






这里推荐哔站狂神视频,也是文章的部分来源。也包括Redis中文网。
哔哩哔哩狂神说
Redis中文官方网站
Redis官网
Redis 是一个开源的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。 支持多种类型的数据结构,如字符串(String), 散列(Hash), 列表 (List),集合(Set), 有序集合(Zset)与范围查询, bitmaps, hyperloglogs和地理空间(geospatial)索引半径查询。 Redis 内置了复制(replication),LUA脚本(Lua scripting),LRU驱动事件(LRU eviction),事务 (transactions)和不同级别的磁盘持久化(persistence), 并通过Redis哨兵和自动分区提供高可用性。
Redis的特性
- 多样的数据类型
- 持久化
- 集群
- 事务
启动Redis
Redis的启动,这里用的是本机上的Windows版本。进入到Redis的安装目录,然后找到我们的redis-server.exe双击启动Redis,然后打开redis-cli.exe,可以看到本地的Redis服务已经打开,并且已经连接上了。
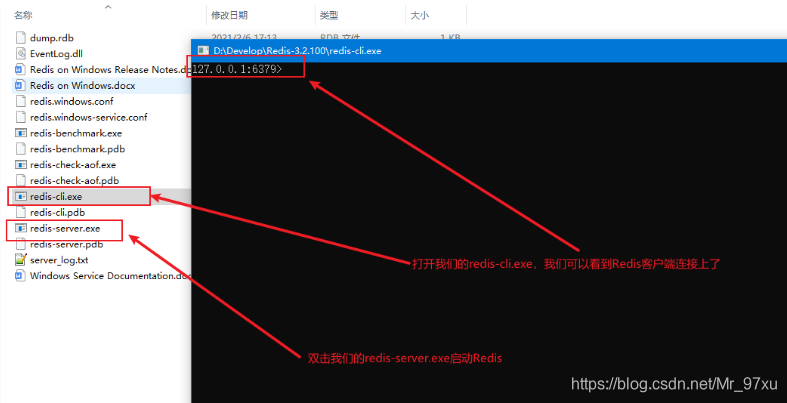
除此之外,也可以通过命令启动Redis服务。
首先需要先进入到Redis的安装目录。然后输入以下命令:
- 输入以下命令,我们打开我们的服务,可以看到Redis服务
redis-server --service-install redis.windows-service.conf --loglevel verbose
- 输入以下命令,启动Redis服务
redis -server.exe redis.conf
Redis基础
Redis默认有16个数据库,默认使用的是第一个。这里的第一个在Redis数据库中的索引是0。
Redis基础命令
# 我们可以通过 select 进行切换数据库。
select 0
select 1
select 2
...
select 15
# 通过 DBSIZE 查看数据库大小
DBSIZE
# 查看数据库所有的 key
keys *
# 清除当前数据库
flushdb
# 清除全部数据库的内容
flushall
# 设置 key 的过期时间(这里以名为 sex 的 key 5秒过期为例)
expire sex 5
# 移除当前的 key(这里以名为 name 的 key 为例)
move name 1
# 判断当前的 key 是否存在(这里以名为 name 的 key 为例)
exists name
# 查看当前 key 的剩余时间(这里以名为 name 的 key 为例)
ttl name
# 查看当前 key 是什么类型的(这里以名为 name 的 key 为例)
type name
Redis为什么速度快?
Redis 是单线程的,是基于内存的操作的缓存数据库。
Redis 是将所有的数据全部放在内存中的,所以使用单线程操作的效率是最高的,多线程CPU的上下文切换,会有切换的耗时操作,对于内存系统来说,没有上下文切换,效率就是最高的,多次的读写都是在一个CPU上进行的。
Redis 的五大数据类型(String、List、Set、Hash、Zset)
这里通过实际操作Redis的命令来学习Redis的五大数据类型。
String(字符串)
# 设置 name 为 zhangsan
set name zhangsan
# 在 name 后面追加 hello 字符串
append name "hello"
# 获取 name 的长度
strlen name
# 设置 number 为 0
set number 0
# 自增1
incr number
# 自减1
decr number
# 指定增量,自增10
incrby number 10
# 指定减量,自减10
decrby number 10
# 根据范围截取字符串
getrange name 0 2
# 替换指定位置开始的字符串
setrange name 1 xxx
# 设置key hello的过期时间为30秒
setex key 30 "hello"
# 如果key不存在设置key,如果key存在则创建失败
setnx mykey "hello"
# 批量设置多个key
mset key1 value1 key2 value2 key3 value3
# 批量获取多个key
mget key1 key2 key3
# msetnx是一个原子性的操作,要么同时成功要么同时失败
msetnx key1 value1 key2 value2 key3 value3
# 如果值不存在,返回nil,如果值存在,获取原来的值,并设置新的值
getset key1 value1
List(列表)
# 将一个值或者多个值插入到列表头部(左)
lpush list2 one two three
# 将一个值或多个值插入到列表的尾部(右)
rpush list fore
# 获取list2列表中的所有值
lrange list2 0 -1
# 通过区间获取具体的值
lrange list2 0 2
# 移除命令,左侧移除
lpop list2
# 移除命令,右侧移除
rpop list2
# 通过下标获取list元素中的某一个值
lindex list 2
# 返回列表的长度
llen list
# 移除指定的元素
lrem list 1 one
# 截断,通过下标截取指定的长度,list只剩下了截取的元素
ltrim mylist 1 2
# 将list中原来的位置的元素更新为新的元素
lset list 1 zhang
# 将某个具体的值插入到某个元素的前面
linsert mylist before "hello" "how"
# 将某个具体的值插入到某个元素的后面
linsert mylist after "hello" "new"
Set(集合)
# 向set集合中添加元素
127.0.0.1:6379[2]> sadd myset hello
(integer) 1
127.0.0.1:6379[2]> sadd myset world
(integer) 1
# 查看集合中的所有元素
127.0.0.1:6379[2]> smembers myset
1) "hello"
2) "world"
# 判断集合中是否存在该元素
127.0.0.1:6379[2]> sismember myset hello
(integer) 1
127.0.0.1:6379[2]> sismember myset a
(integer) 0
# 获取集合中元素的个数
127.0.0.1:6379[2]> scard myset
(integer) 2
127.0.0.1:6379[2]> sadd myset how
(integer) 1
127.0.0.1:6379[2]> scard myset
(integer) 3
127.0.0.1:6379[2]> smembers myset
1) "hello"
2) "world"
3) "how"
# 移除集合中的指定元素
127.0.0.1:6379[2]> srem myset world
(integer) 1
127.0.0.1:6379[2]> smembers myset
1) "hello"
2) "how"
127.0.0.1:6379[2]> scard myset
(integer) 2
# 随机获取集合中的一个元素
127.0.0.1:6379[2]> srandmember myset
"hello"
127.0.0.1:6379[2]> srandmember myset
"hello"
127.0.0.1:6379[2]> srandmember myset
"hello"
127.0.0.1:6379[2]> srandmember myset
"hello"
127.0.0.1:6379[2]> sadd myset are
(integer) 1
127.0.0.1:6379[2]> sadd myset you
(integer) 1
127.0.0.1:6379[2]> sadd myset love
(integer) 1
127.0.0.1:6379[2]> smembers myset
1) "you"
2) "hello"
3) "are"
4) "how"
5) "love"
127.0.0.1:6379[2]> srandmember myset
"hello"
127.0.0.1:6379[2]> srandmember myset
"are"
127.0.0.1:6379[2]> srandmember myset
"how"
# 随机获取集合中的两个元素
127.0.0.1:6379[2]> srandmember myset 2
1) "hello"
2) "love"
127.0.0.1:6379[2]> srandmember myset 2
1) "hello"
2) "you"
127.0.0.1:6379[2]> srandmember myset 2
1) "love"
2) "are"
127.0.0.1:6379[2]> smembers myset
1) "hello"
2) "you"
3) "love"
4) "how"
5) "are"
# 随机删除集合中的一个元素
127.0.0.1:6379[2]> spop myset
"are"
127.0.0.1:6379[2]> smembers myset
1) "hello"
2) "you"
3) "love"
4) "how"
127.0.0.1:6379[2]> spop myset
"how"
127.0.0.1:6379[2]> smembers myset
1) "hello"
2) "you"
3) "love"
127.0.0.1:6379[2]> sadd myset2 a
(integer) 1
127.0.0.1:6379[2]> sadd myset2 b
(integer) 1
127.0.0.1:6379[2]> smembers myset2
1) "b"
2) "a"
# 将一个集合中的某个指定的元素移到另一个集合中
127.0.0.1:6379[2]> smove myset myset2 hello
(integer) 1
127.0.0.1:6379[2]> smembers myset
1) "you"
2) "love"
127.0.0.1:6379[2]> smembers myset2
1) "hello"
2) "b"
3) "a"
127.0.0.1:6379[2]> sadd myset a
(integer) 1
127.0.0.1:6379[2]> sadd myset b
(integer) 1
127.0.0.1:6379[2]> sadd myset c
(integer) 1
127.0.0.1:6379[2]> sadd myset d
(integer) 1
127.0.0.1:6379[2]> sadd myset2 e
(integer) 1
127.0.0.1:6379[2]> sadd myset2 f
(integer) 1
127.0.0.1:6379[2]> smembers myset
1) "you"
2) "love"
3) "c"
4) "b"
5) "d"
6) "a"
127.0.0.1:6379[2]> smembers myset2
1) "e"
2) "hello"
3) "b"
4) "a"
5) "f"
# 获取两个集合中不同的元素
127.0.0.1:6379[2]> sdiff myset myset2
1) "love"
2) "you"
3) "d"
4) "c"
# 获取两个集合中共有的元素
127.0.0.1:6379[2]> sinter myset myset2
1) "b"
2) "a"
Hash(哈希)
# 向hash中添加元素
127.0.0.1:6379[3]> hset myhash name zhang
(integer) 1
# 获取hash中的元素
127.0.0.1:6379[3]> hget myhash name
"zhang"
127.0.0.1:6379[3]> hset myhash name wang
(integer) 0
127.0.0.1:6379[3]> hget myhash name
"wang"
127.0.0.1:6379[3]> hset myhash age 22
(integer) 1
127.0.0.1:6379[3]> hset myhash sex man
(integer) 1
127.0.0.1:6379[3]> hget myhash sex
"man"
# 获取全部的数据
127.0.0.1:6379[3]> hgetall myhash
1) "name"
2) "wang"
3) "age"
4) "22"
5) "sex"
6) "man"
# 删除hash指定的字段
127.0.0.1:6379[3]> hdel myhash age
(integer) 1
127.0.0.1:6379[3]> hgetall myhash
1) "name"
2) "wang"
3) "sex"
4) "man"
# 获取hash表的字段数量
127.0.0.1:6379[3]> hlen myhash
(integer) 2
# 批量添加数据
127.0.0.1:6379[3]> hmset myhash name1 li name2 zhao name3 zhang
OK
127.0.0.1:6379[3]> hgetall myhash
1) "name"
2) "wang"
3) "sex"
4) "man"
5) "name1"
6) "li"
7) "name2"
8) "zhao"
9) "name3"
10) "zhang"
# 判断hash表中是否存在该字段
127.0.0.1:6379[3]> hexists myhash name
(integer) 1
127.0.0.1:6379[3]> hexists myhash age
(integer) 0
# 获取所有的的key
127.0.0.1:6379[3]> hkeys myhash
1) "name"
2) "sex"
3) "name1"
4) "name2"
5) "name3"
# 获取所有的value
127.0.0.1:6379[3]> hvals myhash
1) "wang"
2) "man"
3) "li"
4) "zhao"
5) "zhang"
127.0.0.1:6379[3]> hset myhash age 2
(integer) 1
# 指定增量
127.0.0.1:6379[3]> hincrby myhash age 1
(integer) 3
127.0.0.1:6379[3]> hincrby myhash age 4
(integer) 7
Zset(有序集合)
# 添加用户
127.0.0.1:6379[4]> zadd salary 2500 zhang
(integer) 1
127.0.0.1:6379[4]> zadd salary 4000 li
(integer) 1
127.0.0.1:6379[4]> zadd salary 500 wang
(integer) 1
# 从小到大排序,显示所有的用户
127.0.0.1:6379[4]> zrangebyscore salary -inf +inf
1) "wang"
2) "zhang"
3) "li"
127.0.0.1:6379[4]> zadd myset 1 a
(integer) 1
127.0.0.1:6379[4]> zadd myset 3 b
(integer) 1
127.0.0.1:6379[4]> zadd myset 2 c
(integer) 1
127.0.0.1:6379[4]> zrange myset 0 -1
1) "a"
2) "c"
3) "b"
# 显示所有用户,并且附带工资
127.0.0.1:6379[4]> zrangebyscore salary -inf +inf withscores
1) "wang"
2) "500"
3) "zhang"
4) "2500"
5) "li"
6) "4000"
# 显示工资小于等于2500的用户
127.0.0.1:6379[4]> zrangebyscore salary -inf 2500 withscores
1) "wang"
2) "500"
3) "zhang"
4) "2500"
127.0.0.1:6379[4]> zrange salary 0 -1
1) "wang"
2) "zhang"
3) "li"
# 移除有序集合中的指定元素
127.0.0.1:6379[4]> zrem salary wang
(integer) 1
127.0.0.1:6379[4]> zrange salary 0 -1
1) "zhang"
2) "li"
# 获取有序集合中的个数
127.0.0.1:6379[4]> zcard salary
(integer) 2
# 从大到小排序
127.0.0.1:6379[4]> zrevrange salary 0 -1
1) "li"
2) "zhang"
3) "zhao"
4) "wang"
# 获取指定区间的成员数量
127.0.0.1:6379[4]> zcount salary 1000 4000
(integer) 3
Redis 的三种特殊的数据类型(Geospatial、Hyperloglog、Bitmaps)
除了基本的数据类型以外,Redis还有另外三种特殊的数据类型。
Geospatial 地理位置
GEOADD
GEODIST
GEOHASH
GEOPOS
GEORADIUS
GEORADIUSBYMEMBER
# 添加地理位置
127.0.0.1:6379[5]> geoadd china:city 116.40 39.90 beijing
(integer) 1
127.0.0.1:6379[5]> geoadd china:city 121.47 31.23 shanghai
(integer) 1
127.0.0.1:6379[5]> geoadd china:city 106.50 29.53 chongqing
(integer) 1
# 获取经纬度
127.0.0.1:6379[5]> geopos china:city beijing
1) 1) "116.39999896287918"
2) "39.900000091670925"
# 获取多个城市的地理位置
127.0.0.1:6379[5]> geopos china:city beijing shanghai chongqing
1) 1) "116.39999896287918"
2) "39.900000091670925"
2) 1) "121.47000163793564"
2) "31.229999039757836"
3) 1) "106.49999767541885"
2) "29.529999579006592"
# 获取两个城市的距离
127.0.0.1:6379[5]> geodist china:city beijing shanghai
"1067378.7564"
# 获取两个城市的距离 单位km
127.0.0.1:6379[5]> geodist china:city beijing shanghai km
"1067.3788"
# 以110 30经纬度为中心,寻找方圆5000km以内的城市(所有的数据应该在china:city中)
127.0.0.1:6379[5]> georadius china:city 110 30 5000 km
1) "chongqing"
2) "shanghai"
3) "beijing"
# 显示到中间位置的距离
127.0.0.1:6379[5]> georadius china:city 110 30 3000 km withdist
1) 1) "chongqing"
2) "341.9374"
2) 1) "shanghai"
2) "1105.9098"
3) 1) "beijing"
2) "1245.2858"
# 显示范围内其他城市的定位信息
127.0.0.1:6379[5]> georadius china:city 110 30 3000 km withcoord
1) 1) "chongqing"
2) 1) "106.49999767541885"
2) "29.529999579006592"
2) 1) "shanghai"
2) 1) "121.47000163793564"
2) "31.229999039757836"
3) 1) "beijing"
2) 1) "116.39999896287918"
2) "39.900000091670925"
# 找出位于指定位置周围的其他位置
127.0.0.1:6379[5]> georadiusbymember china:city beijing 3000 km
1) "chongqing"
2) "shanghai"
3) "beijing"
# 查看地图中所有的元素
127.0.0.1:6379[5]> zrange china:city 0 -1
1) "chongqing"
2) "shanghai"
3) "beijing"
# 移除指定元素
127.0.0.1:6379[5]> zrem china:city shanghai
(integer) 1
127.0.0.1:6379[5]> zrange china:city 0 -1
1) "chongqing"
2) "beijing"
Hyperloglog
简介
Redis Hyperloglog 基数统计的算法。
优点
占用的内存是固定的,占用内存小。
# 创建第一组元素mykey
127.0.0.1:6379[6]> pfadd mykey a b c d e f
(integer) 1
# 统计mykey中元素基数数量
127.0.0.1:6379[6]> pfcount mykey
(integer) 6
127.0.0.1:6379[6]> pfadd mykey a b g
(integer) 1
127.0.0.1:6379[6]> pfcount mykey
(integer) 7
127.0.0.1:6379[6]> pfadd mykey2 y u i o
(integer) 1
# 合并两组元素到mykey3(并集)
127.0.0.1:6379[6]> pfmerge mykey3 mykey mykey2
OK
127.0.0.1:6379[6]> pfcount mykey3
(integer) 11
注意: 由于Hyperloglog有0.81%的错误率。如果允许容错,就可以使用Hyperloglog
Bitmaps
位存储
Bitmaps位图,数据结构,都是操作的二进制来进行记录的。就只有 0 和 1 两个状态。
127.0.0.1:6379[7]> setbit sign 0 1
(integer) 0
127.0.0.1:6379[7]> setbit sign 1 1
(integer) 0
127.0.0.1:6379[7]> setbit sign 2 1
(integer) 0
127.0.0.1:6379[7]> setbit sign 4 1
(integer) 0
127.0.0.1:6379[7]> setbit sign 3 1
(integer) 0
127.0.0.1:6379[7]> setbit sign 5 0
(integer) 0
# 查看
127.0.0.1:6379[7]> getbit sign 3
(integer) 1
127.0.0.1:6379[7]> getbit sign 5
(integer) 0
Redis的事务
Redis事务本质:一组命令的集合。一个事务中的所有命令都会被序列化。在事务执行的过程中,会按照顺序执行。
Redis事务具有:一次性、顺序性、排他性。
Redis的事务没有隔离级别的概念。
Redis的单条命令是保存原子性的,但是事务不保证原子性。
Redis的事务操作:
- 开启事务(multi)
- 命令入队(…)
- 执行事务(exec)
# 开启事务
127.0.0.1:6379[8]> multi
OK
# 命令入队
127.0.0.1:6379[8]> set k1 v1
QUEUED
127.0.0.1:6379[8]> set k2 v2
QUEUED
127.0.0.1:6379[8]> get k2
QUEUED
127.0.0.1:6379[8]> set k3 v3
QUEUED
127.0.0.1:6379[8]> get k3
QUEUED
# 执行事务
127.0.0.1:6379[8]> exec
1) OK
2) OK
3) "v2"
4) OK
5) "v3"
放弃事务
# 开启事务
127.0.0.1:6379[8]> multi
OK
127.0.0.1:6379[8]> set k1 v1
QUEUED
127.0.0.1:6379[8]> set k2 v2
QUEUED
127.0.0.1:6379[8]> set k4 v4
QUEUED
# 放弃事务
127.0.0.1:6379[8]> discard
OK
Redis锁
悲观锁:
- 很悲观,认为任何时候都会出现问题,无论做什么都会加锁。
乐观锁:
- 很乐观,认为什么时候都不会出问题,所以不会上锁。在更新数据的时候判断一下,在此期间该数据是否有人修改过该数据。
- 获取version
- 更新的时候比较version
Redis的持久化(重点)
由于Redis是基于内存的数据库,如果不进行数据库持久化操作,服务器进程退出以后,服务器中的数据库状态也会消失。
Redis的两种持久化方式:RDB(Redis DataBase) 和 AOF(Append Only File)。
RDB(Redis DataBase)
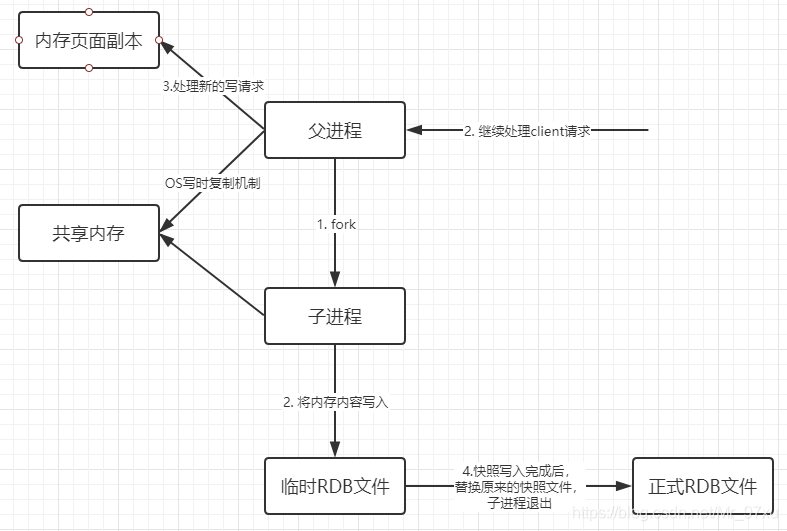
在指定的时间间隔中,将内存中的数据以快照的方式写入磁盘。数据恢复的时候,直接将快照文件读到内存里。
RDB 保存的文件是 dump.rdb。
触发机制:
- save 的规则满足的情况下,会自动触发 rdb 规则。
- 执行 flushall 命令,也会触发 rdb 规则。
- 退出 redis,也会产生 rdb 文件。
AOF(Append Only File)
将我们的所有的命令都记录下来。
恢复的时候,将此文件全部执行一次。
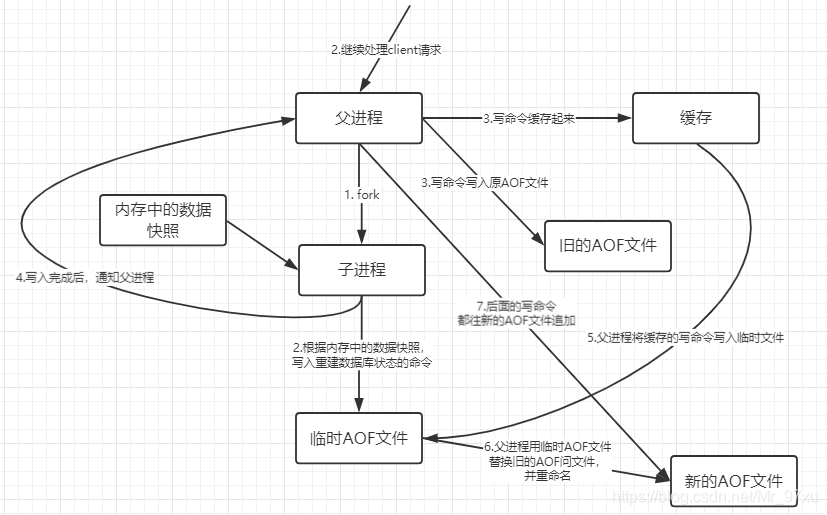 以日志的形式,记录每一个写的操作。将Redis的所有的指令记录下来,只能够追加文件,不能改写文件。Redis启动的时候,会读取该文件重新构建数据库。
以日志的形式,记录每一个写的操作。将Redis的所有的指令记录下来,只能够追加文件,不能改写文件。Redis启动的时候,会读取该文件重新构建数据库。
Redis主从复制
Redis从服务器(slave)能够精确的得到并且复制Redis主服务器(master)上的数据内容。当从服务器(slave)和主服务器(master)之间断开连接的时候,从服务器(slave)会自动的和主服务器(master)重新建立连接。这期间主服务器(master)产生的数据的改变,从服务器(slave)都会重新复制到自身。
举个例子:
- 启动一台Redis作为主服务器(master)
# 启动Redis redis-server --port 8000 redis-cli -p 8000 # 向Redis中写入数据 127.0.0.1:8000> set msg doni OK 127.0.0.1:8000> get msg "doni" - 再启动一台Redis作为从服务器(slave)
# 启动Redis redis-server --port 8001 redis-cli -p 8000 # 查看数据时,数据为空 127.0.0.1:8001> get msg (nil) - 我们将主服务器(master)中的数据复制到从服务器(slave)
# 数据复制 127.0.0.1:8001> slaveof 127.0.0.1 8000 # 查看数据 127.0.0.1:8001> get msg "doni"
https://www.cnblogs.com/hongmoshui/p/10594639.html
主从复制还需要依靠三个重要的机制:
- 主服务器(master)和从服务器(slave)连接正常的时候,主服务器(master)会向从服务器(slave)发送一连串的命令流来保持对从服务器(slave)的更新。将自身的数据集的改变复制给从服务器(slave)。包括客户端的写入、key的过期或者被逐出等等。
- 当主服务器(master)和从服务器(slave)因为网络问题、或者是主从意识到连接超时,导致断开连接的时候。从服务器(slave)重新连接上主服务器(master)时,并尝试进行部分重同步。
- 当无法进行部分重同步的时候,从服务器(slave)会进行全量同步。这个时候主服务器(master)需要创建所有的数据快照,发送给从服务器(slave),之后在数据集进行更改的时候持续发送命令流到从服务器(slave)。
Redis默认使用的是异步复制,具有低延迟和高性能的特点,是绝大多数Redis用例的自然复制模式。
注意
- Redis使用的是异步复制,从服务器(slave)和主服务器(master)之间异步的确认处理的数据量。
- 一个主服务器(master)可以拥有多个从服务器(slave)。
- 从服务器(slave)可以接收其他从服务器(slave)的连接。
在使用Redis复制功能时的设置中,在主服务器(master)和从服务器(slave)中启用持久化,
Redis为什么会有主从复制
虽然Redis是基于内存的数据库,读取写入的速度都特别快。但是在大量访问数据库的时候,还是会产生读取压力特别大的情况。为了分担读取的压力,Redis支持主从复制。Redis主从复制可以分为全量同步和增量同步。
全量同步
- 从服务器(slave)连接主服务器(master),发送SYNC命令。
- 主服务器(master)接收到SYNC命令后,开始执行BGSAVE命令生成RDB文件并使用缓冲区记录此后执行的所有写命令。
- 主服务器(master)BGSAVE执行完毕之后,向所有的从服务器(slave)发送快照文件,并在发送期间继续记录被执行的写命令。
- 从服务器(slave)收到快照文件后,丢弃所有的旧数据,载入收到的快照。
- 主服务器(master)快照发送完毕后开始向从服务器(slave)发送缓冲区中的写命令。
- 从服务器(slave)完成对快照的载入,开始接收命令请求,并执行来自主服务器(master)此时可以接收来自用户的读请求。
增量同步
Redis的增量同步指的是从服务器(slave)初始化后开始正常工作时,主服务器(master)发生的写操作同步到从服务器的过程。
增量同步的过程主要是主服务器(master)每执行一个写命令就会向从服务器(slave)发送相同的写命令,从服务器(slave)接收并执行收到的写命令。
Redis的主从同步策略
主服务器(master)和从服务器刚开始进行连接的时候,进行全量同步;全量同步完成以后,进行增量同步。
如果是在需要的情况下,从服务器(slave)会在任何时候都发起全量同步。
Redis主从复制的特点
- 主服务器(master)可以有多个从服务器(slave)。
- 除了多个从服务器(slave)连到相同的主服务器(master)外,从服务器(slave)也可以连接其他从服务器(slave)形成图状结构。
- 主从复制不会阻塞主服务器(master)当一个或多个从服务器(slave)与主服务器(master)进行初次同步数据时,主服务器(master)可以继续处理client发来的请求。相反,从服务器(slave)在初次同步数据时则会阻塞不能处理client的请求。
- 主从复制可以用来提高系统的可伸缩性,我们可以用多个从服务器(slave)专门用于client的读请求,比如sort操作可以使用从服务器(slave)来处理。也可以用来做简单的数据冗余。
- 可以在主服务器(master)禁用数据持久化,只需要注释掉主服务器(master)配置文件中的所有save配置,然后只在从服务器(slave)上配置数据持久化。
如果有什么不对的地方,或者不好的地方,还请多多指正,不吝指教。
如果有什么不对的地方,或者不好的地方,还请多多指正,不吝指教。
如果有什么不对的地方,或者不好的地方,还请多多指正,不吝指教。














 1747
1747











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









