








logistic回归是分类问题。前面我们讲的分类问题的输出都是 “yes”或者“no”。但是在现实生活中,我们并不是总是希望结果那么肯定,而是概率(发生的可能性)。比如,我们希望知道这个房子在第三个星期被卖出去的概率。那么以前的分类算法就无法使用了,这时logistic 回归就派上了用场。
也就是说,logistic 回归输出的是一个概率值,而不是绝对的0/1。即目标函数变为
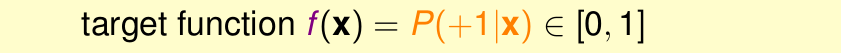
我们用logistic 回归做分类,结果输出的是+1的概率。但是我们的样本的y确是+1或者-1。打个比方,我们预测房子3个月后被卖出去的概率。
但是对于我们搜集房子的样本,只知道样本3个月后是否成功被卖,并不知道该样本被卖的概率。
也就是,我们的样本的数据,不是这样

而是这样

logistic 回归
对于样本x的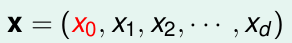
这d个特征(还有一个偏移
x0
。核心还是对这些特征进行加权求和
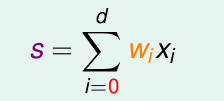
这个s的取值范围是( 负无穷 到 正无穷 )。只是logisitc 回归用了一个函数将他压缩到 [0,1]之间。由于这个压缩函数是 单调递增的,所以结果并不影响。
这个函数就是
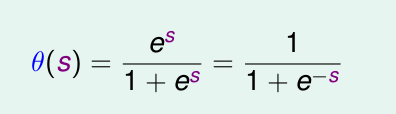
他是光滑且单调的。
那么logistic 函数为

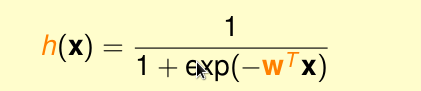
logistic 回归的 Ein
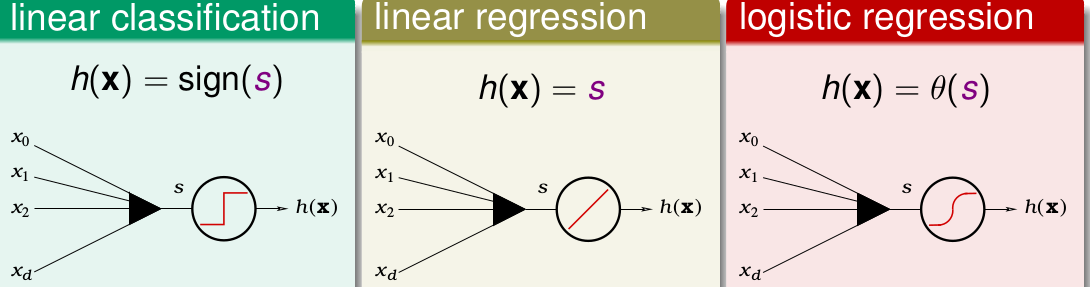
我们总共讲了3种模型。线性分类,线性回归,logistic 回归。其实他们三者的核心都是
也就是都是 对特征的加权再求和。
但是他们的h(x)和
Ein
是不同的。
对于h(x)的形式,三着分别为
对于
Ein
形式
linear classfication 的
Ein
是
∑I[y≠f(x)]
linear regression 的
Ein
是
∑(y−f(x))2
而logistic回归又是什么呢??现在我们来求一求
极大似然法
我们可得到

我们现在有一堆样本
那么他有f产生的概率为

我们有一个h ,h产生这堆样本的概率为

极大自然法,如果h产生一模一样的资料的概率 同 f产生这堆资料的概率越相近,那么就可以说 上面h与f更加接近。
由于我们的样本(资料)本就是f产生的,所以f产生这堆资料的概率很大,接近1。因此,我们希望h可以产生一模一样的资料的概率接近1。

所以我们现在的目标是,
对于logistic回归,通过画图,我们可以得到关于他的对称性
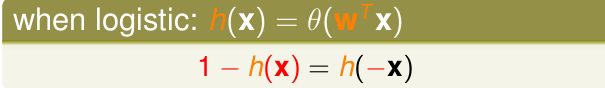
所以likelihood
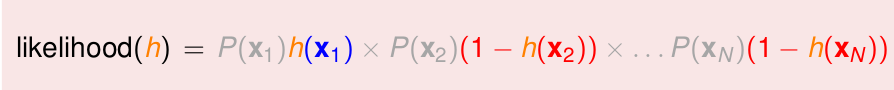
现在,可以改写出
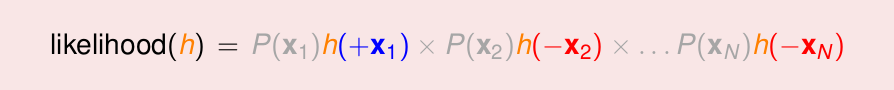
灰色的表示:由于我们相当于是再所有的h中找一个likelihood()最大的那个h,而对于所有的h,其
P(X1),P(X2)...
都是一样的,所以不用去考虑,所以将其表为灰色。
即问题转化为

将其转化为求w的形式
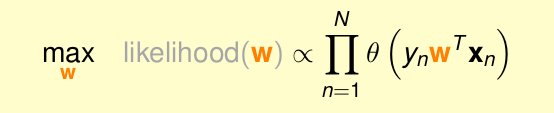
由于是乘积的形式,将其转化为log形式
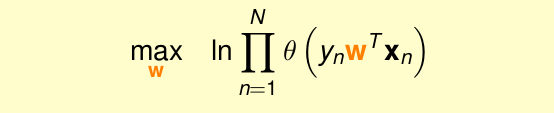
为了计算方便,将max转化为min,并乘以
1N
(乘以
1N
并不影响结果,因为所有的h都乘了),再做进一步处理,即变为
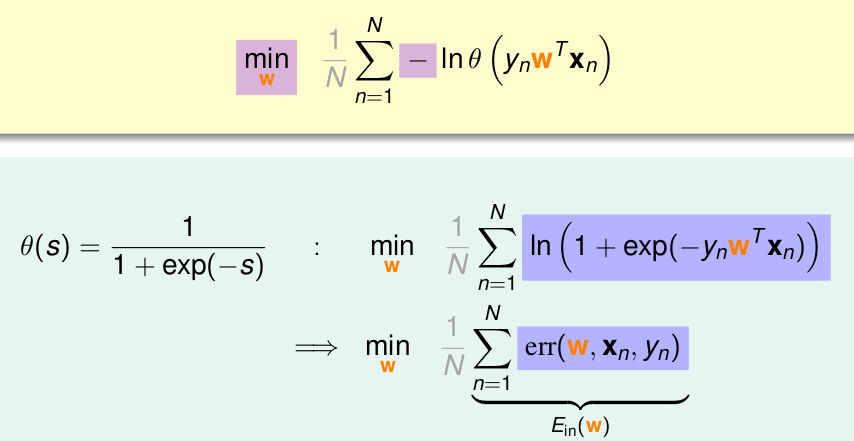
那么我们的最终目标为
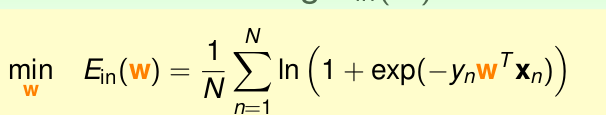
根据上面的式子,由于
Ein
是光滑且凸的,所以我们只要通过令其梯度为0,得到的参数
w1,w2,...
就可以使
Ein
最小。
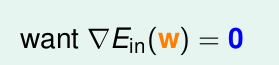
梯度下降法
Ein
的梯度为0,就是令
Ein
对每个
wi
的偏导为0。

最后一步就是把所有的偏导汇总成一个式子。所以橘色的
xn
是一个矢量。
最终变为
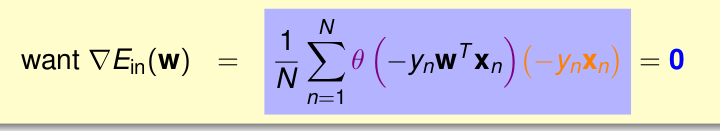
如果
Θ(−ynwTxn)
为0,那么-y_nw^Tx_n为无穷大,不成立。所以只能上面权重求和为0。
我们回顾一下PLA算法

其实上面两步可以归为1步

所以PLA算法可以简化为

发现,上面两图有两个参数,
η
和v .其中
η
表示 步长,而v表示 方向(修正是 改变的方向)
PLA通过不断的迭代更新w的值,使得最终的值达到最优。这种算法迭代优化方法。
logistic求解最小的
Ein(w)
,也是用的是类似的PLA提到的迭代优化算法。一步一步权值向量w,使得
Ein(w)
最小 变权值向量w,迭代优化方法的更新公式是
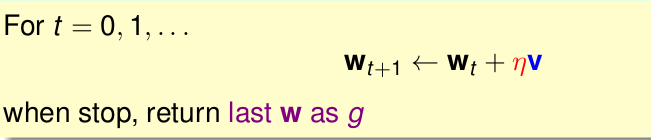
其中
η
表示 步长,而v表示 方向(修正是 改变的方向,我们令他为单位向量,仅仅表示方向,用
η
表示 步长)
那么我们现在就通过求解正确的 步长
η
和方向v,使得
Ein(w)
最优。
我们知道:
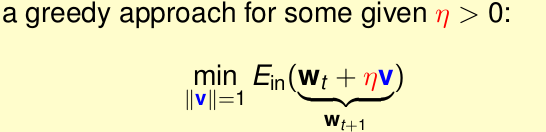
,以上为非线性的。当
η
很小时,我们运用泰勒展开式将其化为 线性形式。
根据泰勒公式:
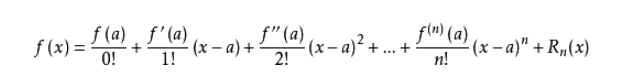
当
η
很小时,可以将泰勒公式简化成前两个的和。且我令
x=wt+ηv
,
a=wt
就可以得到
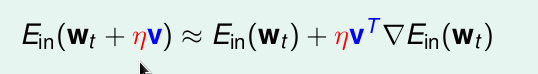
那么问题就变为

我们想得到
wt+1
,那么
wt
是已知的,又
η
是我们给定的。那么上面灰色的表示对最小值无影响。所以只需将上面黑色部分求最小即可。由于是向量相乘,且v我们认定他是单位向量,长度为1,那么我们只能改变中v的方向,就可以达到最小化 。当v的方向与梯度相反时,值最小。又v为单位向量,所以可得

这样我们就求出了v的值。
即最终得到梯度下降为
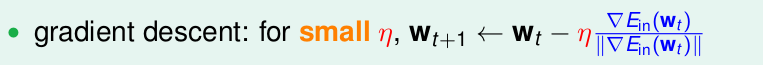
步长
η
太小,导致算法太慢;太大,就很任意出错。
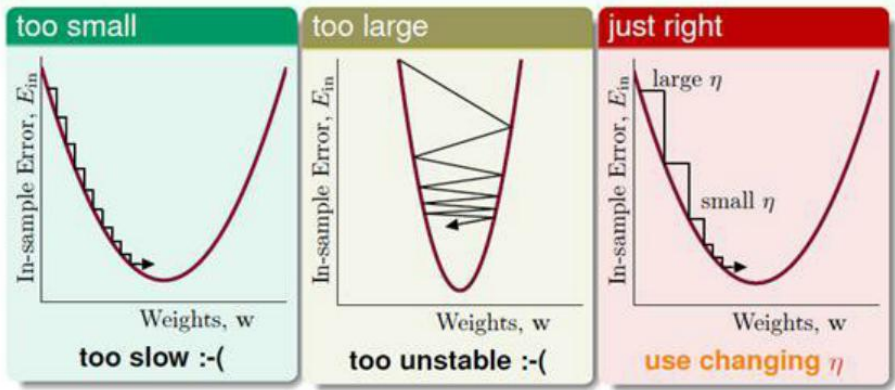
我们希望
η
可以在算法运行时不断的改变。梯度越陡峭,说明离极值点越远,那么希望步长越大;梯度越平缓,说明离极值点越近,那么希望步长越小
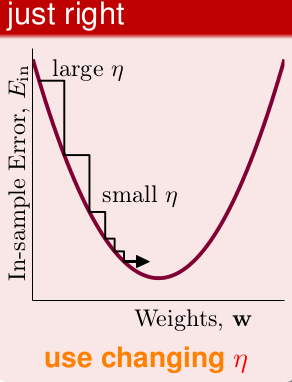
那么其实希望
η
与梯度成单调递增性即可。
为了方便,这里用正比,当然也可以用其他的。

最终结果为
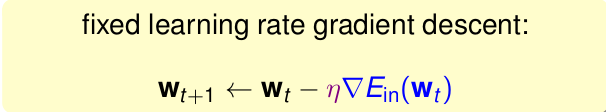
















 2649
2649











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









