







SparkSql之窗口函数
所谓的窗口函数指的是对多行数据进行处理返回普通列和聚合列的过程;
详细语法:窗口函数() over([partition by 分区 order by 排序规则 ...])
窗口函数有三种分类:
- 聚合窗口函数
- 排名窗口函数
- 数据分析窗口函数
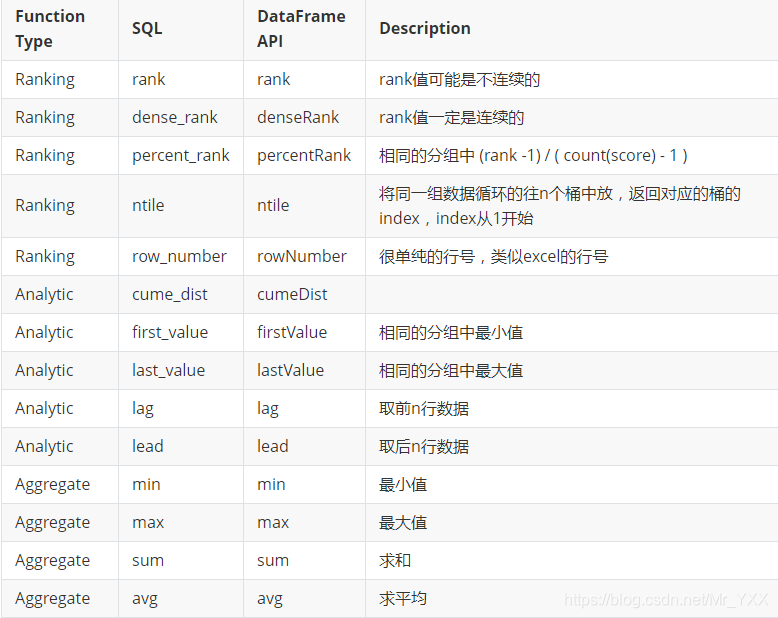
count(…) over(partition by … order by …) --求分组后的总数。 sum(…)
over(partition by … order by …) --求分组后的和。 max(…)
over(partition by … order by …) --求分组后的最大值。 min(…)
over(partition by … order by …) --求分组后的最小值。 avg(…)
over(partition by … order by …) --求分组后的平均值。 rank()
over(partition by … order by …) --rank值可能是不连续的。 dense_rank()
over(partition by … order by …) --rank值是连续的。 first_value(…)
over(partition by … order by …) --求分组内的第一个值。 last_value(…)
over(partition by … order by …) --求分组内的最后一个值。 lag()
over(partition by … order by …) --取出前n行数据。 lead()
over(partition by … order by …) --取出后n行数据。 ratio_to_report()
over(partition by … order by …) --Ratio_to_report()
括号中就是分子,over() 括号中就是分母。 percent_rank() over(partition by … order by
…) –
各个窗口函数应用的小场景案例
- rank() 求某天每个用户访问页面次数前10的页面
//测试数据
val rdd = spark.sparkContext.makeRDD(
List(
("2018-01-01", 1, "www.baidu.com", "10:01"),
("2018-01-01", 2, "www.baidu.com", "10:01"),
("2018-01-01", 1, "www.sina.com", "10:01"),
("2018-01-01", 3, "www.baidu.com", "10:01"),
("2018-01-01", 3, "www.baidu.com", "10:01"),
("2018-01-01", 1, "www.sina.com", "10:01")
))
解题思路
1.每个用户访问不同页面的次数
2.对每个用户点击页面次数降序排列,并且使用窗口函数中的排名函数
3.获得每个用户访问次数前十的页面 where rank < n
方法一:调用方法实现
import sp.implicits._
//导入窗口函数的支持
import org.apache.spark.sql.functions._
rdd
.toDF("time","uid","path","ztime")
.groupBy("uid","path") //根据用户 和访问的网址 分组
.count() //分组之后的聚合操作 通知每个用户访问每个网址的次数
//添加列 列名 rank 窗口函数rank():rank值可能是不连续的 over 创建的窗口
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3244
3244











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









