







文章目录
一.哈希(按某种规律将某个值存储到固定位置)
除留余数法 key % len
直接映射一定是有哈希碰撞/哈希冲突
如何解决哈希冲突:
①闭散列:也叫开放定址法,如果发送哈希冲突了,就去找下一个空位置
针对的是值相对连续的做法,如果说值特别的散,那么效率会很低
方法一:线性探测,从发送冲突的位置开始,依次向后探测,直到找到下一个空位置为止
(图书馆抢位置,别人如果枪了我的,我就去抢别人的,强盗逻辑)
构建哈希表:
一个vector,一个记录有效个数的变量n
如果vector的最后一个数据冲突则返回到vector的第一个位置继续找空位
删除元素后查找遇到空时回暂停,如何解决这种问题呢?加标记,每个数据给一个枚举状态值,这样删数据只需要将其状态值修改
查找时遇到空EMPTY就停止了,遇到删除DELETE还要继续找
负载因子定义 α = 填入表中的元素个数 / 散列表的长度
α越大,冲突的概率越大,效率低,但是浪费少
α越小,冲突的概率越小,效率高,但是浪费严重
接口:
【 插入 】算插入位置,膜vector的size而不是capacity ,扩容的写法(α>0.7)
扩容时:直接new一个新的table,将原table中元素插入其中,交换指针即可,复用之前insert
重复插入的处理(通过Find接口)
插入的数据不一定是整数,可能是string…用仿函数的方式来解决,取模的地方就用仿函数处理一下
各种字符串Hash函数-博客园
注意:
vector的reserve以后为什么不能cin>>v[i],因为方括号自带检查,reserve只是开空间并未初始化,所以要用resize(默认初始化为0)
方法二:二次探测
引入二次探测背景:连续位置的冲突值比较多的话,引发踩踏洪水效应,按照方法一找邻居的话比较容易冲突
#pragma once
#include<vector>
#include<iostream>
#include<cstdio>
using namespace std;
template<class K>
struct Hash
{
size_t operator()(const K& key)
{
return key;
}
};
//特化版本
//传string要将它转化成整数,这边先使用BKDR的方法
template<>
struct Hash <string>
{
size_t operator()(const string& s)
{
//BKDR
size_t value = 0;
for (auto ch : s)
{
value *= 31;
value += ch;
}
return value;
}
};
//闭散列的方式
namespace CloseHash {
enum Status {
EXIST,
EMPTY,
DELETE
};
template<class K,class V>
struct HashData
{
//保存一对键值对
pair<K, V> _kv;
//保存此数据的状态
Status _status = EMPTY;
};
template<class K, class V,class HashFunc = Hash<K>>
class HashTable
{
public:
bool Erase(const K& key)
{
HashData<K, V>* res = Find(key);
if (key)
{
//找到的情况就可以进行删除
//只需要将状态置Delete即可,有效个数减1
--_n;
res->_status = DELETE;
return true;
}
else
{
//没找到就返回false
return false;
}
}
HashData<K, V>* Find(const K& k)
{
if (_tables.size() == 0)
return nullptr;
HashFunc hf;
//算起始点,往后线性探测/二次探测查找待插入位置
size_t start = hf(k) % _tables.size();
size_t index = start;
size_t i = 0;
//做的是一个连续的查找,不能中间是断的
//也就是说遇到空就会停止
while (_tables[index]._status != EMPTY)
{
if (_tables[index]._kv.first == k && _tables[index]._status == EXIST)
{
return &_tables[index];
}
++i;
index = start + i;
//防止越界
index %= _tables.size();
}
return nullptr;
}
//Insert是插入一对键值对
bool Insert(const pair<K,V>& kv)
{
//如果本身就有这个元素的话,就避免重复插入
HashData<K, V>* res = Find(kv.first);
if (res)
{
return false;
}
//负载因子到0.7就扩容
//负载因子越小,冲突的概率就越低,效率就越高,但是空间浪费多
//负载因子越大,冲突的概率就越高,效率就越低,但是空间浪费少
//没有元素时扩容,负载因子到时扩容
if (_tables.size() == 0 || _n * 10 / _tables.size() >= 7)
{
size_t newSize = _tables.size()== 0 ? 10 : _tables.size() * 2;
HashTable<K, V, HashFunc> newHT;
newHT._tables.resize(newSize);
for (size_t i = 0; i < _tables.size(); i++)
{
newHT.Insert(_tables[i]._kv);
}
_tables.swap(newHT._tables);
}
HashFunc hf;
size_t start = hf(kv.first) % _tables.size();
size_t i = 0;
size_t index = start;
while (_tables[index]._status == EXIST)
{
++i;
index = start + i;
//防止下标出界
index %= _tables.size();
}
//找到位置以后
_tables[index]._kv = kv;
_tables[index]._status = EXIST;
++_n;
return true;
}
private:
//用一个vector来存储Hash元素,n表示tables中有效元素的个数
vector<HashData<K, V>> _tables;
size_t _n = 0;
};
void HashTableTest()
{
HashTable<int, int> ht;
int a[] = {
2, 12, 22, 32, 42, 52, 62 };
for (auto e : a)
{
ht.Insert(make_pair(e, e));
}
ht.Insert(make_pair(72, 72));
ht.Insert(make_pair(32, 32));
ht.Insert(make_pair(-1, -1));
ht.Insert(make_pair(-999, -999));
Hash<int> hs;
cout << hs(9) << endl;
cout << hs(-9) << endl;
cout << ht.Find(12) << endl;
ht.Erase(12);
cout << ht.Find(12) << endl;
}
void HashTableTest2()
{
HashTable<string, string> ht;
ht.Insert(make_pair("sort", "排序"));
ht.Insert(make_pair("string", "字符串"));
}
}
②开散列 – 拉链法/哈希桶
是闭散列/开放定址法的优化:闭散列不同位置冲突数据会互相影响,相互位置的冲突会争抢位置,互相影响效率
开散列相邻位置冲突,不会再争抢位置,不会互相影响
控制负载因子 – 负载因子到了就扩容
极端场景防止一个桶冲突太多,链表太长:当一个桶长度超过一定长以后,转换为红黑树(Java中链表的长度超过了8会变成红黑树)
例子:
表长度100
极端场景:
1 .存了50个值,40个值是冲突的,挂再一个桶中
2 .存储了10000个值,平均每个桶长度100,阶段场景有些桶可能有上千个值
【插入】
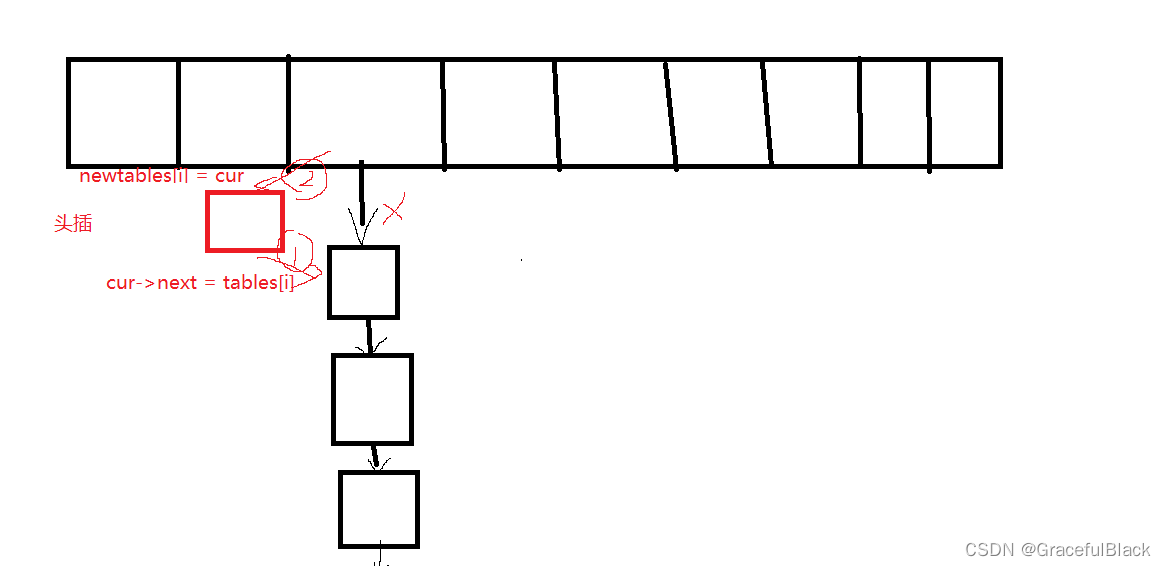
扩容:这种方法中的扩容最好不要复用自己的Insert,因为会new新的节点,这样是没有必要的,可以将原表中的节点一个个链下来,
注意是一个个,而不是一个桶(因为桶中的元素映射到了新表中可能对应新的位置)
table[i]的节点都被拿走了,最好要把它置空一下
newtable是我们的table想要的,把他们的指针再交换一下
【删除】
namespace LinkHash
{
template<class K,class V>
struct HashNode
{
pair<K, V> _kv;
HashNode<K, V>* _next;
HashNode(const pair<K,V>& kv)
:_kv(kv),
_next(nullptr)
{
}
};
template<class K,class V,class HashFunc = Hash<K>>
class HashTable
{
typedef HashNode<K, V> Node;
public:
bool Erase(const K& key)
{
//表空就不用删除
if (_tables.empty())
{
return false;
}
HashFunc hf;
size_t index = hf(key) % _tables.size();
Node* prev = nullptr;
Node* cur = _tables[index];
while (cur)
{
if (cur->_kv.first == key)
{
if (prev == nullptr)
{
//头删
_tables[index] = cur->_next;
}
else
{
//中间删除
prev->_next = cur->_next;
}
--_n;
delete cur;
return true;
}
else
{
prev = cur;
cur = cur-&g 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 743
743











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









