






目录
By.LINK_TEXT、By.PARTIAL_LINK_TEXT
有通过name , id , link_text , partial_link_text , tag_name , class_name , tag , xpath ,css_selector.
其中查看公共方法源码后,我们可以发现By.ID、By.NAME、By.CLASS_NAME、By.LINK_TEXT、By.PARTIAL_LINK_TEXT、By.TAG_NAME、这些公共方法其实是使用By.CSS_SELECTOR进行元素定位的。
用百度的搜索框为例:

![]()
By.ID、By.NAME、By.CLASS_NAME
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
browser=webdriver.Chrome()
browser.get('https://www.baidu.com')
sleep(1)
browser.find_element(By.NAME,'wd')
browser.find_element(By.CLASS_NAME,'s_ipt')
browser.find_element(By.ID,'kw')By.LINK_TEXT、By.PARTIAL_LINK_TEXT
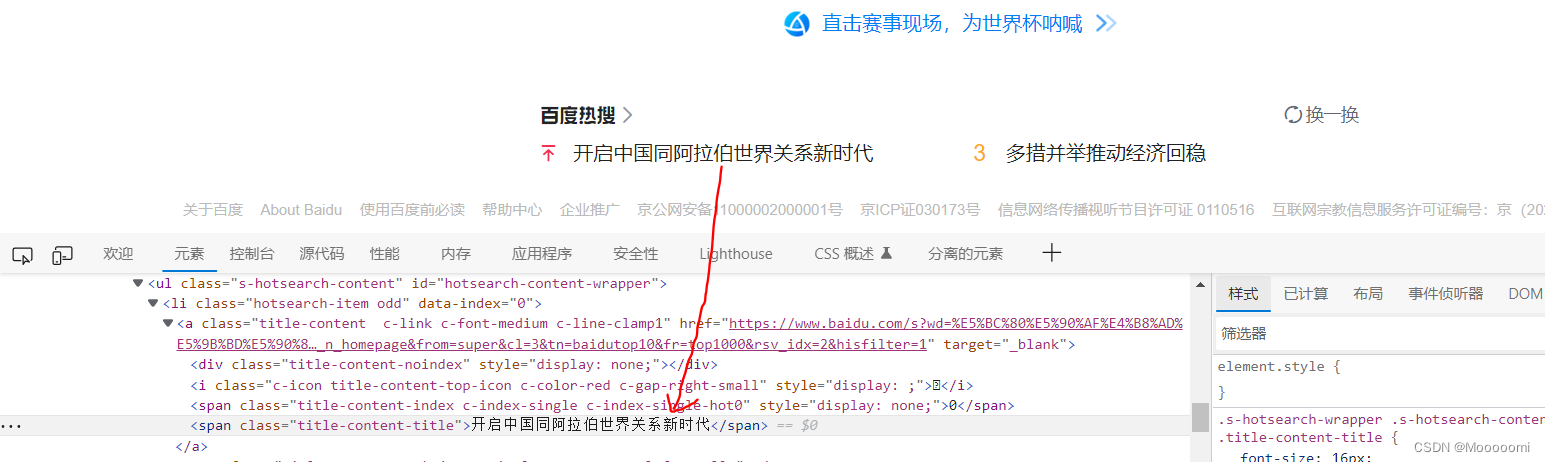
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
browser=webdriver.Chrome()
browser.get('https://www.baidu.com')
sleep(1)
browser.find_element(By.LINK_TEXT,'开启中国同阿拉伯世界关系新时代')
browser.find_element(By.PARTIAL_LINK_TEXT,'中国同阿拉伯')By.TAG_NAME
还是用百度搜索框为例
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
browser=webdriver.Chrome()
browser.get('https://www.baidu.com')
sleep(1)
browser.find_element(By.TAG_NAME,'input')但是一般不用By.TAG_NAME,因为tag_name 很容易重复,所以定位效率较低。
By.XPATH
xpath,有相对路径和绝对路径两大类,一般使用相对路径+正则表达式的方法,不推荐绝对路径,因为绝对路径的后期维护成本较高。
xpath,定位到元素的html代码中,右键复制--> 复制xpath路径
由于XPath是通过路径从头到尾一点点遍历,所以速度很慢。
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
browser=webdriver.Chrome()
browser.get('https://www.baidu.com')
sleep(1)
browser.find_element(By.XPATH,'//*[@id="su"]')BY.CSS_SELECTOR
右键,选择复制selector,就可以得到元素
可以用单属性id,class_name,tag_name来定位
比如id单属性,前面加上#
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
browser=webdriver.Chrome()
browser.get('https://www.baidu.com')
sleep(1)
browser.find_element(By.CSS_SELECTOR,'#kw')class_name单属性,前面加上.
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
browser=webdriver.Chrome()
browser.get('https://www.baidu.com')
sleep(1)
browser.find_element(By.CSS_SELECTOR,'.s_ipt')也可以多属性定位
比如tag_name和id
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
browser=webdriver.Chrome()
browser.get('https://www.baidu.com')
sleep(1)
browser.find_element(By.CSS_SELECTOR,'input#kw')













 5241
5241











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









