







为什么使用中文分词
举个例子,假如输入“周杰伦的演唱会”,就算使用模糊查询,也只能找到索引中与“xxx周杰伦演唱会xxx”相匹配的内容。
如果使用了中文分词,则可以找到所有与“周杰伦”、“演唱会”、甚至与“周杰”相关的内容。
下载jcseg
中文分词工具有很多,如比较常见的IK,我这里使用的是jcseg。
下载地址:https://github.com/lionsoul2014/jcseg
直接下载zip就行了。
maven打包
解压下载好的zip文件,进入文件目录,执行maven打包命令:
mvn clean install -Dmaven.test.skip=true -Dmaven.javadoc.skip=true
导入jar包
打包成功后,进入子项目 jcseg-core 下的 target 文件夹,把 jcseg-core-2.1.0.jar 文件拷贝到 【solr安装目录】/example/example-DIH/solr/db/lib/..路径下面。
在子项目 jcseg-analyzer 下面的 target 文件夹下,找到 jcseg-analyzer-2.1.0.jar 文件,拷贝到【solr安装目录】/example/example-DIH/solr/db/lib/..路径下面。
注意:我这里用db做实验,如果想用在其他核心配置中文分词,自行切换对应核心目录即可
编写solrconfig.xml
进入与lib同级的conf目录,找到solrconfig.xml并编辑此文件,
找到有如下代码的地方:
<lib dir="${solr.install.dir:../../../..}/dist/" regex="solr-dataimporthandler-.*\.jar" />
<lib dir="${solr.install.dir:../../../..}/contrib/extraction/lib" regex=".*\.jar" />
<lib dir="${solr.install.dir:../../../..}/dist/" regex="solr-cell-\d.*\.jar" />
<lib dir="${solr.install.dir:../../../..}/contrib/langid/lib/" regex=".*\.jar" />
<lib dir="${solr.install.dir:../../../..}/dist/" regex="solr-langid-\d.*\.jar" />
<lib dir="${solr.install.dir:../../../..}/contrib/velocity/lib" regex=".*\.jar" />
<lib dir="${solr.install.dir:../../../..}/dist/" regex="solr-velocity-\d.*\.jar" />在之后加上
<lib dir="${solr.install.dir:../../../..}/example/example-DIH/solr/db/lib/" regex="jcseg-core-2.1.1.jar" />
<lib dir="${solr.install.dir:../../../..}/example/example-DIH/solr/db/lib/" regex="jcseg-analyzer-2.1.1.jar" />编辑完后记得保存。
编辑managed-schema文件
打开conf目录下的managed-schema文件,在文件末尾</schema>之前加入如下代码:
<!-- 复杂模式分词: -->
<fieldtype name="textComplex" class="solr.TextField">
<analyzer>
<tokenizer class="org.lionsoul.jcseg.analyzer.JcsegTokenizerFactory" mode="complex"/>
</analyzer>
</fieldtype>
<!-- 简易模式分词: -->
<fieldtype name="textSimple" class="solr.TextField">
<analyzer>
<tokenizer class="org.lionsoul.jcseg.analyzer.JcsegTokenizerFactory" mode="simple"/>
</analyzer>
</fieldtype>
<!-- 检测模式分词: -->
<fieldtype name="textDetect" class="solr.TextField">
<analyzer>
<tokenizer class="org.lionsoul.jcseg.analyzer.JcsegTokenizerFactory" mode="detect"/>
</analyzer>
</fieldtype>
<!-- 检索模式分词: -->
<fieldtype name="textSearch" class="solr.TextField">
<analyzer>
<tokenizer class="org.lionsoul.jcseg.analyzer.JcsegTokenizerFactory" mode="search"/>
</analyzer>
</fieldtype>记得保存。
设置分词字段
找到设置<field>的地方,比如我这里找得的是:
<field name="title" type="text_general" indexed="true" stored="true" multiValued="true"/>修改type为如下代码:
<field name="title" type="textSearch" indexed="true" stored="true" multiValued="true"/>测试
首先关闭solr
solr stop -all然后启动solr
solr -e dih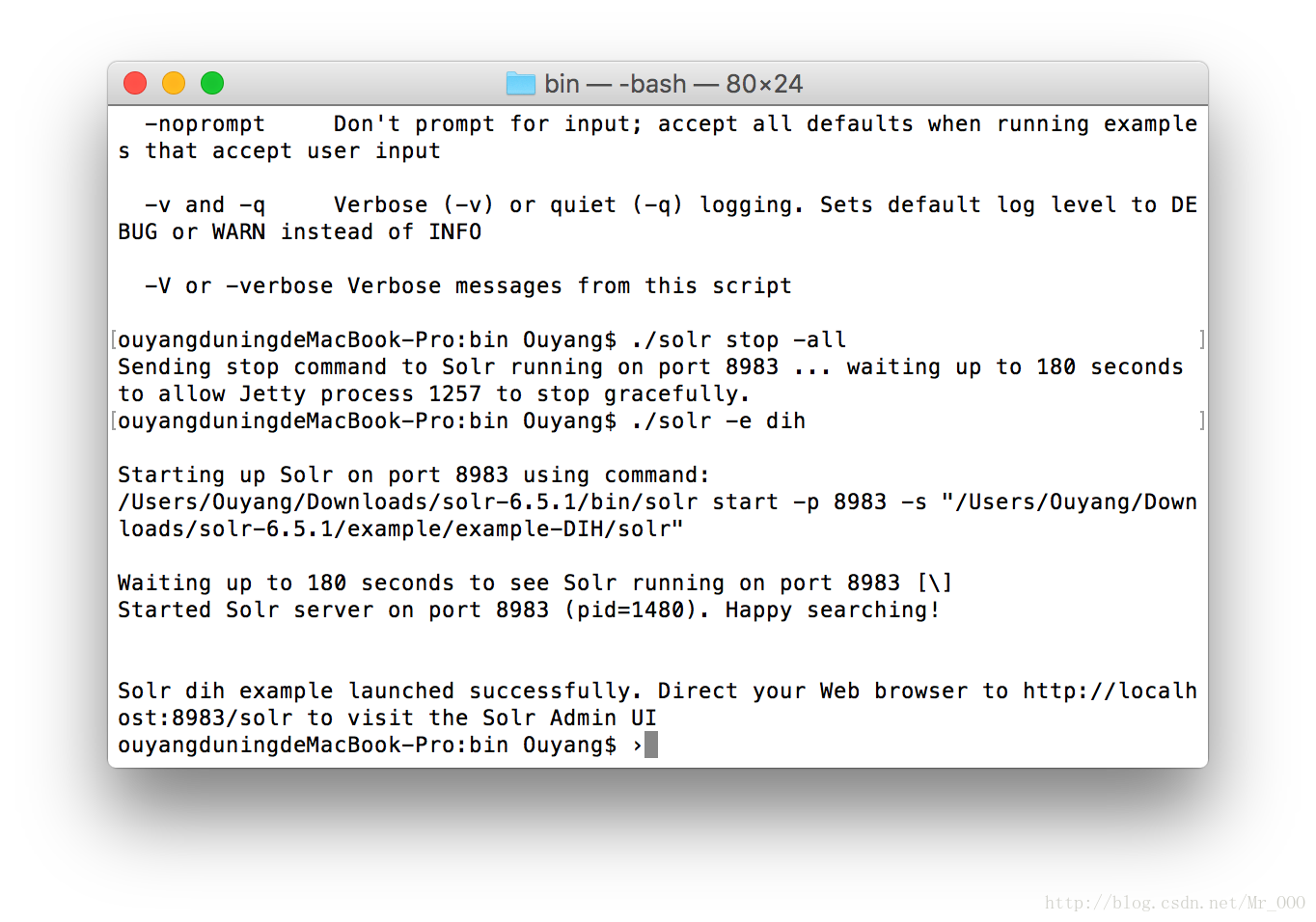
启动成功后进入solr主页,选择db核心(如果你中文分词配的其他核心选对应的就行),然后选择Analysis,随便输入一串中文,然后选择对应字段,我这里配的是title字段用中文分词(详情见上一步),所以
Analyse Fieldname / FieldType我选了title,点击Analysis views即可看到效果:

周杰伦被分出来了,可惜周杰没有,看来周杰还不是很出名啊。。。
实际使用中,title中包含这些字段的都会被查出来,我这里因为没有数据就不做演示了,感兴趣的同学可以自己试一试吧。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









