理解吧,少说些废话,尽量一步到位,当然有些必要的还是要保留。举个例子,比如说我们找出2到1,000,000所有的质数。我要写就会从2开始试,能被1和自身整除就存在List里。但是这样机器就像小孩子一样一直来回来去数数。
*6. 应对“反爬虫”技术
现在很多web会发爬虫,常见的方法比如检测你访问频率,然后拉黑你的ip,这个时候我们要找很多IP Proxy然后randomly的选则使用,如图6-1,这些可以查找免费的.
图6-1:
##The IP agent which is obtained from agent website. Besides, we can purchase from T-Mall.
proxy_list={
'http':'157.230.220.233:8080',
'http':'45.55.46.222:8080',
'https':'204.48.18.225:8080',
'http':'198.211.109.90:8080',
'https':'159.203.184.52:3128',
'http':'157.230.210.133:8080',
'http':'198.211.103.89:80',
'http':'134.209.125.125:8080',
'http':'157.230.232.130:8080',
'http':'206.189.231.239:8080',
'http':'104.248.7.88:3128'
}
然后我们最好加header,模拟浏览器访问。如图*6-2。
req100=urllib.request.Request(url100)
req100.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36')
html100=urllib.request.urlopen(req100,timeout=500).read()
然后有一些比如手动滑验证码的,可以考虑实用selenium模拟movement。有些网站会自动替换字符串,比如你看到1438可能你转换成代码就变成1348,那么我们需要从新定义字符串。有些可能会需要图片解析,因为你看到的数字可能是图片,解析图片可能需要PIL。有些会获取返还你的一个时间段cookie,那么记得清除。哦对了。。。记得设time.sleep() 不然太高频率会被疑似DOS攻击,笔者之前就因此被拉黑过…
感言:

路漫漫其"修"远兮,有些东西还是在实践中不断学习,那些专门做这个工作的人真的懂的太多,欢迎大神指正错误,互相学习,一起进步!!
完整项目Github-Nasdaq爬虫
https://github.com/JosephMonkey1992/Python-crawler
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









