







第零章 序
0.0 序言
简介
日常工作中会面临很多问题,处理问题时候。怎么解决问题?
-
通过工作经验,迅速判断问题出在哪。
-
通过日志
-
系统日志:/var/log 目录下的问题的文件
-
程序日志: 代码日志(项目代码输出的日志)
-
服务应用日志
-
nginx、HAproxy、lvs -
tomcat、php-fpm -
redis、mysql、mongo -
RabbitMq、kafka -
Glusterfs、HDFS、NFS等等
通过日志排除,发现问题根源解决问题
如果1台或者几台服务器,我们可以通过 linux命令,tail、cat,通过grep、awk等过滤去查询定位日志查问题
但是如果几十台、甚至几百台。通过这种方式肯定不现实。
怎么办?
一些聪明人就提出了建立一套集中式的方法,把不同来源的数据集中整合到一个地方。
一个完整的集中式日志系统,是离不开以下几个主要特点的。
-
收集-能够采集多种来源的日志数据
-
传输-能够稳定的把日志数据传输到中央系统
-
存储-如何存储日志数据
-
分析-可以支持 UI 分析
-
警告-能够提供错误报告,监控机制
市场上的产品
基于上述思路,于是许多产品或方案就应运而生了
-
简单的 Rsyslog,Syslog-ng
-
商业化的 Splunk
-
开源的
-
FaceBook 公司的 Scribe,
-
Apache 的 Chukwa,
-
Linkedin 的 Kafak,
-
Cloudera 的 Fluentd,
-
ELK
本文重点介绍 ELK
0.1 何为ELK
ELK是什么
1、ELK 是一种能够从任意数据源抽取数据,并实时对数据进行搜索、分析和可视化展现的数据分析框架
2、ELK 并不是一款软件,而是一整套解决方案,是三个软件产品的首字母缩写,ELasticsearch , Logstash , Kibana 。这三款软件都是开源软件,通常是配合使用,而且又先后归于 Elastic.co 公司名下,故而简称为 ELK协议栈
ELK体系结构
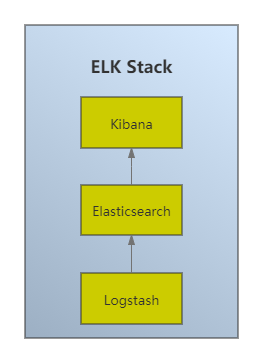
0.2 为何ELK
因为它开源免费,因为它开源免费,因为它开源免费
0.3 核心组件
-
Elasticsearch:分布式搜索和分析引擎,具有高可伸缩、高可靠和易管理等特点。基于 Apache Lucene 构 建,能对大容量的数据进行接近实时的存储、搜索和分析操作。通常被用作某些应用的基础搜索引擎,使其 具有复杂的搜索功能;
-
Logstash:数据收集引擎。它支持动态的从各种数据源搜集数据,并对数据进行过滤、分析、丰富、统一格 式等操作,然后存储到用户指定的位置。
-
Kibana:数据分析和可视化平台。通常与 Elasticsearch 配合使用,对其中数据进行搜索、分析和以统计图 表的方式展示。
-
Filebeat:ELK 协议栈的新成员,一个轻量级开源日志文件数据搜集器,基于 Logstash-Forwarder 源代码 开发是对它的替代。在需要采集日志数据的服务上安装 Filebeat,并指定日志目录或日志文件后,Filebeat 就能读取日志文件数据,迅速发送到 Logstash进行解析,或直接发送到 Elasticsearch进行集中式存储和分 析。
Elasticsearch
Elasticsearch 是一个实时的分布式搜索和分析引擎,它可以用于全文搜索,结构化搜索以及分析。它是一个建立在全文搜索引擎 Apache Lucene基础上的搜索引擎,使用Java语言编写
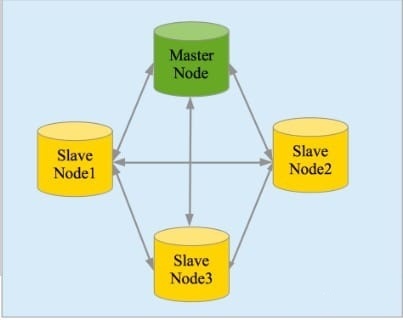
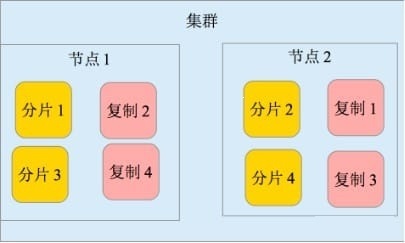
主要特点 实时分析 分布式实时文件存储,并将每一个字段都编入索引 文档导向,所有的对象全部是文档 高可用性,易扩展,支持集群(Cluster)、分片和复制(Shards 和 Replicas)。见图 2 和图 3 * 接口友好,支持 JSON
Logstash
Logstash 是一个具有实时渠道能力的数据收集引擎。使用 JRuby 语言编写。其作者是世界著名的运维工程师乔丹西塞 (JordanSissel)
简单来说logstash就是一根具备实时数据传输能力的管道,负责将数据信息从管道的输入端传输到管道的输出端;与此同时这根管道还可以让你根据自己的需求在中间加上滤网,Logstash提供里很多功能强大的滤网以满足你的各种应用场景。
主要特点
-
几乎可以访问任何数据
-
可以和多种外部应用结合
-
支持弹性扩展
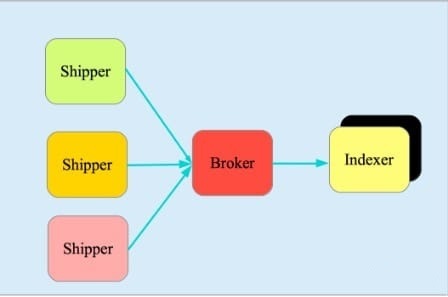
它由三个主要部分组成,见图 4:
-
Shipper-发送日志数据
-
Broker-收集数据,缺省内置 Redis
-
Indexer-数据写入
logstash整个工作流分为三个阶段:输入、过滤、输出。每个阶段都有强大的插件提供支持:
Input 必须,负责产生事件(Inputs generate events),常用的插件有
-
file 从文件系统收集数据
-
syslog 从syslog日志收集数据
-
redis 从redis收集日志
-
beats 从beats family收集日志(如:Filebeats)
Filter常用的插件有, 可选,负责数据处理与转换(filters modify )
-
grok是logstash中最常用的日志解释和结构化插件。:grok是一种采用组合多个预定义的正则表达式,用来匹配分割文本并映射到关键字的工具。
-
mutate 支持事件的变换,例如重命名、移除、替换、修改等
-
drop 完全丢弃事件
-
clone 克隆事件
output 输出,必须,负责数据输出(outputs ship elsewhere),常用的插件有
- elasticsearch 把数据输出到elasticsearch
- file 把数据输出到普通的文件
Kibana
Kibana是一款基于 Apache开源协议,使用 JavaScript语言编写,为 Elasticsearch提供分析和可视化的 Web 平台。它可以在Elasticsearch的索引中查找,交互数据,并生成各种维度的表图.
Filebeat
ELK 协议栈的新成员,一个轻量级开源日志文件数据搜集器,基于 Logstash-Forwarder源代码开发,是对它的替代。在需要采集日志数据的 server 上安装Filebeat,并指定日志目录或日志文件后,Filebeat就能读取数据,迅速发送到Logstash进行解析,亦或直接发送到 Elasticsearch进行集中式存储和分析。
0.4 常用架构
最简单的架构
在这种架构中,只有一个 Logstash、Elasticsearch 和 Kibana 实例。Logstash 通过输入插件从多种数据源(比如日志文件、标准输入 Stdin 等)获取数据,再经过滤插件加工数据,然后经 Elasticsearch 输出插件输出到 Elasticsearch,通过 Kibana 展示
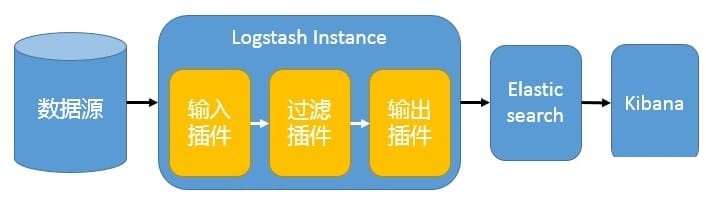
Logstash 作为日志搜集器
这种架构是对上面架构的扩展,把一个 Logstash 数据搜集节点扩展到多个,分布于多台机器,将解析好的数据发送到 Elasticsearch server 进行存储,最后在 Kibana 查询、生成日志报表等
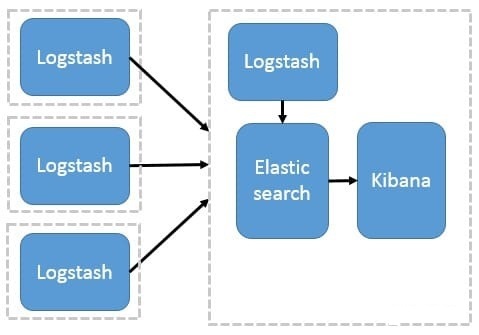
这种结构因为需要在各个服务器上部署 Logstash,而它比较消耗 CPU 和内存资源,所以比较适合计算资源丰富的服务器,否则容易造成服务器性能下降,甚至可能导致无法正常工作。
Beats 作为日志搜集器
这种架构引入 Beats 作为日志搜集器。目前 Beats包括四种:
-
Packetbeat(搜集网络流量数据); -
Topbeat(搜集系统、进程和文件系统级别的 CPU 和内存使用情况等数据); -
Filebeat(搜集文件数据); -
Winlogbeat(搜集 Windows 事件日志数据)。
Beats 将搜集到的数据发送到 Logstash,经 Logstash 解析、过滤后,将其发送到 Elasticsearch存储,并由 Kibana 呈现给用户。
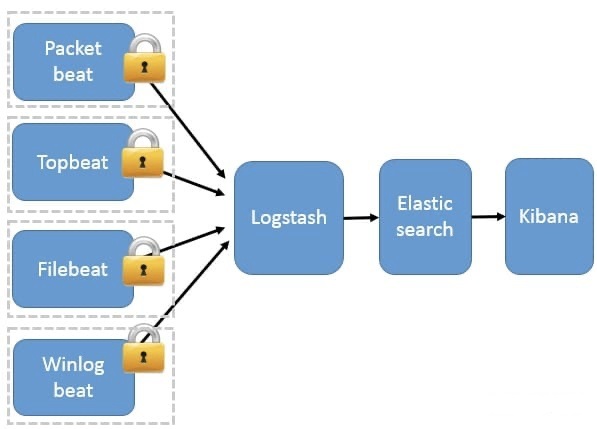
这种架构解决了 Logstash 在各服务器节点上占用系统资源高的问题。相比 Logstash,Beats 所占系统的 CPU 和内存几乎可以忽略不计。另外,Beats 和 Logstash 之间支持 SSL/TLS 加密传输,客户端和服务器双向认证,保证了通信安全。
因此这种架构适合对数据安全性要求较高,同时各服务器性能比较敏感的场景。
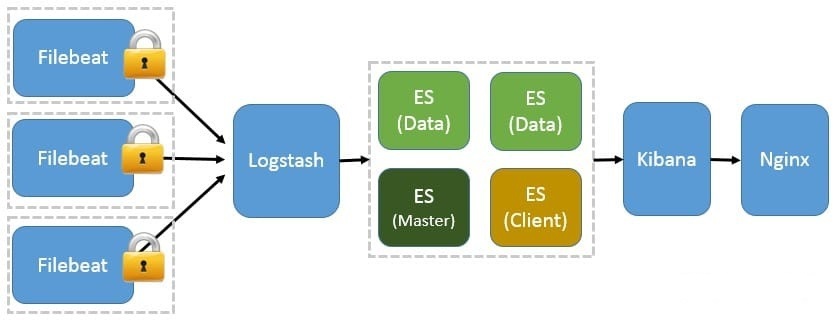
基于 Filebeat 架构的配置部署详解
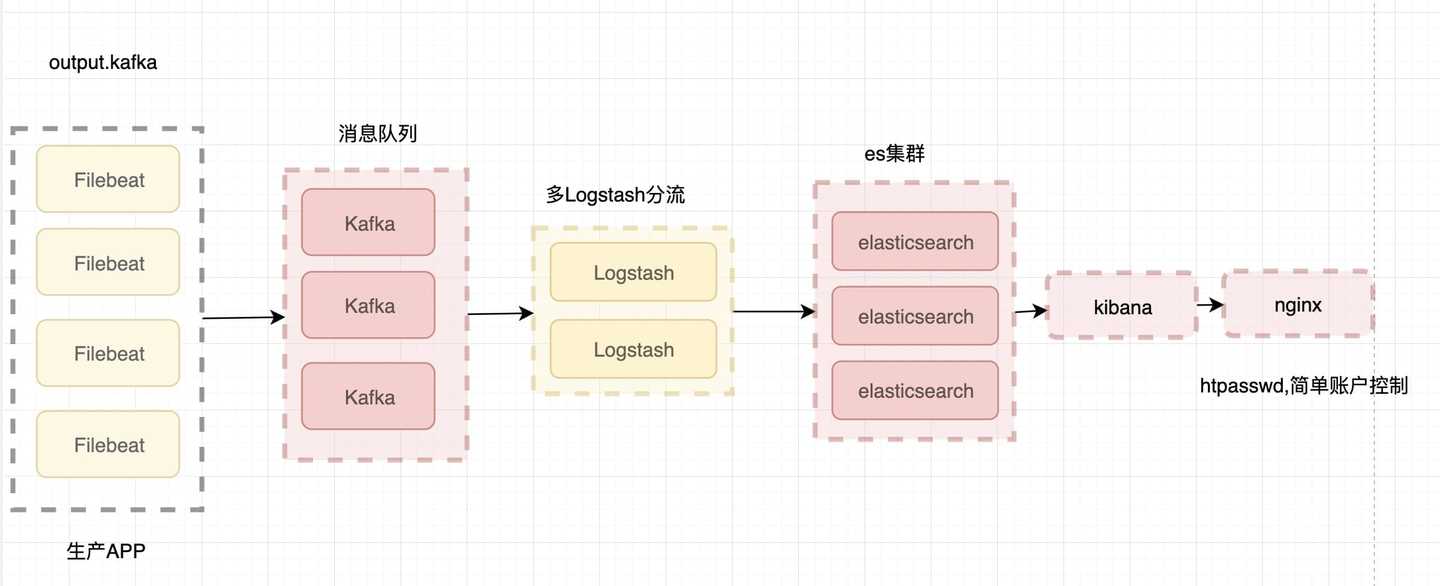
前面提到 Filebeat 已经完全替代了 Logstash-Forwarder 成为新一代的日志采集器,同时鉴于它轻量、安全等特点,越来越多人开始使用它。这个章节将详细讲解如何部署基于 Filebeat 的 ELK 集中式日志解决方案,具体架构见图 5。
图 5. 基于 Filebeat 的 ELK 集群架构
引入消息队列机制的架构
Beats 还不支持输出到消息队列,所以在消息队列前后两端只能是 Logstash 实例。这种架构使用 Logstash 从各个数据源搜集数据,然后经消息队列输出插件输出到消息队列中。目前 Logstash 支持 Kafka、Redis、RabbitMQ 等常见消息队列。然后 Logstash 通过消息队列输入插件从队列中获取数据,分析过滤后经输出插件发送到 Elasticsearch,最后通过 Kibana 展示。详见图 4。
图 4. 引入消息队列机制的架构
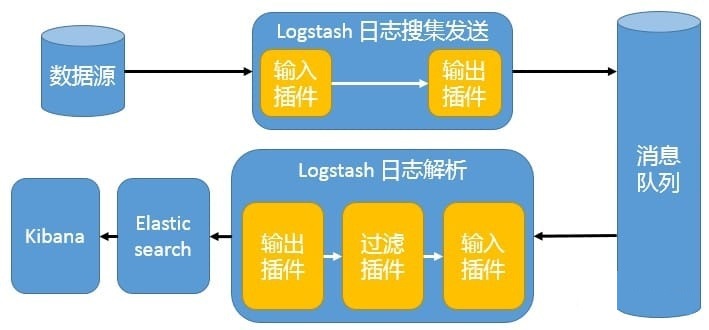
这种架构适合于日志规模比较庞大的情况。但由于 Logstash 日志解析节点和 Elasticsearch 的负荷比较重,可将他们配置为集群模式,以分担负荷。引入消息队列,均衡了网络传输,从而降低了网络闭塞,尤其是丢失数据的可能性,但依然存在 Logstash 占用系统资源过多的问题。
现市面流行的ElasticStack架构
使用的也是基于消息队列:ELK + 消息集群 + Filebeat 企业内部日志分析系统
第一章 ELKB 一键部署
1.0 环境要求
- Docker
- Docker-Compose
Docker 安装
1、检查内核版本,必须是3.10及以上
uname ‐r
2、安装docker
yum install docker
3、输入y确认安装
4、启动docker
[root@localhost ~]# systemctl start docker
[root@localhost ~]# docker ‐v
Docker version 1.12.6, build 3e8e77d/1.12.6
5、开机启动docker
[root@localhost ~]# systemctl enable docker
Created symlink from /etc/systemd/system/multi‐user.target.wants/docker.service to
/usr/lib/systemd/system/docker.service.
6、停止docker
systemctl stop docker
Docker 命令自动补全
1.安装依赖工具bash-complete
[root@localhost ~]# yum install -y bash-completion
[root@localhost ~]# source /usr/share/bash-completion/completions/docker
[root@localhost ~]# source /usr/share/bash-completion/bash_completion
Docker-Compose安装
Docker 命令自动补全
1.安装依赖工具bash-complete
[root@localhost ~]# yum install -y bash-completion
[root@localhost ~]# source /usr/share/bash-completion/completions/docker
[root@localhost ~]# source /usr/share/bash-completion/bash_completion
1.1 注意事项
-
脚本启动报错:$’\r’: command not found
-
如何解决:修改编码、赋予可执行权限
-
脚本启动报错:max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144](elasticsearch用户拥有的内存权限太小,至少需要262144)
-
如何解决:
# 修改配置sysctl.conf
[root@localhost ~]# vi /etc/sysctl.conf
# 添加下面配置:
vm.max_map_count=262144
# 重新加载:
[root@localhost ~]# sysctl -p
# 最后重新启动elasticsearch,即可启动成功。
1.2开始部署
1、下载ELK Docker Compose一键安装脚本
Docker安装ELK资源-Web开发文档类资源-CSDN下载

并把这些文件全部上传到服务器上。
2、这里我们以 /usr/local/docker/build/elk/ 作为目录,上传脚本文件

3、将 deploy.sh 以及 undeploy.sh 赋予可执行权限

4、执行部署脚本,若没有docker镜像,脚本会自动下载并且下载完毕后进行启动
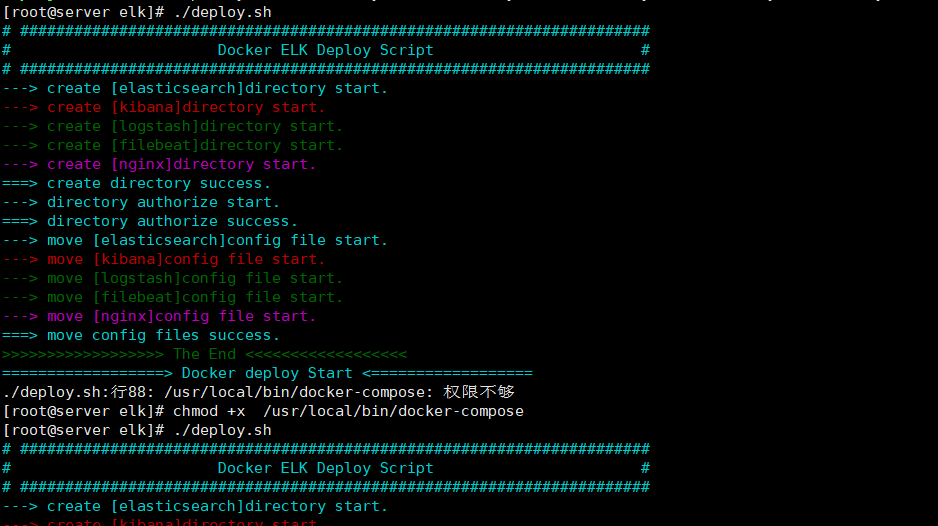
[root@localhost elk]# ./deploy.sh
1、如果出现Docker-Compose权限不足的情况,请再次给Docker-Compose授权
5、将docker使用到的相关端口逐一开启
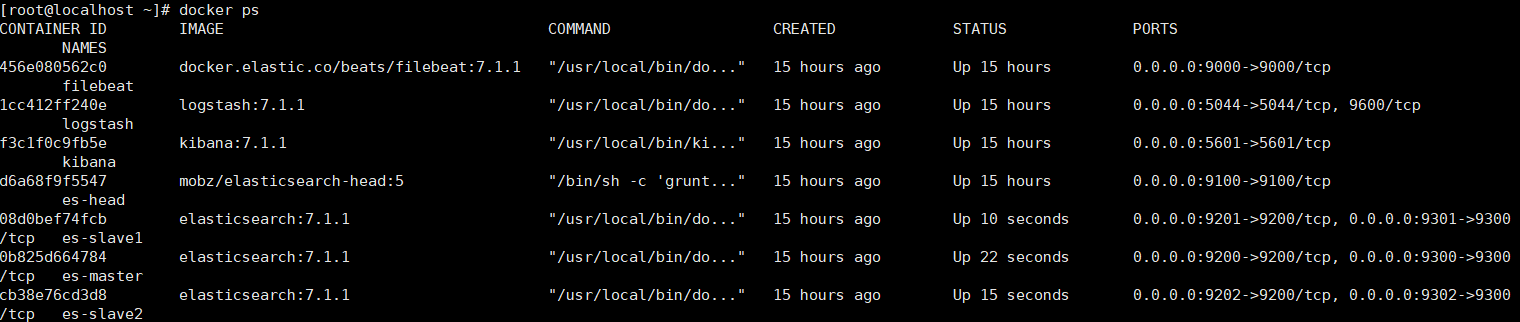
6、到此,就配置成功了,各服务之间是通过服务名称来替代hostname访问的,只支持同服务器,多服务器部署需更换服务通信地址,注上:具体Docker Compose讲解
1.3 访问界面
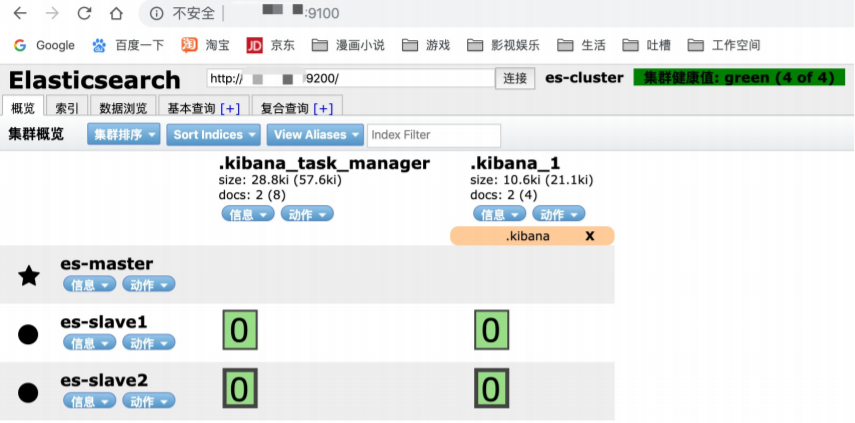
- 端口开启后,访问 http://服务器ip地址:9100 查看es集群是否成功启动
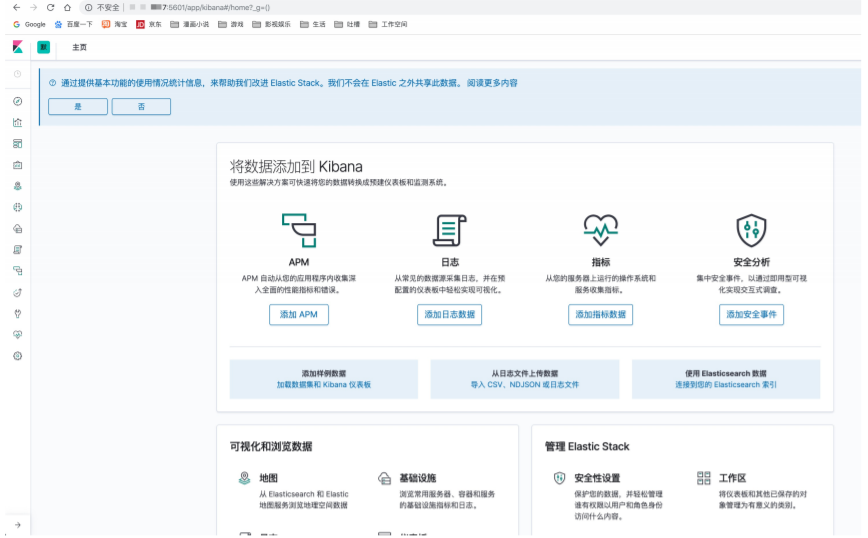
- 访问 http://服务器ip地址:5601 查看kibana是否成功启动
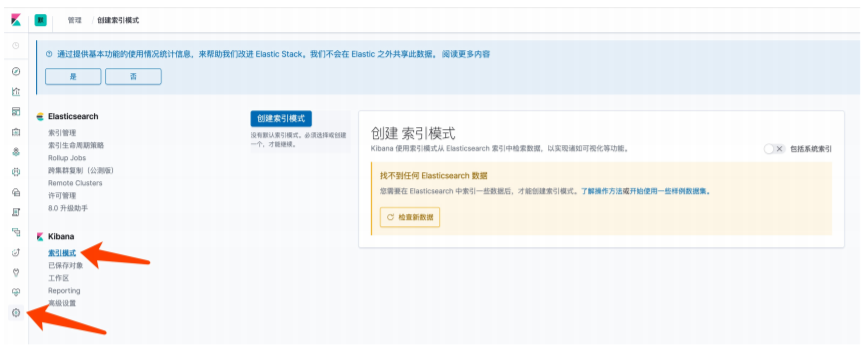
- 查看索引发现并没有数据,下一章我们将介绍进行数据对接并进行配置查询
ELK第一篇(介绍篇)结尾语:
-
我们通过docker脚本非常迅速地构建出了一个elk的单机伪集群,只要服务器配置高,足以应付一半以上的应 用场景
-
若需要多台服务器分布式部署,只需要简单改一下脚本,配置相互连接的ip即可
-
对于一些复杂场景,要安装各种插件的情况,推荐大家使用原生安装的方式,只要看明白一键部署脚本的配 置文件,相信原生安装对大家来说不成问题~
接下来就是实战了:
微服务日志对接ELB
1、Spring集成LogBack,并采用Tcp方式向Filebeat发送指定模板的日志
2、Filebeat接受消息并转向Logstash进行解析、过滤、整形日志数据
3、Filebeat解析后转向ElasticSearch进行存储
4、Kibana进行展示















 846
846











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









