







 本文介绍如何使用Swift的Speech框架实现在iOS设备上的连续语音识别,并确保应用在后台切换时仍能保持功能。通过SFSpeechRecognizer和AudioEngine的配合,实现语音录入与识别无缝衔接,同时处理授权和错误处理。
本文介绍如何使用Swift的Speech框架实现在iOS设备上的连续语音识别,并确保应用在后台切换时仍能保持功能。通过SFSpeechRecognizer和AudioEngine的配合,实现语音录入与识别无缝衔接,同时处理授权和错误处理。
基于Speech框架,实现语音识别转文字功能。
系统要求 >= iOS 10。
以下是在官方提供的Demo基础上稍作改动,目的有两个:
- 实现连续不间断地语音识别,除非自己手动调用停止,报错自动重新启动。
- 应用切后台后再次进入前台后语音可以正常使用 。
代码实现
下面是使用语音引擎和识别引擎一起来完成语音识别功能,语音引擎来录入语音,提供给识别引擎做识别。
工作原理就是 AudioEngine 收集录入语音数据(AudioBuffer),将数据给 SFSpeechAudioBufferRecognitionRequest 这类的实例。SpeechRecognizer会初始化一个语音识别任务实例,不间断地对 AudioBufferRecognitionRequest 里的语音数据进行解析和识别。
import UIKit
import Speech
public class ViewController: UIViewController, SFSpeechRecognizerDelegate {
// MARK: Properties
private let speechRecognizer = SFSpeechRecognizer(locale: Locale(identifier: "en-US"))!
private var recognitionRequest: SFSpeechAudioBufferRecognitionRequest?
private var recognitionTask: SFSpeechRecognitionTask?
private let audioEngine = AVAudioEngine()
@IBOutlet var textView: UITextView!
@IBOutlet var recordButton: UIButton!
// MARK: View Controller Lifecycle
public override func viewDidLoad() {
super.viewDidLoad()
// Disable the record buttons until authorization has been granted.
recordButton.isEnabled = false
}
override public func viewDidAppear(_ animated: Bool) {
super.viewDidAppear(animated)
// Configure the SFSpeechRecognizer object already
// stored in a local member variable.
speechRecognizer.delegate = self
// Asynchronously make the authorization request.
SFSpeechRecognizer.requestAuthorization { authStatus in
// Divert to the app's main thread so that the UI
// can be updated.
OperationQueue.main.addOperation {
switch authStatus {
case .authorized:
self.recordButton.isEnabled = true
case .denied:
self.recordButton.isEnabled = false
self.recordButton.setTitle("User denied access to speech recognition", for: .disabled)
case .restricted:
self.recordButton.isEnabled = false
self.recordButton.setTitle("Speech recognition restricted on this device", for: .disabled)
case .notDetermined:
self.recordButton.isEnabled = false
self.recordButton.setTitle("Speech recognition not yet authorized", for: .disabled)
default:
self.recordButton.isEnabled = false
}
}
}
}
@objc private func startRecording() throws {
// Cancel the previous task if it's running.
recognitionTask?.cancel()
self.recognitionTask = nil
// Configure the audio session for the app.
let audioSession = AVAudioSession.sharedInstance()
try audioSession.setCategory(.record, mode: .measurement, options: .duckOthers)
try audioSession.setActive(true, options: .notifyOthersOnDeactivation)
let inputNode = audioEngine.inputNode
// Create and configure the speech recognition request.
recognitionRequest = SFSpeechAudioBufferRecognitionRequest()
guard let recognitionRequest = recognitionRequest else { fatalError("Unable to create a SFSpeechAudioBufferRecognitionRequest object") }
recognitionRequest.shouldReportPartialResults = true
// Keep speech recognition data on device
if #available(iOS 13, *) {
recognitionRequest.requiresOnDeviceRecognition = false
}
// Create a recognition task for the speech recognition session.
// Keep a reference to the task so that it can be canceled.
recognitionTask = speechRecognizer.recognitionTask(with: recognitionRequest) { result, error in
var isFinal = false
if let result = result {
// Update the text view with the results.
self.textView.text = result.bestTranscription.formattedString
isFinal = result.isFinal
print("Text \(result.bestTranscription.formattedString)")
}
if error != nil || isFinal {
// Stop recognizing speech if there is a problem.
//self.audioEngine.stop()
inputNode.removeTap(onBus: 0)
self.recognitionRequest = nil
self.recognitionTask = nil
//self.recordButton.isEnabled = true
//self.recordButton.setTitle("Start Recording", for: [])
self.perform(#selector(self.startRecording), with: nil, afterDelay: 1)
}
}
// Configure the microphone input.
let recordingFormat = inputNode.outputFormat(forBus: 0)
inputNode.installTap(onBus: 0, bufferSize: 1024, format: recordingFormat) { (buffer: AVAudioPCMBuffer, when: AVAudioTime) in
// 这里将识别到的语音(buffer),交给recognitionRequest,speechRecognizer创建的task会持续的对输入的语音数据进行解析和识别。
self.recognitionRequest?.append(buffer)
}
audioEngine.prepare()
try audioEngine.start()
// Let the user know to start talking.
textView.text = "(Go ahead, I'm listening)"
}
// MARK: SFSpeechRecognizerDelegate
public func speechRecognizer(_ speechRecognizer: SFSpeechRecognizer, availabilityDidChange available: Bool) {
if available {
recordButton.isEnabled = true
recordButton.setTitle("Start Recording", for: [])
} else {
recordButton.isEnabled = false
recordButton.setTitle("Recognition Not Available", for: .disabled)
}
}
// MARK: Interface Builder actions
@IBAction func recordButtonTapped() {
if audioEngine.isRunning {
audioEngine.stop()
recognitionRequest?.endAudio()
recordButton.isEnabled = false
recordButton.setTitle("Stopping", for: .disabled)
} else {
do {
try startRecording()
recordButton.setTitle("Stop Recording", for: [])
} catch {
recordButton.setTitle("Recording Not Available", for: [])
}
}
}
}
项目配置上我开起来后台语音功能,这个是为了让应用程序切入后台后录音可以继续进行,从而应用程序再次进入前台后,可以恢复正常的语音识别功能。
设置Background Modes
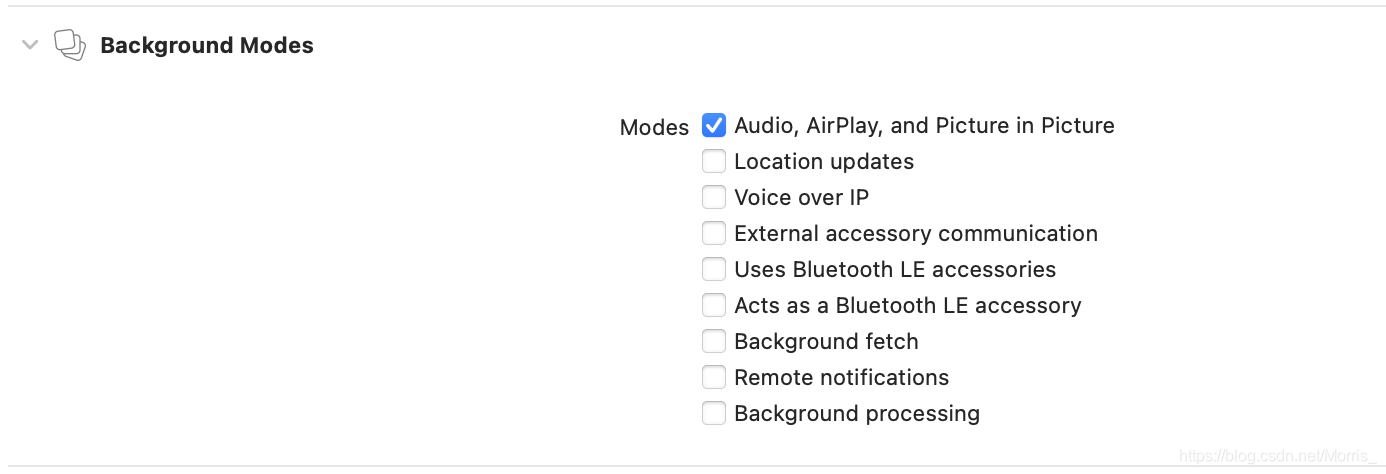
info.pist中会自动添加如下配置

不同的业务场景使用不同的做法就可以了,也可以切后台的时候暂停语音识别,切入到前台后,如果之前是开启的再次开启。
注意实现
语音识别是“语音录入+识别”两个功能的结合,应用程序在运行过程中为了不出错,要保证语音录入正常的情况下,语音识别也正常运行,功能才完整。开启语音录入之后,调用 audioEngine.stop(),语音录入就会停止,这时候语音识别也会报错,谨慎使用audioEngine.stop()。
Speech框架不支持长时间的后台语音识别,切后台后过一段时间会报 +[AFAggregator logDictationFailedWithError:] Error Domain=kAFAssistantErrorDomain Code=1700 的错误。所以如果你的项目里需要支持锁屏或者后台语音识别的话,需要寻找其他替代解决方案。


















 676
676

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











