







 本文探讨了线性神经元与感知器之间的区别,重点在于它们的学习方法及优化过程。线性神经元旨在使输出更接近目标值,而感知器则是不断接近最佳权重。文中还详细介绍了在线学习和填鸭式学习的概念及其在权值更新中的应用。
本文探讨了线性神经元与感知器之间的区别,重点在于它们的学习方法及优化过程。线性神经元旨在使输出更接近目标值,而感知器则是不断接近最佳权重。文中还详细介绍了在线学习和填鸭式学习的概念及其在权值更新中的应用。
线性神经元
感知器与线性神经元的区别
有点像感知器,但是二者有些不同。感知器的学习方法是不断的使权重w接近最佳权重,但是线性神经元是使输出的y更接近目标y.
对感知器的理解:
感知器收敛过程是每次权重改变时,使得新权重更加接近于每一个广义可行的权重集( get closer to every “generously feasible” set of weights)。注意:是接近于所有的,而不是一个。
对于两个generously feasible weights,每一个都是最优解,但是这两个权重,w都要尽可能的接近。w最终的值就是这两个广义权重 的平均值。然而,即使我们可以确保两个generously feasible weights,每一个都是最优解,但是不能确保二者的平均是最优解,可能还是最差解。

所以,多层神经网络就不再用感知器的学习过程了。所以,证明多层神经网络的权重w在不断提高,我们也不用感知器的方法(即,更接近所有的 可行权重)。那怎么证明我们学到的算法真的提高了呢?我们用预测值y(output values)越来越接近于目标值y(target values) 来作为目标。 也就是 outputs get closer to the target outputs。平方误差测量
∑(y−yi)2
神经网络最简单的就是线性神经元带有平方误差测量
(就是不知道视频里说的最简单,是指:线性神经元是 神经网络里最简单的,还是平方误差测量
∑(y−yi)2
是outputs get closer to the target outputs最简单的)


在线式
举例 来评价这种迭代方法
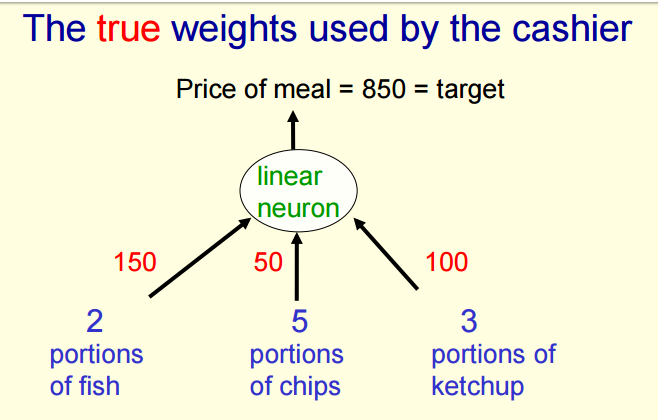
假设你每天中午在一家咖啡馆吃午餐。– Your diet consists of fish, chips, and ketchup 。假设某一天,点了3份fish,2份chips 和 1份ketchup。收费员每天只告诉你当天的消费,而不告诉你某一份菜的价格。现在,你可以在几天后,用这几天的来弄明白每份菜的价格。

解决的方法是:
先随机的猜每份菜的价格,然后不断调整他们,直道总价格越来越接近收费员说的总价格。

We will start with guesses for the weights and then adjust the
guesses slightly to give a better fit to the prices given by the cashier.
真实的价格:
一开始猜测的价格:
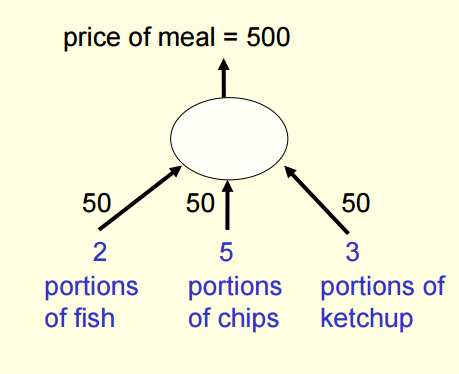
ϵ
是学习率
那么残差为Residual error = 350

可以发现,用了这种方法后,最终预测的y值为70*2+100*5+80*3=880.更接近于target-output 850 . 但是,发现,一开始预测的portions of chips 为50,最接近自己的值,但是调整后变为100。所以,该方法
不能保证在每次
w=(w1,w2,w3)
的迭代过程当中,
w1,w2,w3
能够不断接近最优值,但是可以保证预测的y可以不断的接近目标值target-outputs
注意:上面的例子可以理解为在线学习online learning ,一次只取一个样本。下面求解delta rule Δwi 的步骤,就不是在线学习了,就是普通的学习方法(填鸭式学习)。一次把所有的样本用来训练。
填鸭式
现在讨论如何得到上面的 delta rule
Δwi

迭代器的一些问题

在线式学习delta-rule 与感知器的关系:

在线式delta-rule 的优点:

The error surface for a linear neuron
The error surface in extended weight space
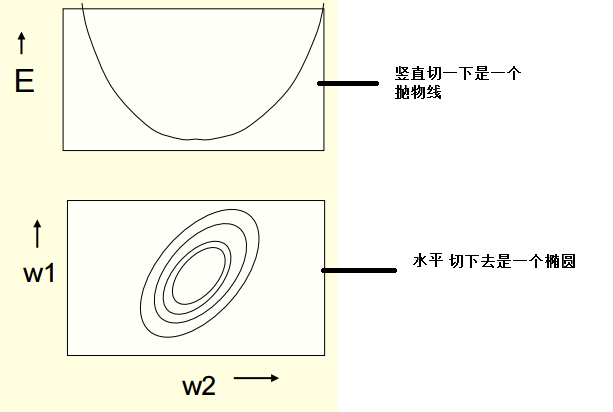
我们让横坐标表示权重,纵坐标表示误差error,得到一个误差平面
那么对于使用平方误差的神经元,上面的误差图形就是一个碗状。
竖直切一刀,得到一个抛物线 ;水平切一刀,得到一个椭圆。如下图
Online versus batch learning
批量学习(填鸭式学习)的权值变化

在批量学习(填鸭式学习)中,每得到一次
Δw
是要计算出所有训练样本误差总和,再用这个所有误差样本总和对w求偏导得到的。那么w的改变是总的误差和的基础上面的,且沿着梯度的方向,这样速度最快,且运动方向是垂直于等高线的。
在线学习 的权值变化

对于在线学习,
Δw
的每一次变化,都只是针对一个样本的。
如上图,假设我们仅仅只有两个训练样本。由于都只是针对一个样本的,那么每一次的误差为
E=12(t−y)2
,则每一次误差的导数为
ϵ∗x(t−y)
。对于每一个样本,x和y都是确定的,仅仅是预测的t=wx,是w的函数。那么对于每一个确定的样本,误差的导数仅仅的w 的一维线性方程。即只要w针对这个样本最调整时,他在误差平面上面的运动方向都是朝着一个方向,(即,运动方向朝着一个方向代表的是 针对这一个样本的运动方向 的 垂直方向是一个定值)。对于两个样本也就有了上图中的两条直线了。
根据上面的讨论,可以得到对于两个样本的话,w的走向是一条z字形的直线。因为先对第一个样本进行调整,w的走向垂直一条直线A1,然后对第二个样本进行调整,w的走向垂直另一条直线A2,然后又对第一个样本进行调整,w的走向又垂直直线A1,以此类推下去。直到走到两条直线A1,A2的交点,这个交点就满足这两个样本。
Why learning can be slow
如果训练样本对应的直线几乎平行,那么上面图形的椭圆就会变得很狭窄。
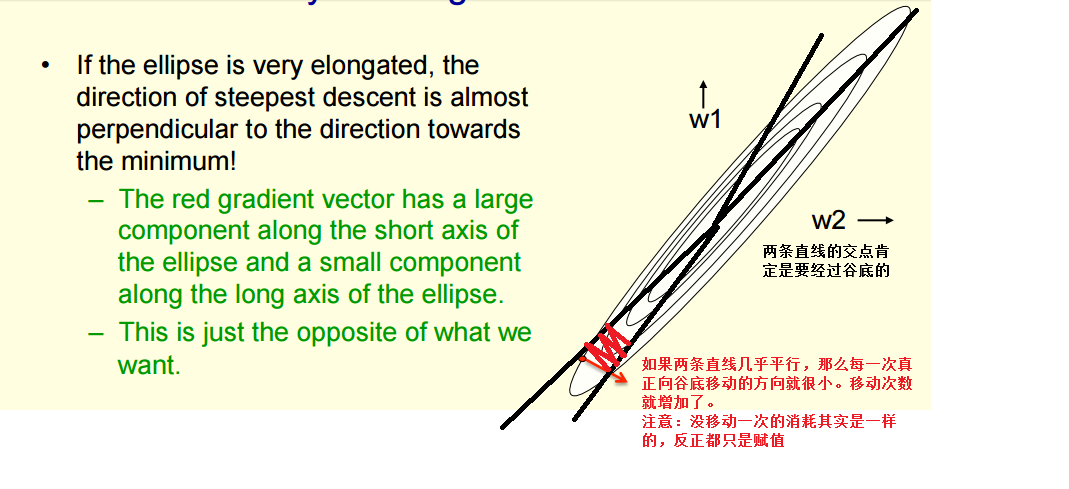
那么梯度就会在我们不想移动的方向经常移动,在我们想移动的方向移动得很小,以至于很慢.
所以简单的梯度下降,即通过调整学习率
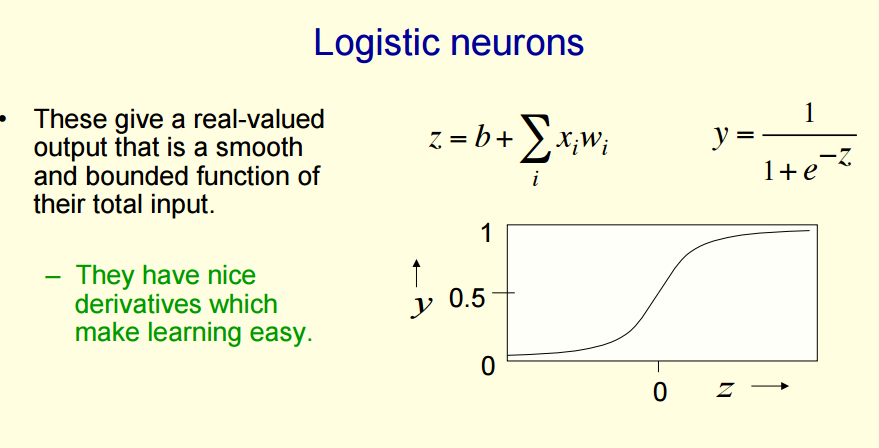
Learning the weights of a logistic output neuron
现在将上面讲解的线性神经元(y=wx)推广到非线性神经元(以logistic神经元为例,还有其他的非线性神经元,如tanh(x))



The backpropagation algorithm
问题引出:
* 如果你的神经网络没有隐藏层,那么你所学到的模型是很有限
* 人为的构造特征(比如,感知器)虽然强大,但是你不知道哪些特征是正确的。只能不断的尝试,实验,观测误差的变化 才能确定 好的 特征。
要求:

总共4种方法:
1. 随机调整一个参数 : 一次调整一次参数
2. 平行的随机调整所有所有参数 : 一次调整所有参数
3. 随机调整 隐藏层单元 的活性
4. 后向反馈算法
方法1
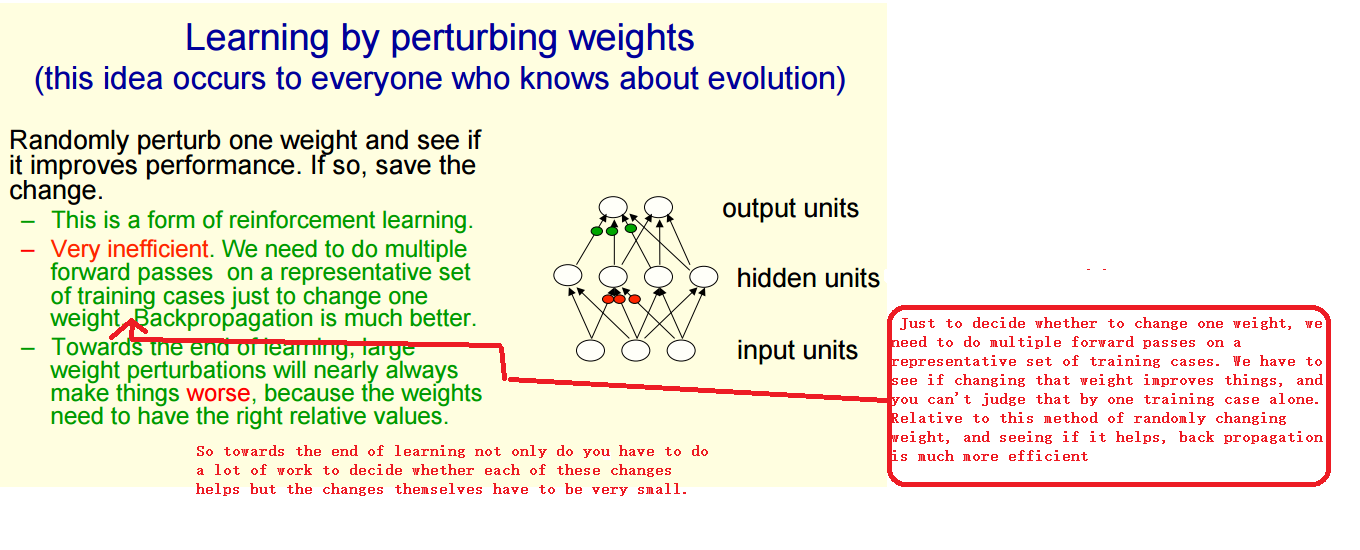

方法2,3

方法4 backpropagation
- 我们可以在同一时间所有隐藏层的误差梯度
- 一旦我们有了隐藏层的误差梯度,就可以求出隐藏层的权重 wij 的梯度
基本计算步骤为:
注意: 我们假定,j下标表示 输出层的单元, i下标表示 隐藏层的单元。
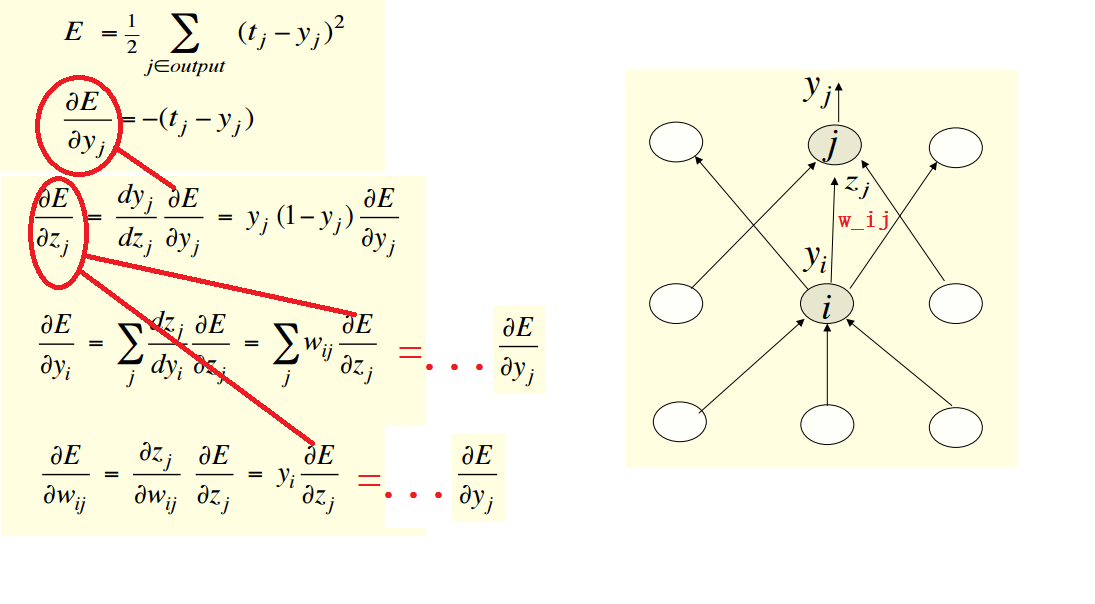
很显然,我们通过输出层的导数,得到了误差对隐藏单元的导数,和误差对权重的导数。
其实这很好理解。
∂E∂yj
表示的是 输出单元
yj
的改变对误差E的影响大小;
∂E∂yi
表示的是 隐藏层单元
yi
的改变对误差E的影响大小;
∂E∂wij
表示的是
wij
的改变对误差E的影响大小


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









