






1.循环链表的定义
循环链表是一种链表的变体,它与单向链表相似,但是有一个重要的区别:在循环链表中,最后一个节点指向第一个节点,形成一个循环。
在循环链表中,每个节点包含三个部分:数据域、指针域和前驱指针。数据域用于存储节点的数据,指针域用于指向下一个节点,前驱指针用于指向上一个节点。
循环链表的实现与单向链表类似,但是需要调整最后一个节点的指针,使其指向第一个节点。在循环链表中,我们不能像在单向链表中那样使用 null 来表示链表的结尾,因为 null 不再指向任何节点。
循环链表有很多有用的应用,例如在操作系统中实现环形缓冲区、在人工智能中实现状态机等。

2.循环链表的优点
循环链表的主要优点是从表中任一结点出发都能访问到整个链表,即它具有从尾部到头部方便遍历的特性。
此外,循环链表支持动态扩容,数据的插入或删除不需要移动大量的数据,只需要修改指针即可。因此,在处理大量数据时,循环链表的效率比较高。
双向链表在某些情况下的插入、删除等操作都要比单链表简单、高效。双向链表可以随机访问,它在插入、删除数据时只需要处理前驱和后继节点,不需要像单链表那样从头节点开始遍历。
需要注意的是,循环链表也存在一些缺点,例如设计数据结构时较为麻烦,且占用更多的内存空间(空间换时间),数据结构复杂。另外,在进行插入、删除等操作时,需要考虑前驱节点和后继节点的链接方式,因此,需要有一定的编程技巧。
3.循环链表的基本运算
1.初始化链表
2.按下标删除元素
3.按下标插入元素
4.判断链表是否为空
5.往链表插入第一个元素
6.打印链表
7.查询指定元素
8.往链表末尾插入元素
9.删除链表所有元素
10.按照下标查询元素
11.帮助
1.初始化链表
首先我们先导入我们需要的C语言函数库以及定义好需要的数据类型和结构体和链表的数据类型,因为C语言没有boolean类型所以我们自定义一个,在加上window函数库渲染一下代码风格。
链表的属性有数据域代表要存储的数据类型,指针域代表链表之间的节点都存储着下一个节点的内存地址(用java语言描述的),还有一个length记录链表的长度。
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#include <windows.h>
//因为C语言没有boolean自定义一个boolean类型
#define true 1
#define false 2
#define boolean char
//定义链表的数据类型
typedef int Data;
//定义节点结构体
typedef struct Node{
//数据域
Data data;
//指针域
struct Node *next;
}Node,*Point;
typedef struct LinkList{
//定义头结点
Point head;
//定义尾节点
Point tail;
//定义长度
int length;
} LinkList;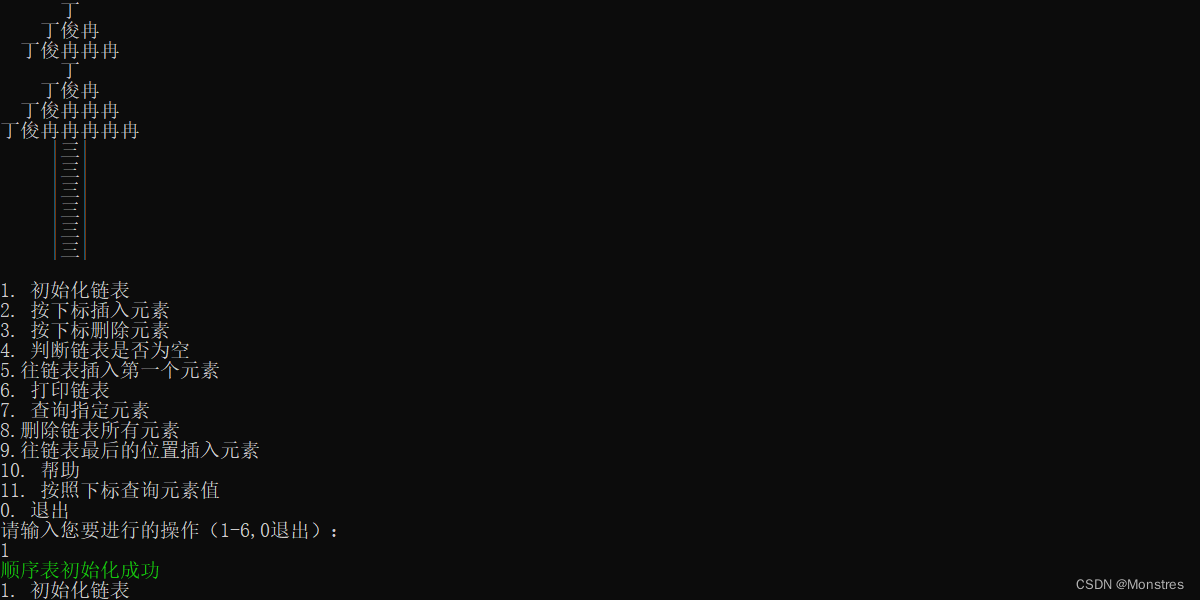
初始化链表,给链表申请一块内存地址,这个Boolean类型实际返回的不是true和false成功是1失败是2,循环链表的结构就是尾节点的next指向头结点,给所有属性赋初始值。
//初始化链表
boolean initLinkList(LinkList *L){
//为链表申请一块空间
Point Header=(Point)malloc(sizeof(Node));
//如果头结点为null,就意味着初始化失败
if(Header==NULL)return 2;
//头节点指向尾节点
L->head=L->tail=Header;
L->length=0;
//头结点下一个节点指向头节点因为没有值(如果是单链表就指向null)
Header->next=L->head;
return 1;
}2.往链表第一个位置插入节点
往链表第一个位置插入节点也叫做头插,每次新增一个节点都被头结点的next指向,而本身新建的节点的next指向上一个节点,在插入之前我们先申请一块内存空间,为避免频繁的写申请内存空间代码,这里我们封装一个添加节点代码提高复用性。
//添加节点(封装,提高插入节点代码的复用性)
Point addNewNode(Data data){
//开辟一块新的内存空间
Point newNode=(Point)malloc(sizeof(Node));
//新的节点的data指向传过来的data
newNode->data=data;
//新的节点的next=null
newNode->next=NULL;
return newNode;
} 之后在插入头结点
//插入节点(头插入)
boolean addFirst(LinkList *L,Data data){
//使用封装好的添加节点开辟一个新的内存空间
Point newNode=addNewNode(data);
//如果新节==null代表插入失败;
if(newNode==NULL) return 2;
//再次使用新节点的next指向头结点的next
newNode->next=L->head->next;
//头结点的next指向新节点
L->head->next=newNode;
//如果头结点等于尾节点 代表不是第一个节点
if(L->head==L->tail)
L->tail=newNode;
L->length++;
return 1;
}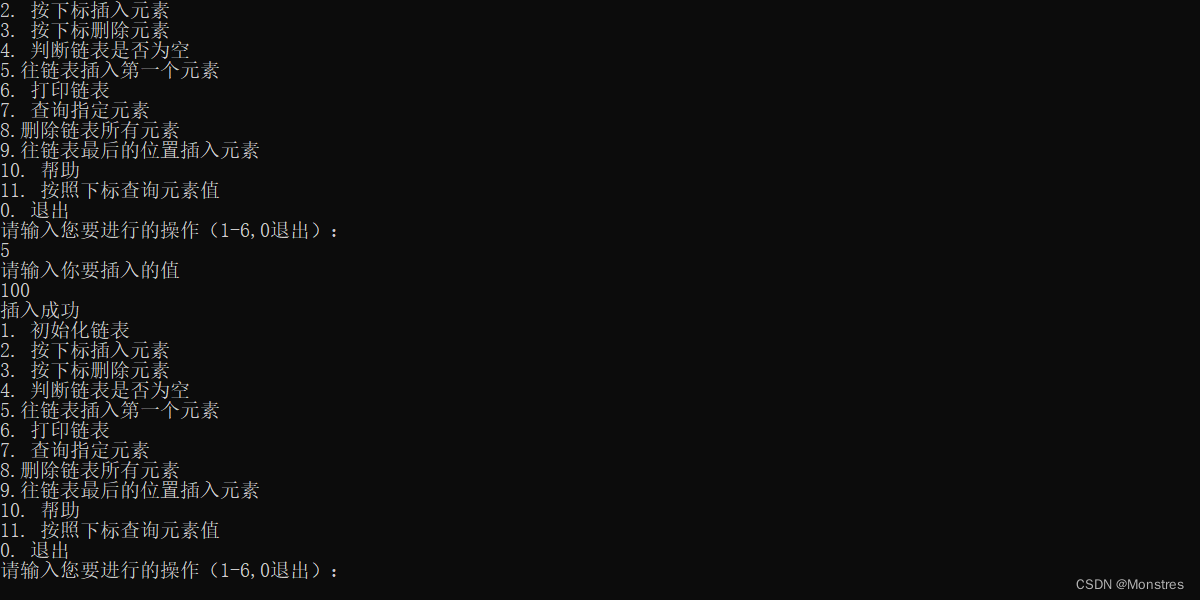
3.往链表最后的位置插入节点
逻辑上和插入头结点是相对的也是比较简单的,新节点的next指向尾节点
//往最后一个元素插入
boolean addLast(LinkList *L, Data data){
//第一步跟头插法一样的步骤
Point newNode=addNewNode(data);
//第二步头插入一样的步骤
if(newNode==NULL) return 2;
//插入新节点
Point p=L->tail;
newNode->next=p->next;
p->next=newNode;
L->tail=newNode;
L->length++;
return 1;
} 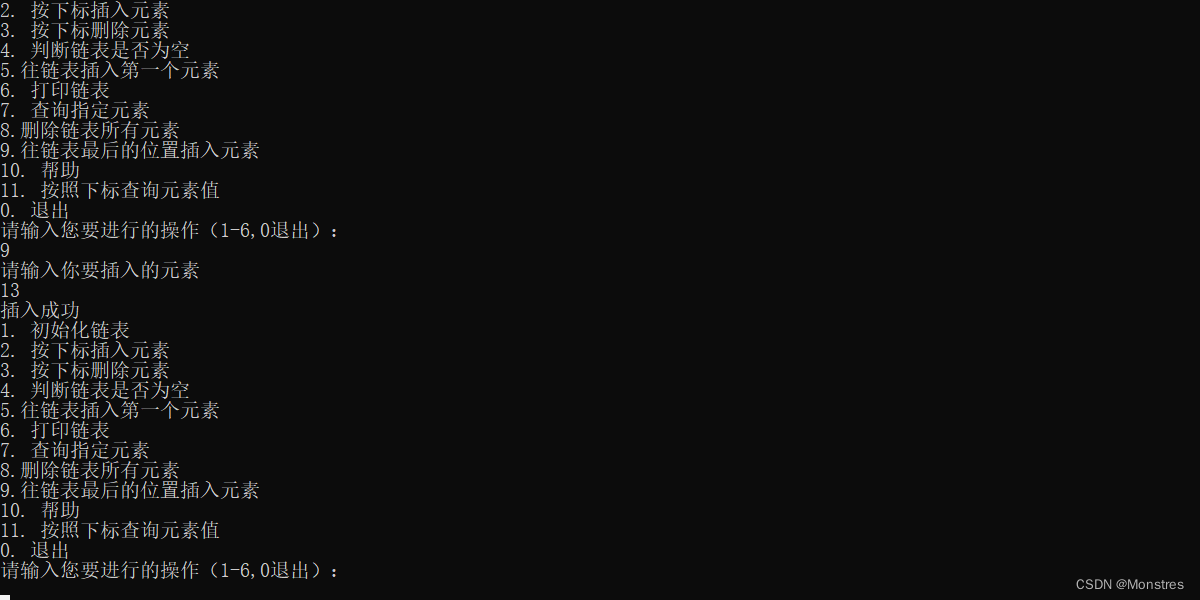
4.按照下标插入节点
按照节点的下标插入节点首先先按照下标查询到该节点,之后该节点往左移移动,新节点代替原来节点的位置
//按照下标插入
boolean addNodeByIndex(LinkList *L,int i,Data data)
{
//[1]判断插入的位置是否合法或特殊
if(i > L->length+1 || i < 1) return 0;
if(isNull(L)) return 0;
//查找
Point p = getNodeByIndex(L,i-1);
//创建新节点
Point newNode = addNewNode(data);
//插入新节点
newNode->next = p->next;
p->next = newNode;
//链表长度加加
L->length++;
return 1;
}以下是执行成功的代码那个zz1是测试
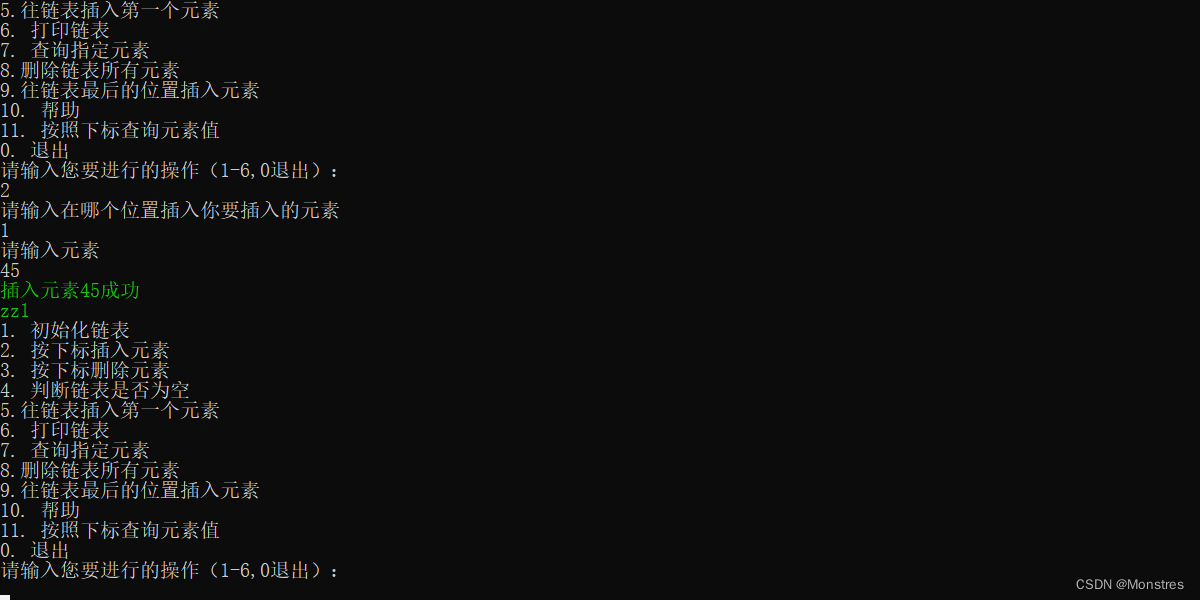
5.按照下标查询元素
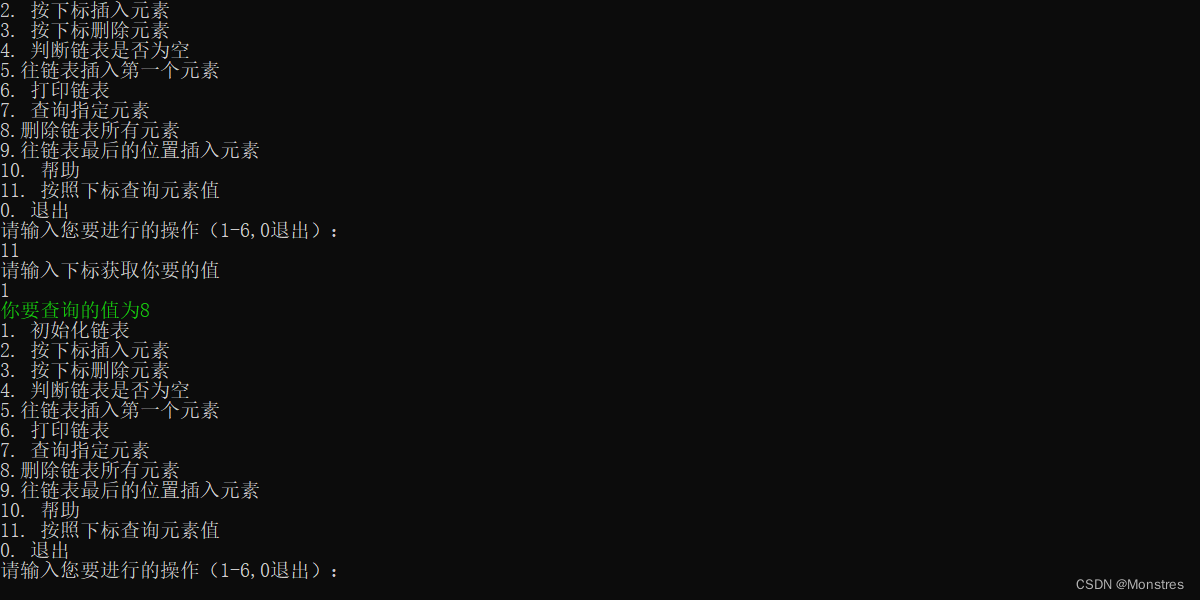
逻辑上按照下标查询元素是不断的循环指向下一个直到找出该循环到该下标的index才结束,该下标的index就是要查找的节点(比如我这边先插入 5 6 7 8四个值,头插入);我查询下标为1的就查询到了8
Point getNodeByIndex(LinkList *L,int i)
{
//判断要定位的结点是否合法或特殊(该函数来自于C语言函数库)
assert(L);//检查L链表是否存在
if(i == 0) return L->head;//返回头指针的情况,用于按位删除或者插入时使用
if(L->length < i || i < 1) return NULL;//检查输入的节点位序是否存在
//生成定位指针
Point p = L->head->next;
//循环遍历查找
while (i > 1)
{
p = p->next;
i--;
}
//[4]返回p
return p;
}
6.查询指定元素
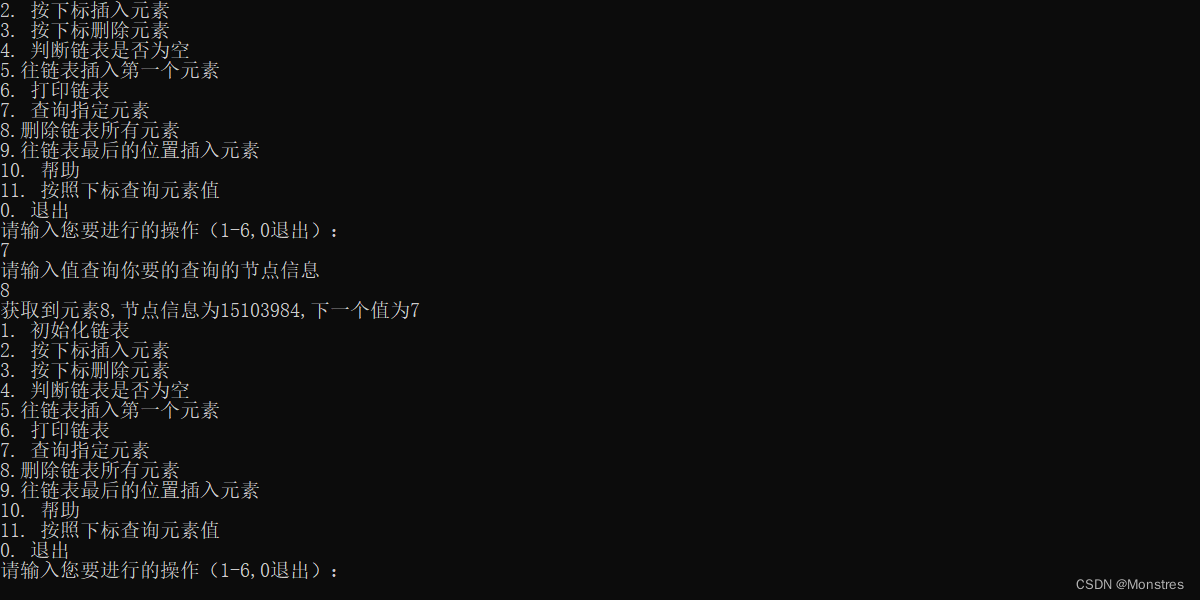
查询指定元素按照值查询,返回的是一个值和下一个节点的内存地址和下一个节点的值实际上的逻辑也是循环查找。
//按元素值查询
Point getNodeByValue(LinkList *L,Data data)
{
//判错
assert(L);//检查L链表是否存在
Point p = L->head->next;
int i;
//循环查找
for (i = 1; i < L->length; i++)
{
if(p->data == data) return p;
p = p->next;
}
return NULL;
}
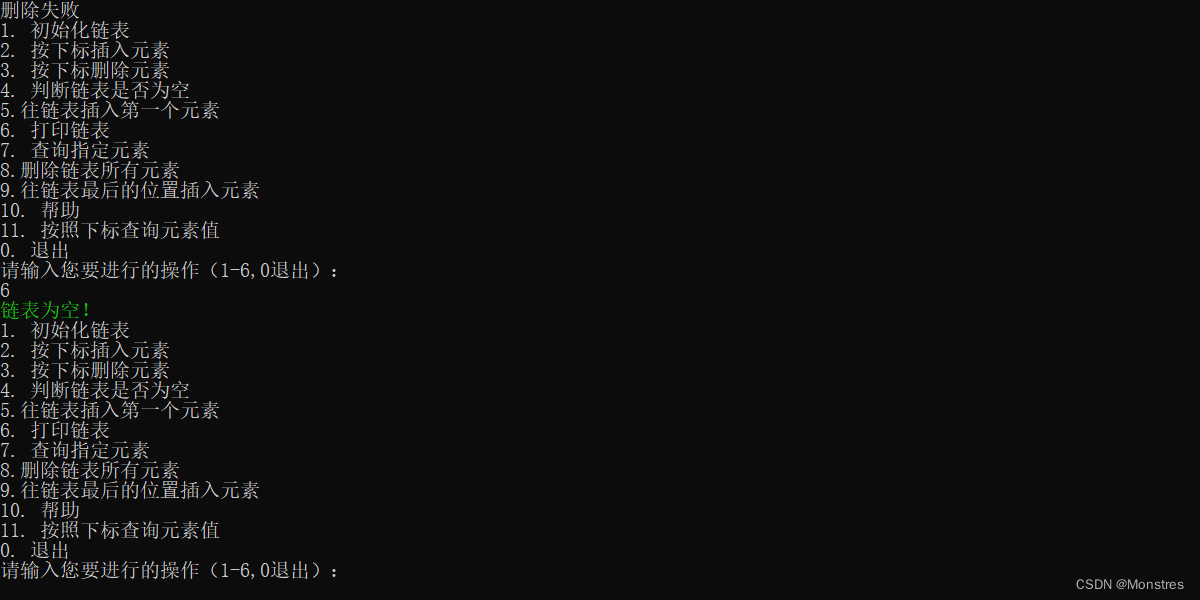
7.判断链表是否为空
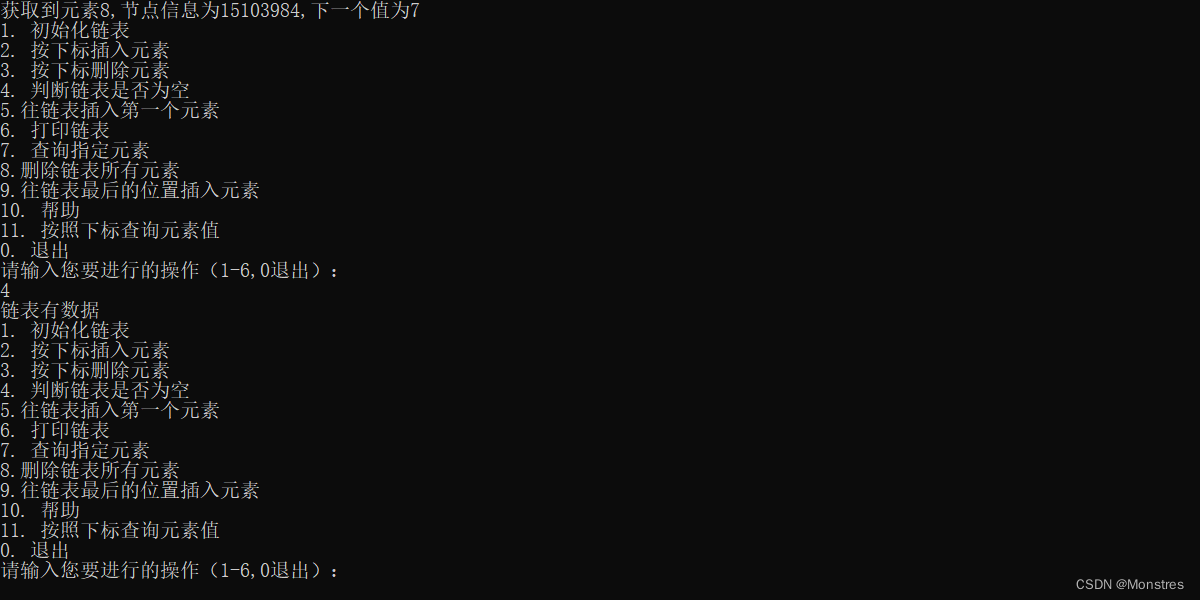
这个比较简单直接上代码,直接查看头结点的next是否指向自己
//判断链表是否为null
boolean isNull(LinkList *L)
{
return (L->head->next == L->head);
}
8.按照下标删除链表元素
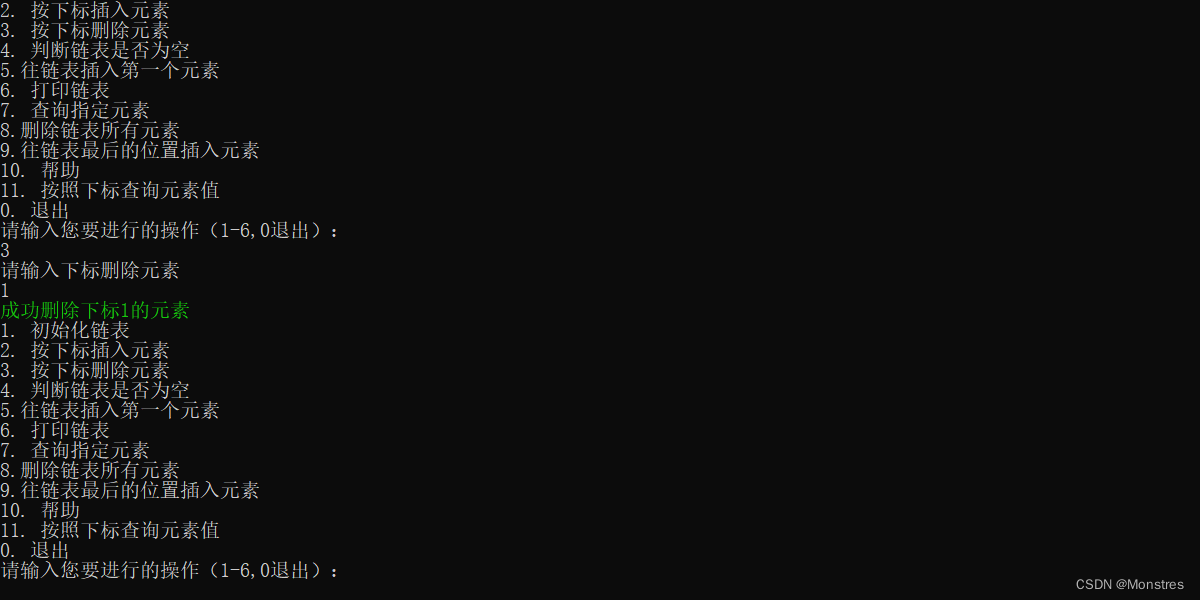
删除链表元素是链表最复杂的操作,逻辑上就是通过下标删除,然后就是元素往左移动覆盖被删除的节点的位置这里要注意一下,在java里面一个引用指向null(这里代表指针),jvm会使用垃圾回收器自动回收该引用的内存(指针),而C语言则需要手动回收free函数,不然后面会出问题
boolean deleteNodeByIndex(LinkList *L,int i)
{
//[1]判断插入的位置是否合法
if(i > L->length || i < 1) return 2;
if(isNull(L)) return 2;
//定位待删除节点和它的前一节点
Point p = getNodeByIndex(L,i-1);//待删除节点的前一节点
Point q = p->next;//待删除节点
//执行删除操作
p->next = p->next->next;
//因为java删除节点之后jvm会自动把指向null的引用(C语言叫指针)回收销毁,但是C语言必须手动销毁
free(q);
//链表长度-1
L->length--;
//删除成功,返回信息
return 1;
}
9.删除所有元素
这个比按下标简单,直接循环链表在free回收循环结束链表自然没有节点
判断插入的位置是否合法
if(isNull(L)) return 2;
//生成指向待删除节点的指针
Point p = NULL;
//for循环陆续删除当前的第一个节点
int i;
for (i = 1; i <= L->length; i++)
{
p = L->head->next;
L->head->next = L->head->next->next;
free(p);
}
//[4]显示删除所有节点的信息,并返回参数
printf("已删除所有节点!\n");
return 2;
}这里提示删除失败是因为不小心多写的实际删除成功
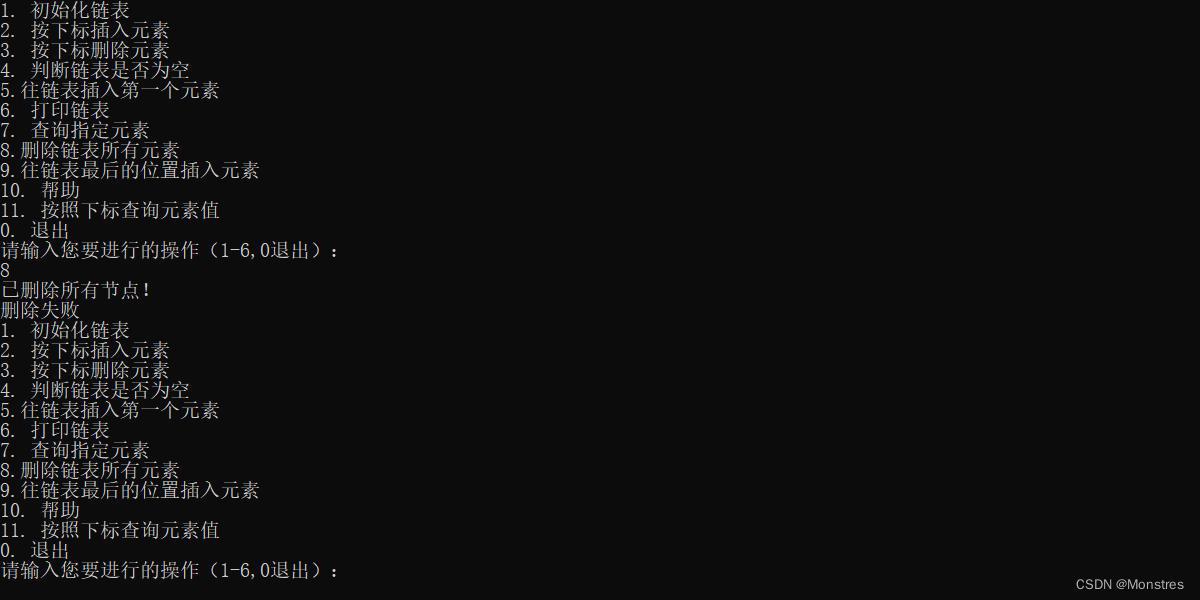
10.打印链表
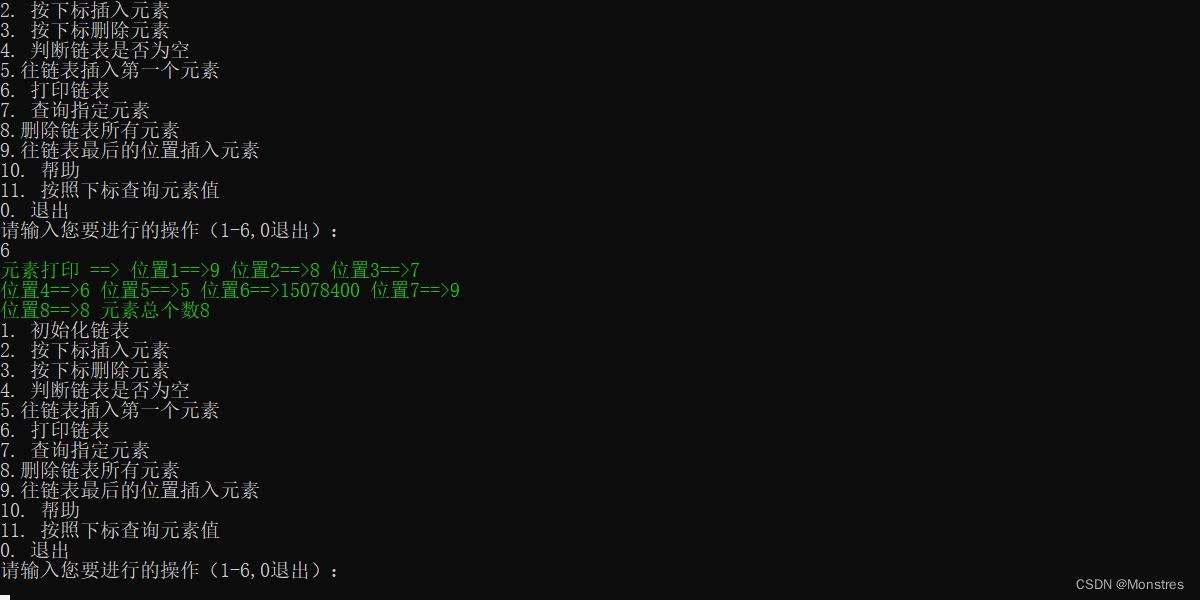
逻辑上就是头结点循环一直指向下一个节点,知道指向自己就代表循环结束
//遍历链表
int printLinkList(LinkList *L)
{
//判空
if(isNull(L))
{
printf("链表为空!\n");
return 2;
}
//生成定位指针
Point p = L->head->next;
//for循环遍历
printf("元素打印 ==> ");
int i;
for(i = 1;i <= L->length;i++)
{
if(i%4==0){
printf("\n");
}
printf("位置%d==>%d ",i,p->data);
p = p->next;
if(i == L->length)
printf("元素总个数%d\n",i);
}
return 2;
}
11.帮助
最后结束
 小结
小结
循环单链表是一种特殊类型的链表,其中最后一个节点指向第一个节点,形成一个循环。在循环单链表中,我们不能像在单向链表中那样使用 null 来表示链表的结尾。非常的灵活,在很多语言的框架上面都是用链表实现比如java的linklist底层就是数组加链表
参考文献
B站黑马程序员
B站动力节点
B站尚硅谷















 9205
9205











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









