










Hive数据定义
目录
前言
HiveQL是Hive查询语言。和普遍使用的所有SQL方言一样,它不完全遵守任一种ANSISQL标准的修订版。HiveQL可能和MySQL的方言最接近,但是两者还是存在显著性差异的。Hive不支持行级插入操作、更新操作和删除操作。Hive也不支持事务。Hive增加了在Hadoop背景下的可以提供更高性能的扩展,以及一些个性化的扩展,甚至还增加了一些外部程序。
Hive中的数据库
Hive中数据库的概念本质上仅仅是表的一个目录或者命名空间。然而,对于具有很多组和用户的大集群来说,这是非常有用的,因为这样可以避免表命名冲突。通常会使用数据库来将生产表组织成逻辑组。
如果用户没有显式指定数据库,那么将会使用默认的数据库default。
创建一个数据库
下面这个例子就展示了如何创建一个数据库:
-- 显示默认数据库
show databases;
-- 创建数据库
create database test;
-- 不存在才会创建数据库,防止因数据库存在而报错
create database if not exists test;
-- 查看t开头的数据库
show databases like 't.*';
-- 查看数据库详细信息
desc database test;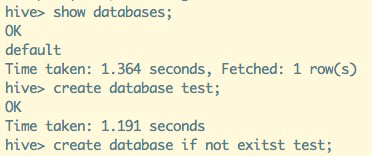


指定数据库存储路径
数据库所在的目录位于属性hive.metastore.warehouse.dir所指定的顶层目录之后。假设用户使用的是这个配置项默认的配置,也就是/user/hive/warehouse,那么当我们创建数据库test时,Hive将会对应地创建一个目录/user/hive/warehouse/test.db。
这里请注意,数据库的文件目录名是以.db结尾的。用户可以通过如下的命令来修改这个默认的位置:
create database test LOCATION'/xxx/xxx/xxx';适用场景:
公司对hdfs上的资源和存储有一定的限制的时候,我们需要在指定位置创建所需要的库和表,可以通过这种命令进行操作。
用户还可以为数据库增加一些和其相关的键值对属性信息,尽管目前仅有的功能就是提供了一种可以通过下面语句显示出信息:
describe database extended <database>
-- 创建带参数的数据库
create database test_1 with dbproperties('creator'='zhang','date'='20200102');
-- 查询数据库详细信息
desc database extended test_1;
-- 查询数据库
desc database test_1;
现在,使用像SHOWTABLES这样的命令就会显示当前这个数据库下所有的表。
不幸的是,并没有一个命令可以让用户查看当前所在的是哪个数据库!幸运的是,在Hive中是可以重复使用USE…命令的,这是因为在Hive中并没有嵌套数据库的概念。
数据库操作及表操作
-- 显示数据库
show databases;
-- 选定数据库
use test;
-- 创建表
create table a (id int) ;
-- 显示全部表
show tables;
-- 修改数据库(只可以修改属性,无法修改数据库名及存储路径)
alter database test set dbproperties("param"='ceshi');
-- 查看数据库详细信息
desc database extended test;
-- 删除数据库(无表/有表)
drop database test;
drop database test cascade;
show databases;

hive中的表
创建表
CREATE TABLE语句遵从SQL语法惯例,但是Hive的这个语句中具有显著的功能扩展,使其可以具有更广泛的灵活性。例如,可以定义表的数据文件存储在什么位置、使用什么样的存储格式,等等。前面我们在”中已经讨论了很多种存储格式,同时在稍后的我们将会再次探讨一下更加高级的格式。
CREATE TABLE IF NOT EXISTS test_1.employees(
name STRING COMMENT 'Employeename',
salary FLOAT COMMENT 'Employeesalary',
subordinates ARRAY<STRING> COMMENT 'Namesofsubordinates',
deductions MAP<STRING,FLOAT> COMMENT 'Keysaredeductionsnames,valuesarepercentages',
address STRUCT<street:STRING,city:STRING,state:STRING,zip:INT> COMMENT 'Homeaddress'
) COMMENT 'Descriptionofthetable'
TBLPROPERTIES('creator'='me','created_at'='2020010210:00:00',...)
LOCATION'/user/hive/warehouse/test_1.db/employees';首先,我们可以注意到,如果用户当前所处的数据库并非是目标数据库,那么用户是可以在表名前增加一个数据库名来进行指定的,也就是例子中的test_1。
如果用户增加上可选项IFNOTEXITS,那么若表已经存在了,Hive就会忽略掉后面的执行语句,而且不会有任何提示。在那些第一次执行时需要创建表的脚本中,这么写是非常有用的。
然而,这个语句还有一个用户需要注意的问题。如果用户所指定的表的模式和已经存在的这个表的模式不同的话,Hive不会为此做出提示。如果用户的意图是使这个表具有重新指定的那个新的模式的话,那么就需要先删除这个表,也就是丢弃之前的数据,然后再重建这张表。用户可以考虑使用一个或多个ALTER TABLE语句来修改已经存在的表的结构。有更详细的信息。
Hive会自动增加两个表属性:一个是last_modified_by,其保存着最后修改这个表的用户的用户名;另一个是last_modified_time,其保存着最后一次修改的新纪元时间秒。
Hivev0.10.0版本中有一个功能增强计划,也就是增加一个show tblproperties table_name命令,用于列举出某个表的tblproperties属性信息。
为了避免潜在产生混淆的可能性,如果用户不想使用默认的表路径,那么最好是使用外部表。
copy表结构
用户还可以拷贝一张已经存在的表的表模式(而无需拷贝数据)
CREATE TABLE IF NOT EXISTS test_1.a1 like test_1.a;
如果我们有很多的表,那么我们可以使用正则表达式来过滤出所需要的表名。
- . 表示任意一位
- * 表示任n位

内部表
我们目前所创建的表都是所谓的管理表,有时也被称为内部表。
因为这种表,Hive会(或多或少地)控制着数据的生命周期。正如我们所看见的,Hive默认情况下会将这些表的数据存储在由配置项hive.metastore.warehouse.dir(例如,/user/hive/warehouse)所定义的目录的子目录下。
当我们删除一个管理表时,Hive也会删除这个表中数据。
但是,管理表不方便和其他工作共享数据。例如,假设我们有一份由Pig或者其他工具创建并且主要由这一工具使用的数据,同时我们还想使用Hive在这份数据上执行一些查询,可是并没有给予Hive对数据的所有权,我们可以创建一个外部表指向这份数据,而并不需要对其具有所有权。
外部表
假设我们正在分析来自股票市场的数据。我们会定期地从像Infochimps(http://infochimps.com/datasets)这样的数据源接入关于NASDAQ和NYSE的数据,然后使用很多工具来分析这份数据。(我们可以看到数据集名称分别为infochimps_dataset_4777_download_16185和infochimps_dataset_4778_download_16677,实际上该数据来源于Yahoo!财经。)我们后面将要使用的模式和这2份源数据都是匹配的。
我们假设这些数据文件位于分布式文件系统的/data/stocks目录下。下面的语句将创建一个外部表,其可以读取所有位于/data/stocks目录下的以逗号分隔的数据:
-- create external table if not exists stocks
CREATE EXTERNAL TABLE IF NOT EXISTS stocks(
exchange STRING,
symbol STRING,
ymd STRING,
price_open FLOAT,
price_high FLOAT,
price_low FLOAT,
price_close FLOAT,
volume INT,
price_adj_close FLOAT
)ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
LOCATION '/data/stocks'
;
关键字extenal告诉Hive这个表是外部的,而后面的LOCATION…子句则用于告诉Hive数据位于哪个路径下。
因为表是外部的,所以Hive并非认为其完全拥有这份数据。
因此,删除该表并不会删除掉这份数据,不过描述表的元数据信息会被删除掉。
- 如果语句中省略掉EXTERNAL关键字而且源表是外部表的话,那么生成的新表也将是外部表。
- 如果语句中省略掉EXTERNAL关键字而且源表是管理表的话,那么生成的新表也将是管理表。
- 但是,如果语句中包含有EXTERNAL关键字而且源表是管理表的话,那么生成的新表将是外部表。
- 即使在这种场景下,LOCATION子句同样是可选的。
分区表
数据分区的一般概念存在已久。其可以有多种形式,但是通常使用分区来水平分散压力,将数据从物理上转移到和使用最频繁的用户更近的地方,以及实现其他目的。
Hive中有分区表的概念。我们可以看到分区表具有重要的性能优势,而且分区表还可以将数据以一种符合逻辑的方式进行组织,比如分层存储。
CREATE TABLE employees(
name STRING,
salary FLOAT,
subordinates ARRAY<STRING>,
deductions MAP<STRING,FLOAT>,
address STRUCT<street:STRING,city:STRING,state:STRING,zip:INT>
)PARTITIONED BY (country STRING,state STRING)
;分区表改变了Hive对数据存储的组织方式。如果我们是在mydb数据库中创建的这个表,那么对于这个表只会有一个employees目录与之对应,Hive现在将会创建好可以反映分区结构的子目录,如下:

分区字段(这个例子中就是country和state)一旦创建好,表现得就和普通的字段一样。这里有一个已知的异常情况,是由一个bug引起的。事实上,除非需要优化查询性能,否则使用这些表的用户不需要关心这些“字段”是否是分区字段。
例如,下面这个查询语句将会查找出在美国伊利诺斯州的所有雇员:
SELECT * FROM employees WHERE country='US' AND state='IL';需要注意的是,因为country和state的值已经包含在文件目录名称中了,所以也就没有必要将这些值存放到它们目录下的文件中了。事实上,数据只能从这些文件中获得,因此用户需要在表的模式中说明这点,而且这个数据浪费空间。
如果用户需要做一个查询,查询对象是全球各地的所有员工,那么这也是可以做到的。Hive会不得不读取每个文件目录,但这种宽范围的磁盘扫描还是比较少见的。
但是,如果表中的数据以及分区个数都非常大的话,执行这样一个包含有所有分区的查询可能会触发一个巨大的MapReduce任务。一个高度建议的安全措施就是将Hive设置为“strict(严格)”模式,这样如果对分区表进行查询而WHERE子句没有加分区过滤的话,将会禁止提交这个任务。
用户也可以按照下面的语句将属性值设置为“nostrict(非严格)”:
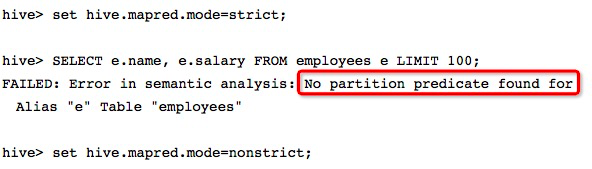
show partitions employees;
show partitions employees(country='US');
show partitions employees(country='US',state='AK');
describe extended employees;
-- 往分区表中加载数据
LOAD DATA LOCAL INPATH '/opt/datas/xxx.csv' INTO TABLE employees PARTITION (country="xxx",state="xxx"); 外部分区表
外部表同样可以使用分区。事实上,用户可能会发现,这是管理大型生产数据集最常见的情况。这种结合给用户提供了一个可以和其他工具共享数据的方式,同时也可以优化查询性能。
我们举一个新例子,非常适合这种场景,即日志文件分析。对于日志信息,大多数的组织使用一个标准的格式,其中记录有时间戳、严重程度(例如ERROR、WARTING、INFO),也许还包含有服务器名称和进程ID,然后跟着一个可以为任何内容的文本信息。假设我们是在我们的环境中进行数据抽取、数据转换和数据装载过程(ETL),以及日志文件聚合过程的,将每条日志信息转换为按照制表键分割的记录,并将时间戳解析成年、月和日3个字段,剩余的hms部分(也就是时间戳剩余的小时、分钟和秒部分)作为一个字段,因为这样显得清楚多了。一种方式是用户可以使用Hive或者Pig内置的字符串解析函数来完成这个日志信息解析过程。另一种方式是,我们可以使用较小的数值类型来保存时间戳相关的字段以节省空间。这里,我们没有采用后面的解决办法。
我们可以按照如下方式来定义对应的Hive表:
CREATE EXTERNAL TABLE IF NOT EXISTS log_messages(
hms INT,
severity STRING,
server STRING,
process_id INT,
message STRING
)PARTITIONED BY (year INT,month INT,day INT)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
;
我们现在假定将日志数据按照天进行划分,划分数据尺寸合适,而且按天这个粒度进行查询速度也足够快。
ALTER TABLE语句可以单独进行增加分区。这个语句需要为每一个分区键指定一个值,也就是需要为year、month和day这3个分区键都指定值。下面是一个例子,演示如何增加一个2020年1月2日的分区:
ALTER TABLE log_messages ADD PARTITION (year=2020,month=1,day=2)
LOCATION 'hdfs://xxx/data/log_messages/2020/01/02'
;Hive不关心一个分区对应的分区目录是否存在或者分区目录下是否有文件。如果分区目录不存在或分区目录下没有文件,则对于这个过滤分区的查询将没有返回结果。当用户想在另外一个进程开始往分区中写数据之前创建好分区时,这样做是很方便的。数据一旦存在,对于这份数据的查询就会有返回结果。
这个功能所具有的另一个好处是:可以将新数据写入到一个专用的目录中,并与位于其他目录中的数据存在明显的区别。同时,不管用户是将旧数据转移到一个“存档”位置还是直接删除掉,新数据被篡改的风险都被降低了,因为新数据的数据子集位于不同的目录下。
和非分区外部表一样,Hive并不控制这些数据。即使表被删除,数据也不会被删除。
和分区管理表一样,通过SHOW PARTITIONS命令可以查看一个外部表的分区
分区增删修改操作
-- 添加分区
alter table xxx add partition(xxx='xxx',yyy='xxx') location '/user/xxx';
-- 加载hdfs上数据到xxx表中
load data inpath 'xxx' overwrite into table xxx partition(xxx='xxx',yyy='xxx');
-- 删除分区
alter table xxx drop partition(xxx='xxx');
-- 修改分区
ALTER TABLE table_name PARTITION (dt='xxx') RENAME TO PARTITION (dt='yyy');
删除表操作
Hive支持和SQL中DROPTABLE命令类似的操作:
DROP TABLE IF EXISTS employees;事实上,如果用户开启了Hadoop回收站功能(这个功能默认是关闭的),那么数据将会被转移到用户在分布式文件系统中的用户根目录下的.Trash目录下,也就是HDFS中的/user/$USER/.Trash目录。如果想开启这个功能,只需要将配置属性fs.trash.interval的值设置为一个合理的正整数即可。这个值是“回收站检查点”间的时间间隔,单位是分钟。因此如果设置值为1440,那么就表示是24小时。不过并不能保证所有的分布式系统以及所有版本都是支持的这个功能的。如果用户不小心删除了一张存储着重要数据的管理表的话,那么可以先重建表,然后重建所需要的分区,再从.Trash目录中将误删的文件移动到正确的文件目录下(使用文件系统命令)来重新存储数据。
对于外部表,表的元数据信息会被删除,但是表中的数据不会被删除。
下面列了一些操作,可能不够全面吧,但是命令太多了,也不可能全部搞出来。(慢慢补充吧,哈哈...)
-- 修改表名a 改为b
alter table a rename to b;
-- 重置分区路径
ALTER TABLE log_xx PARTITION (year=xxx,month=xx,day=x)
SET LOCATION 'xxx';
-- 增加列,删除列,修改列-列属性 更新列及属性名等操作
ALTER TABLE name ADD COLUMNS (col_spec[, col_spec ...])
ALTER TABLE name DROP [COLUMN] column_name
ALTER TABLE name CHANGE column_name new_name new_type
ALTER TABLE name REPLACE COLUMNS (col_spec[, col_spec ...])
-- 修改列情况
ALTER TABLE table_name CHANGE
[CLOUMN] col_old_name col_new_name column_type
[CONMMENT col_conmment]
[FIRST|AFTER column_name];
-- 例子
ALTER TABLE xxx CHANGE col1 col2 STRING COMMENT 'The datatype of col2 is STRING' AFTER col3;
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











