







1,简述kmeans流程
随机初始化k个中心点;
计算所有样本到中心点的距离;
比较每个样本到k个中心点的距离,将样本分类到距离最近的类别中;
k个类别组成的样本点重新计算中心点(如在每一个方向上计算均值);
重复2-4,直到中心点不再变化。
2,kmeans对异常值是否敏感?为何?
K-Means算法对初始选取的聚类中心点是敏感的,不同的随机种子点得到的聚类结果完全不同
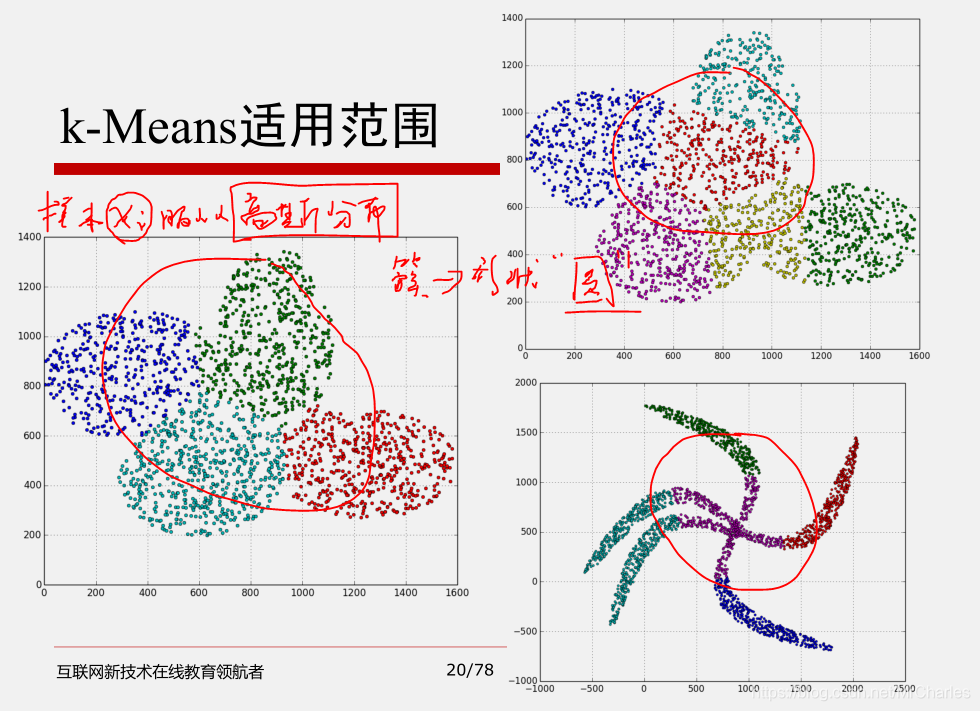
K-Means算法并不是适用所有的样本类型。它不能处理非球形簇、不同尺寸和不同密度的簇。
K-Means算法对离群点的数据进行聚类时,K均值也有问题,这种情况下,离群点检测和删除有很大的帮助。(异常值对聚类中心影响很大,需要离群点检测和剔除)
K-Means算法对噪声和离群点敏感,最重要是结果不一定是全局最优,只能保证局部最优。
3,如何评估聚类效果
我们为了能让簇内样本距离尽量的近,簇与簇之间的样本尽量的远,我们需要用以下两种指标来评价。
紧凑度
紧凑度是衡量一个簇内样本点之间的是否足够紧凑的,比如到簇中心的平均距离啊,方差啊什么的。
分离度
分离度是衡量该样本是否到其他簇的距离是否足够的远,这里边讲个很多,那11种算法的精髓也是在计算分离度,这里我就不赘述了,原本也只是将个大致意思而已,毕竟那些算法并不是作者写的。这里说说最NB的S_Dbw算法:这种算法是通过一种密度衡量公式来评价分离的好坏的。大致思路是,从所有的簇中心中至少有一个密度值要大于midpoint的密度值(这个没太懂),然后通过SD算法的紧凑度算法搞出一个权重值判断聚类的好坏(具体也没时间深究了,好用就行啊)
在 k-means 中,我们通常采用欧氏距离来衡量样本与各个 cluster 的相似度。这种距离实际上假设了数据的各个维度对于相似度的衡量作用是一样的。
评估聚类质量的四个外部标准**:纯度(Purity)**是一种简单而透明的评估手段;标准化互信息(NMI, Normalized Mutual Information)是从信息理论方面来评估;兰德指数(RI, Rand Index)能度量聚类过程中的假阳性和假阴性结果的惩罚;F值(F measure)支持调整这两种错误惩罚的权重
4,超参数k如何选择?
K值需要预先给定,属于预先知识,很多情况下K值的估计是非常困难的,对于像计算全部微信用户的交往圈这样的场景就完全的没办法用K-Means进行。对于可以确定K值不会太大但不明确精确的K值的场景,可以进行迭代运算,然后找出Cost Function最小时所对应的K值,这个值往往能较好的描述有多少个簇类。
5,kmeans算法的优缺点


BERT和GPT的异同点

LSTM算法的不足之处有哪些?




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











