






刘文 + 原创作品转载请注明出处 +《Linux内核分析》MOOC课程http://mooc.study.163.com/course/USTC-1000029000
进程的调度和进程切换的过程是操作系统研究的重点部分,而在操作系统原理课程中我们已经学习过了大量的进程调度算法。进程调度算法从实现的角度来看就是从运行队列中选择一个新的进程,选择过程中运用的不同的策略就是进程调度算法。所以进程的调度实际上就是Linux系统从一个进程快速切换到另一个进程的过程。在进程切换中有三个地方是值得注意的:
一是如何调度,也就是调度算法的选择;
二是何时调度,即进程调度的时机选择;
三是怎么切换,即选出来的下一个进程如何上CPU执行;
下面我们要重点研究其中的两个部分,首先是进程调度的时机,进程调度的时机主要有以下几点:
1、中断处理过程(包括时钟中断、I/O中断、系统调用和异常)中,直接调用schedule(),或者返回用户态时根据need_resched标记调用schedule();
2、内核线程可以直接调用schedule()进行进程切换,也可以在中断处理过程中进行调度,也就是说内核线程作为一类的特殊的进程可以主动调度,也可以被动调度;
3、用户态进程无法实现主动调度,仅能通过陷入内核态后的某个时机点进行调度,即在中断处理过程中进行调度。
下面我们来分析一下进程的切换的过程,为了控制进程的执行,内核必须有能力挂起正在CPU上执行的进程,并恢复以前挂起的某个进程的执行,这叫做进程切换、任务切换、上下文切换;挂起正在CPU上执行的进程,与中断时保存现场是不同的,中断前后是在同一个进程上下文中,只是由用户态转向内核态执行;进程上下文包含了进程执行需要的所有信息:
用户地址空间:包括程序代码,数据,用户堆栈等
控制信息:进程描述符,内核堆栈等
硬件上下文(注意中断也要保存硬件上下文只是保存的方法不同)
schedule()函数选择一个新的进程来运行,并调用context_switch进行上下文的切换,这个宏调用switch_to来进行关键上下文切换;
next = pick_next_task(rq, prev);//进程调度算法都封装这个函数内部
context_switch(rq, prev, next);//进程上下文切换
switch_to利用了prev和next两个参数:prev指向当前进程,next指向被调度的进程。
下面我们来分析一下进程切换的Linux内核代码:
进程切换调用的是schedule()函数,该函数调用了__schedule()。
static void __sched __schedule(void)
{
...
next = pick_next_task(rq, prev);
if (likely(prev != next)) {
...
context_switch(rq, prev, next); /* unlocks the rq */
...
} else {
...
raw_spin_unlock_irq(&rq->lock);
...
}
...
post_schedule(rq);
...
}这个__schedule()函数精简了以后如上所示,我们根据调度策略在运行队列rq中拿出prev进程的下一个进程,如果next进程和prev不是同一个进程,则进行进程的切换并释放自旋锁,否则直接释放自旋锁。
我们来看一下这个函数里的核心函数context_switch,省去一些minor details,将函数精简如下:
context_switch {
...
mm = next->mm;
if(!mm) {
next->active_mm = oldmm;
...
}
else
switch_mm(oldmm, mm, next);
...
switch_to(prev, next, prev);
...
}该函数做了两件事情,第一是切换页表switch_mm,当next进程mm为空(next是内核线程)时,则使用当前进程的页表,否则切换成新进程的页表(用户态地址空间);第二是切换进程switch_to,这是一段汇编函数,也是进程切换的核心代码。
31#define switch_to(prev, next, last) \
32do { \
33 /* \
34 * Context-switching clobbers all registers, so we clobber \
35 * them explicitly, via unused output variables. \
36 * (EAX and EBP is not listed because EBP is saved/restored \
37 * explicitly for wchan access and EAX is the return value of \
38 * __switch_to()) \
39 */ \
40 unsigned long ebx, ecx, edx, esi, edi; \
41 \
42 asm volatile("pushfl\n\t" /* save flags */ \
43 "pushl %%ebp\n\t" /* save EBP */ \
44 "movl %%esp,%[prev_sp]\n\t" /* save ESP */ \
45 "movl %[next_sp],%%esp\n\t" /* restore ESP */ \
46 "movl $1f,%[prev_ip]\n\t" /* save EIP */ \
47 "pushl %[next_ip]\n\t" /* restore EIP */ \
48 __switch_canary \
49 "jmp __switch_to\n" /* regparm call */ \
50 "1:\t" \
51 "popl %%ebp\n\t" /* restore EBP */ \
52 "popfl\n" /* restore flags */ \
53 \
54 /* output parameters */ \
55 : [prev_sp] "=m" (prev->thread.sp), \
56 [prev_ip] "=m" (prev->thread.ip), \
57 "=a" (last), \
58 \
59 /* clobbered output registers: */ \
60 "=b" (ebx), "=c" (ecx), "=d" (edx), \
61 "=S" (esi), "=D" (edi) \
62 \
63 __switch_canary_oparam \
64 \
65 /* input parameters: */ \
66 : [next_sp] "m" (next->thread.sp), \
67 [next_ip] "m" (next->thread.ip), \
68 \
69 /* regparm parameters for __switch_to(): */ \
70 [prev] "a" (prev), \
71 [next] "d" (next) \
72 \
73 __switch_canary_iparam \
74 \
75 : /* reloaded segment registers */ \
76 "memory"); \
77} while (0)先看当前进程(prev):首先保存当前进程的flags,push ebp,然后把EIP置为标号1,等到当前进程(prev)下一次再开始执行时(被__switch_to切出来),内核堆栈被恢复了以后,刚好会从pop ebp开始执行(和前面的push ebp相对应),即恢复原来的堆栈状态。
再看下一个进程(next): 这个进程即将上CPU,是被jmp __switch_to 切换出来的进程,由于这里使用的是jmp指令而不是call指令,之前又手工压栈了EIP,所以__switch_to会返回到next_ip的地方开始执行,这样就完成了进程的切换过程。
如果只有两个进程的话,那么下一次prev就变成了next,next变成prev,大家可以对照上面再理解一下。
总结一下进程切换的调用过程:schedule -> __schedule -> context_switch -> switch_to -> __switch_to
下面我们利用孟宁老师的menu_OS做实验,使用gdb跟踪:
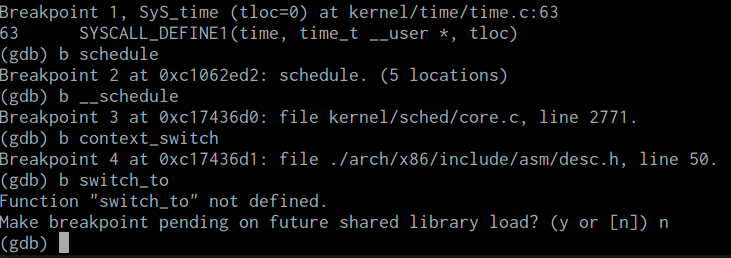
先将断点加在sys_time,进入系统后添加断点schedule,__schedule,context_switch;
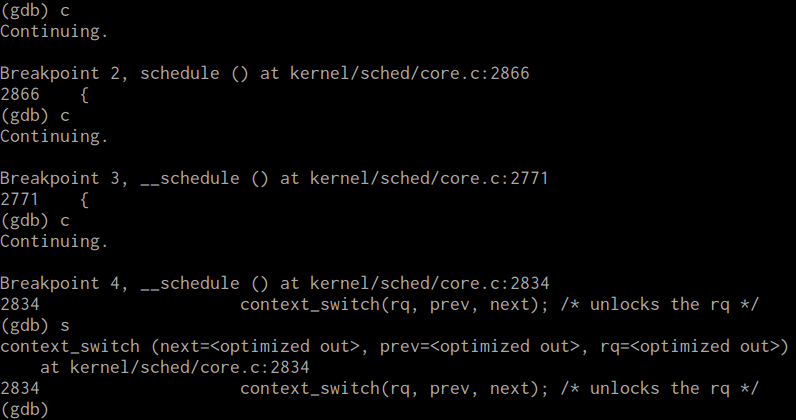
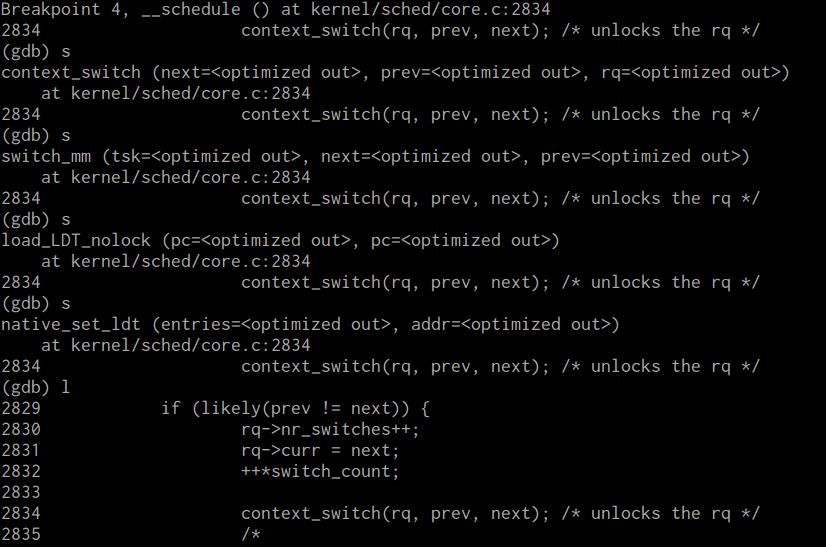
总结
一、当x用户态进程通过进程调度策略切换到用户态进程y时,
最一般的情况:正在运行的用户态进程X切换到运行用户态进程Y的过程
1.正在运行的用户态进程X
2.发生中断——save cs:eip/esp/eflags(current) to kernel stack,then load cs:eip(entry of a specific ISR) and ss:esp(point to kernel stack).
3.SAVE_ALL //保存现场
4.中断处理过程中或中断返回前调用了schedule(),其中的switch_to做了关键的进程上下文切换
5.标号1之后开始运行用户态进程Y(这里Y曾经通过以上步骤被切换出去过因此可以从标号1继续执行)
6.restore_all //恢复现场
7.iret - pop cs:eip/ss:esp/eflags from kernel stack
8.继续运行用户态进程Y
几种特殊情况
1.通过中断处理过程中的调度时机,用户态进程与内核线程之间互相切换和内核线程之间互相切换,与最一般的情况非常类似,只是内核线程运行过程中发生中断没有进程用户态和内核态的转换;
2.内核线程主动调用schedule(),只有进程上下文的切换,没有发生中断上下文的切换,与最一般的情况略简略;
3.创建子进程的系统调用在子进程中的执行起点及返回用户态,如fork;
4.加载一个新的可执行程序后返回到用户态的情况,如execve;
二、有关进程切换
1.为了控制进程的执行,内核必须有能力挂起正在CPU上执行的进程,并恢复以前挂起的某个进程的执行,这叫做进程切换、任务切换、上下文切换;
2.挂起正在CPU上执行的进程,与中断时保存现场是不同的,中断前后是在同一个进程上下文中,只是由用户态转向内核态执行;
3.进程上下文包含了进程执行需要的所有信息
(1)用户地址空间: 包括程序代码,数据,用户堆栈等
(2)控制信息 :进程描述符,内核堆栈等
(3)硬件上下文(注意中断也要保存硬件上下文只是保存的方法不同)
4.schedule()函数选择一个新的进程来运行,并调用context_switch进行上下文的切换,这个宏调用switch_to来进行关键上下文切换
(1)next = pick_next_task(rq, prev);//进程调度算法都封装这个函数内部
(2)context_switch(rq, prev, next);//进程上下文切换
(3)switch_to利用了prev和next两个参数:prev指向当前进程,next指向被调度的进程。















 1106
1106

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









