






前言
最近工作上因为公司的需求做了一个网络爬虫,因为之前也没有接触过,所以现在记录一下整个爬虫实现的过程,以及对爬虫经验的总结。
1.什么叫网络爬虫
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。以上是百度百科的解析,其实简单来说就根据需求,在网上获取我们想要的信息。
2.开发语言
实现爬虫的语言可以用 c , java , php , python .这里建议使用python.因为上手容易,模块很多,不需要再自己造轮子,可以跳过直接上车载客不。
3.开发工具
python有个很好用的工具PyCharm , 界面很好,用起来方便舒服,写代码很好用。可以官网下载,有专业版和社区版,专业版需要注册码,百度一个就可以。使用PyCharm的前提是要确保你已经安装了python2.7(版本可以自己选择,本次开发安装的是2.7的)
4.开发环境
本次开发是在linux的环境下进行,首先要在linux下安装python以及开发所需的库,由于开发需要使用数据库,这里使用的是mysql,因为python有mysql的接口,可以直接安装使用。数据库以及其接口模块的安装比较容易,百度一下有很多方法。
5.爬虫的实现
5.1获取url网页内容
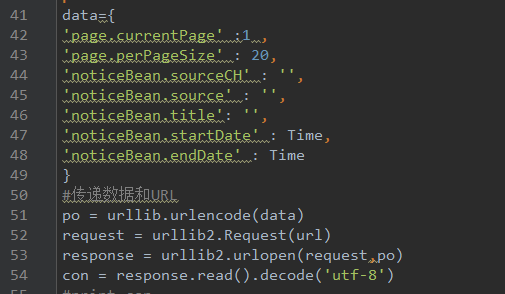
打开url链接,审查源码,使用开发者工具查看其结构,查看数据请求的规则。然后代码实现,导入相应的模块,下图是获取url内容的代码
5.2爬去需要的内容
这一步其实就过滤网页上的内容,建议使用第三方库,例如BeautifulSoup,解析html , 事半功倍。这里还要介绍的是python自带的一些很好用的模块,例如re模块,re.search ,re.findall , 可以使用这两个函数爬去网页中的部分内容,当然这其中就需要使用正则表达式,如果没用过正则的话建议先去看《正则表达式30分钟入门教程》,这里简单讲一下正则经常使用的一些匹配。
去掉所有标签
dr = re.compile(r’<[^>]+>’,re.S)
dd = dr.sub(”,jiner)
任意内容/可以匹配多位数字/可以匹配用逗号隔开的数字/可以匹配一位的数字/可以匹配带小数点的数字/匹配空白符/匹配最后两位
re.search(‘.?([0-9]{1,},?[0-9]{0,}.?[0-9]{0,}\s.?.?)$’,dd)
当然,爬虫还有一个很关键的就通过关键字过滤,这里可以使用字符串查找匹配全文的关键字,使用content.find查找关键字,将需要匹配关键字全部放入一个列表中list[ ],然后通过遍历查找,这样就过滤出相应的容以上的整个过程其实就是获取url然后过滤最终获取相应的内容。
5.3入库mysql
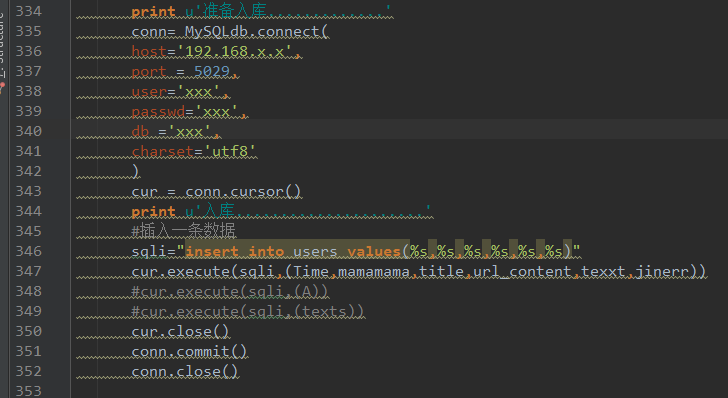
将爬去的内容保存在数据库mysql中,这里需要进行数据库的连接,然后通过插入数据的方法可以将数据存入mysql,以下是数据库的连接和数据插入
5.4邮件发送
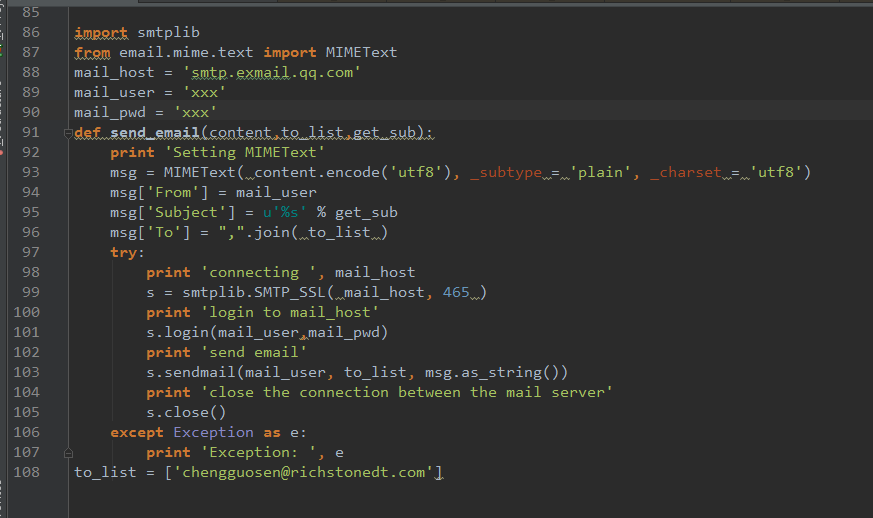
将数据保存在本地数据库后,还可以实现一个功能就是邮件发送数据给指定的用户。因为本次要实现的是定时爬虫,每天在不同的时间段定时爬取网页上更新的数据,然后将我们所需要的数据通过邮件自动发给指定的用户。python有自带邮件发送的模块,可以支持SMTP,所以很方便使用,下面是邮件发送的代码。
5.5linux下定时自动爬虫
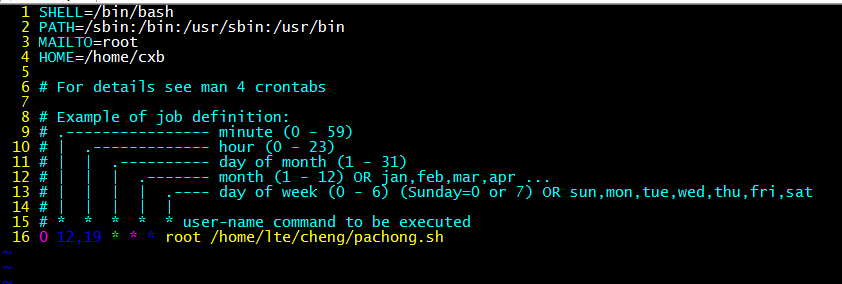
linux下可以使用crond配置定时执行程序,可以先写一个脚本,将需要的内容记录到日志中。然后再/etc/crontab下进行部署,至于如何设置部署,可以百度一下linux下crond命令的使用
以上就是所有内容了,有很多细节的东西没有描述出来,主要是为了记录一下整个过程,以后有需要可以翻来看,第一次写博客,而且是在周五的深夜一点,大家不要喷哈!















 5096
5096

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









