









网络下的数据传输之XML数据的解析
在app应用开发中,网络的使用无处不在,所以涉及到手机端与后台的数据交互也必然存在。主要存在以下两种格式的数据:XML和Json。
概述
1、XML简介
XML(Extensible Markup Language)可扩展标记语言,一种标准通用的语言。它通过一些简单的标签进行描述数据,从而达到数据传输的目的。
2、JSON简介
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式。它基于ECMAScript的一个子集。 JSON采用完全独立于语言的文本格式,但是也使用了类似于C语言家族的习惯(包括C、C++、C#、Java、JavaScript、Perl、Python等)。这些特性使JSON成为理想的数据交换语言。 易于人阅读和编写,同时也易于机器解析和生成(一般用于提升网络传输速率)。
数据的解析
1、XML解析
在Android中,常见的XML解析器分别为SAX解析器、DOM解析器和PULL解析器。后面会分别介绍。
2、JSON解析
JSON的解析可以借助gson.jar包进行接下。
XML的解析
我们建立下面的xml文件用于测试:
<?xml version="1.0" encoding="utf-8"?>
<books>
<book>
<name>Android源码设计模式解析与实战</name>
<author>何红辉、关爱民</author>
<price>79.0</price>
</book>
<book>
<name>Android开发艺术探索</name>
<author>任玉刚</author>
<price>66.2</price>
</book>
<book>
<name>Android群英传</name>
<author>徐宜生</author>
<price>49.0</price>
</book>
</books>一、使用DOM解析器解析XML
DOM(Document Object Model)一种用于XML文档的对象模型,可用于直接访问XML文档的任何部分。在DOM中将真个文档加载进内存,文档被解析成树状模型。所以,我们可以通过api接口遍历整个文档来进行需要的读取。在DOM解析器下,我们需要了解以下概念:
1、节点
- 整个文档是一个文档节点
- 每个XML标签是一个元素节点
- 包含在XML元素中的文本是文本节点
- 每一个XML属性是一个属性节点
2、常见节点类型:
- Node:DOM基本数据类型
- Element:最主要的处理对象
- Attr:代表元素的属性
- Text:一个Element或Attr的内容
- Document:代表整个文档对象

我们建立名称为DataXMLParse的module。下面开始我们的具体开发步骤:
1、根据books.xml文件,建立一个对应的实体类。
<?xml version="1.0" encoding="utf-8"?>
<books>
<book>
<icon>hhh</icon>
<name>Android源码设计模式解析与实战</name>
<author>何红辉、关爱民</author>
<price>79.0</price>
</book>
<book>
<icon>ryg</icon>
<name>Android开发艺术探索</name>
<author>任玉刚</author>
<price>66.2</price>
</book>
<book>
<icon>xys</icon>
<name>Android群英传</name>
<author>徐宜生</author>
<price>49.0</price>
</book>
</books>2、有了我们的xml数据,我们想把它解析出来用ListView进行显示。
(1)、创建T_BookEntity实体,用于存储我们解析的数据。
package dsw.com.androidnedemo;
/**
* Created by dsw on 2015/10/27.
*/
public class T_BookEntity{
private String name;
private String author;
private String price;
private String iconId;
public String getIconId() {
return iconId;
}
public void setIconId(String iconId) {
this.iconId = iconId;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getPrice() {
return price;
}
public void setPrice(String price) {
this.price = price;
}
}(2)、实体创建完毕,我们就开始进行解析,按照我们上面的分析流程图,我们创建一个名为DataParseUtils类进行封装解析xml文件的方法。
public class DataParseUtils {
public static List<T_BookEntity> DomXMLUtils(InputStream inputStream){
List<T_BookEntity> list = new ArrayList<>();
T_BookEntity t_bookEntity;
//创建DocumentBuilderFactory对象
DocumentBuilderFactory documentBuilderFactory = DocumentBuilderFactory.newInstance();
try {
//创建DocumentBuilder对象进行创建Document对象
DocumentBuilder documentBuilder = documentBuilderFactory.newDocumentBuilder();
//创建一个Document对象
Document document = documentBuilder.parse(inputStream);
//获取根节点
Element element = document.getDocumentElement();
//获取所有名为book的子节点
NodeList nodeList = element.getElementsByTagName("book");
//遍历获取的节点集合
for(int i=0;i<nodeList.getLength();i++){
t_bookEntity = new T_BookEntity();
Element nodeBook = (Element) nodeList.item(i);
//遍历book节点下的子节点,然后遍历获取属性值
NodeList nodeChildes = nodeBook.getChildNodes();
for(int index = 0;index < nodeChildes.getLength();index++){
Node childNode = nodeChildes.item(index);
if(childNode.getNodeType() == Node.ELEMENT_NODE){
if("name".equals(childNode.getNodeName())){
t_bookEntity.setName(childNode.getFirstChild().getNodeValue());
}else if("author".equals(childNode.getNodeName())){
t_bookEntity.setAuthor(childNode.getFirstChild().getNodeValue());
}else if("price".equals(childNode.getNodeName())){
t_bookEntity.setPrice(childNode.getFirstChild().getNodeValue());
}else if("icon".equals(childNode.getNodeName())){
t_bookEntity.setIconId(childNode.getFirstChild().getNodeValue());
}
}
}
list.add(t_bookEntity);
}
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return list;
}
}在上面的方法中,我们通过getChildNodes()方法进行遍历节点解析数据,通过getNodeValue()方法获取节点的值,然后存储到对应的实体中,最后返回一个集合到activity中进行处理。
3、MainActivity中的处理,以及Adapter的写法:
(1)、MainActivity的处理:
public class MainActivity extends AppCompatActivity {
private ListView mListView;
private List<T_BookEntity> list;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
initListData();
mListView = (ListView) findViewById(R.id.listView);
mListView.setAdapter(new ListViewAdapter(getApplication(),list));
}
private void initListData(){
String dataPath = "/data/data/dsw.com.androidnedemo/books.xml";
try {
InputStream is = new FileInputStream(dataPath);
list = DataParseUtils.DomXMLUtils(is);
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
}我们将xml文件当道data/data对应的文件夹下,然后通过上面的解析方法进行解析。
(2)、Adapter的源码以及xml布局文件。
public class ListViewAdapter extends BaseAdapter {
private Context mContext;
private List<T_BookEntity> list;
private ViewHolder viewHolder;
public ListViewAdapter(Context context,List<T_BookEntity> list){
this.mContext = context;
this.list = list;
}
@Override
public int getCount() {
return list == null ? 0 :list.size();
}
@Override
public Object getItem(int position) {
return list == null ? null :list.get(position);
}
@Override
public long getItemId(int position) {
return position;
}
@Override
public View getView(int position, View convertView, ViewGroup parent) {
if(convertView == null || convertView.getTag() == null){
viewHolder = new ViewHolder();
convertView = LayoutInflater.from(mContext).inflate(R.layout.book_item,null);
viewHolder.iv_icon = (ImageView) convertView.findViewById(R.id.iv_icon);
viewHolder.tv_name = (TextView) convertView.findViewById(R.id.tv_name);
viewHolder.tv_author = (TextView) convertView.findViewById(R.id.tv_author);
viewHolder.tv_price = (TextView) convertView.findViewById(R.id.tv_price);
}else{
viewHolder = (ViewHolder) convertView.getTag();
}
int id = mContext.getResources().getIdentifier(list.get(position).getIconId(),
"mipmap","dsw.com.androidnedemo");
viewHolder.iv_icon.setBackgroundResource(id);
viewHolder.tv_name.setText(list.get(position).getName());
viewHolder.tv_author.setText(list.get(position).getAuthor());
viewHolder.tv_price.setText(list.get(position).getPrice());
return convertView;
}
private static class ViewHolder{
public ImageView iv_icon;
public TextView tv_name;
public TextView tv_author;
public TextView tv_price;
}
}xml布局文件:
<?xml version="1.0" encoding="utf-8"?>
<RelativeLayout xmlns:android="http://schemas.android.com/apk/res/android"
android:orientation="horizontal"
android:padding="10dp"
android:layout_width="match_parent"
android:layout_height="wrap_content"
android:gravity="center_vertical">
<ImageView
android:id="@+id/iv_icon"
android:layout_width="50dp"
android:layout_height="50dp"
android:layout_marginRight="10dp"
android:layout_centerVertical="true"
android:background="@mipmap/hhh"/>
<LinearLayout
android:id="@+id/linear"
android:layout_alignParentRight="true"
android:layout_marginLeft="10dp"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_centerVertical="true"
android:orientation="vertical">
<TextView
android:id="@+id/tv_author"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:text="何红辉、关爱民"
android:textSize="15sp"/>
<TextView
android:id="@+id/tv_price"
android:layout_width="match_parent"
android:layout_height="wrap_content"
android:text="79.0"
android:gravity="right"
android:textSize="15sp"/>
</LinearLayout>
<TextView
android:id="@+id/tv_name"
android:layout_toRightOf="@id/iv_icon"
android:layout_toLeftOf="@id/linear"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_centerVertical="true"
android:text="Android源码设计模式解析与实战"
android:textSize="17sp"/>
</RelativeLayout>至此,我们的所有解析工作已经完成。看下dom解析做出来的效果图:
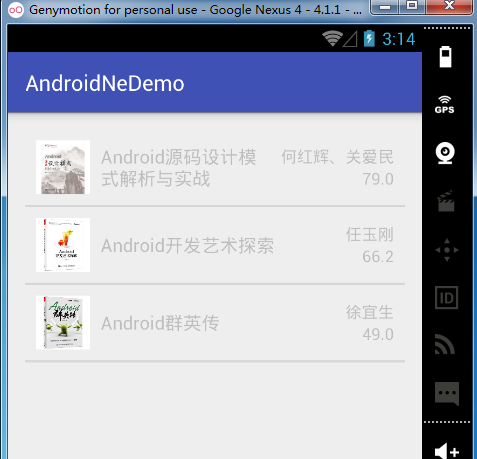
二、使用SAX解析器解析XML
1、SAX概述
SAX是一种以事件为驱动的解析方法,由它定义的事件流可以指定从解析器传到专门的处理代码。特点是解析速度快,占用内存少。所以特别适合android移动设备。
SAX 允许您在读取文档时处理它,从而不必等待整个文档被存储之后才采取操作。它不涉及 DOM 所必需的开销和概念跳跃。 SAX API是一个基于事件的API ,适用于处理数据流,即随着数据的流动而依次处理数据。SAX API
在其解析您的文档时发生一定事件的时候会通知您。SAX API中主要有四种处理事件的接口,它们分别是ContentHandler,DTDHandler, EntityResolver 和 ErrorHandler 。我们只需要继承DefaultHandler,然后去重写对应的方法即可。主要有:
- startDocument()方法只会在文档开始解析的时候被调用,每次解析只会调用一次。
- startElement()方法每次在开始解析一个元素,即遇到元素标签开始的时候都会调用。
- characters()方法也是在每次解析到元素标签携带的内容时都会调用,即使该元素标签的内容为空或换行。而且如果元素内嵌套元素,在父元素结束标签前, characters()方法会再次被调用,此处需要注意。
- endElement()方法每次在结束解析一个元素,即遇到元素标签结束的时候都会调用。
- endDocument() startDocument()方法只会在文档解析结束的时候被调用,每次解析只会调用一次。
解析来,我们就用SAX方法解析我们上面的books.xml文件。我们在DataXMLParse工程中创建名为SAXParseHandler的类。
/**
* Created by dsw on 2015/10/28.
*/
public class SAXParseHandler extends DefaultHandler {
//存储解析返回的集合
private List<T_BookEntity> list;
//记录当前节点
private T_BookEntity t_bookEntity;
//用来存放每次遍历后的元素名称(节点名称)
private String tagName;
/**
* 只调用一次,在文档开始解析的时候,可用于初始化一些变量
* @throws SAXException
*/
@Override
public void startDocument() throws SAXException {
list = new ArrayList<>();
}
/**
* 解析xml文件的元素,调用多次
* @param uri
* @param localName
* @param qName
* @param attributes
* @throws SAXException
*/
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
if("book".equals(qName)){//是book节点就创建一个实体存储
if(t_bookEntity == null)
t_bookEntity = new T_BookEntity();
}
//记录当前tag,后面用于判断
tagName = qName;
}
/**
* 调用多次,
* @param ch
* @param start
* @param length
* @throws SAXException
*/
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
String data = new String(ch,start,length);
if(tagName != null && !data.trim().equals("")){
if("name".equals(tagName)){
t_bookEntity.setName(data);
}else if("author".equals(tagName)){
t_bookEntity.setAuthor(data);
}else if("price".equals(tagName)){
t_bookEntity.setPrice(data);
}else if("icon".equals(tagName)){
t_bookEntity.setIconId(data);
}
}
}
/**
* 解析完一个标签结束时调用
* @param uri
* @param localName
* @param qName
* @throws SAXException
*/
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
if("book".equals(qName)){//遍历完一个节点
list.add(t_bookEntity);
t_bookEntity = null;
}
tagName = null;
}
/**
* 文档解析结束时调用,调用一次
* @throws SAXException
*/
@Override
public void endDocument() throws SAXException {
super.endDocument();
}
public List<T_BookEntity> getList() {
return list;
}
}这样就完成了我们解析器的编写,下面就是我们如何使用了。
/**
* 通过SAX方法进行解析
*/
private void userSAXParser(){
SAXParserFactory saxParserFactory = SAXParserFactory.newInstance();
try {
String dataPath = "/data/data/dsw.com.androidnedemo/books.xml";
SAXParser saxParser = saxParserFactory.newSAXParser();
//实例化我们的SAXParseHandler对象
SAXParseHandler saxParseHandler = new SAXParseHandler();
//加载资源转换成流
InputStream inputStream = new FileInputStream(dataPath);
saxParser.parse(inputStream,saxParseHandler);
list = saxParseHandler.getList();
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}效果图:
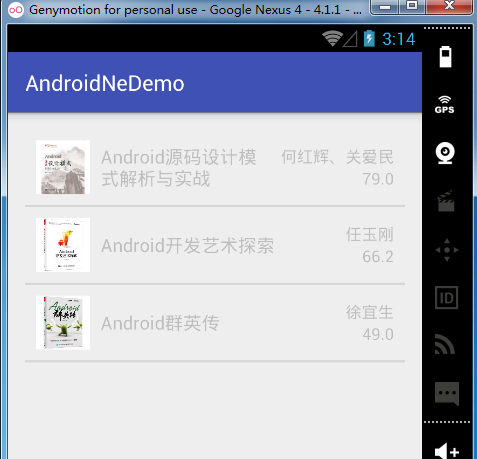
三、使用SAX解析器解析XML
Pull解析器和SAX解析器虽有区别但也有相似性。他们的区别为:SAX解析器的工作方式是自动将事件推入注册的事件处理器进行处理;而Pull解析器的工作方式为允许你的应用程序代码主动从解析器中获取事件,正因为是主动获取事件,因此可以在满足了需要的条件后不再获取事件,结束解析。这是他们主要的区别。
我们同样在DataParseUtils类中增加一个PullXMLUtils方法。
/**
* 通过PullParser方式解析
* @param inputStream
* @return
*/
public static List<T_BookEntity> PullXMLUtils(InputStream inputStream,String encode){
List<T_BookEntity> list = null;
T_BookEntity t_bookEntity = null;
XmlPullParserFactory xmlPullParserFactory = null;
try {
//创建PullParserFactory构造器
xmlPullParserFactory = XmlPullParserFactory.newInstance();
//创建XmlPullParser解析器,或者通过xmlPullParser = Xml.newPullParser();
XmlPullParser xmlPullParser = xmlPullParserFactory.newPullParser();
//设置我们的数据流
xmlPullParser.setInput(inputStream,encode);
//获取节点类型
int type = xmlPullParser.getEventType();
while(type != XmlPullParser.END_DOCUMENT){
switch (type){
case XmlPullParser.START_DOCUMENT:
list = new ArrayList<>();
break;
case XmlPullParser.START_TAG:
if("book".equals(xmlPullParser.getName())){//是book的起始标签
t_bookEntity = new T_BookEntity();
}else if("name".equals(xmlPullParser.getName())){
t_bookEntity.setName(xmlPullParser.nextText());
}else if("author".equals(xmlPullParser.getName())){
t_bookEntity.setAuthor(xmlPullParser.nextText());
}else if("price".equals(xmlPullParser.getName())){
t_bookEntity.setPrice(xmlPullParser.nextText());
}else if("icon".equals(xmlPullParser.getName())){
t_bookEntity.setIconId(xmlPullParser.nextText());
}
break;
case XmlPullParser.END_TAG:
if("book".equals(xmlPullParser.getName())){//book结束标签
list.add(t_bookEntity);
}
break;
case XmlPullParser.END_DOCUMENT:
break;
}
type = xmlPullParser.next();
}
} catch (XmlPullParserException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return list;
}然后在MainActivity中调用。
/**
* 通过Pull方式进行解析xml
*/
private void pullParserXml(){
String dataPath = "/data/data/dsw.com.androidnedemo/books.xml";
try {
InputStream is = new FileInputStream(dataPath);
list = DataParseUtils.PullXMLUtils(is, "utf-8");
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}展示效果图同样使用ListView展示。
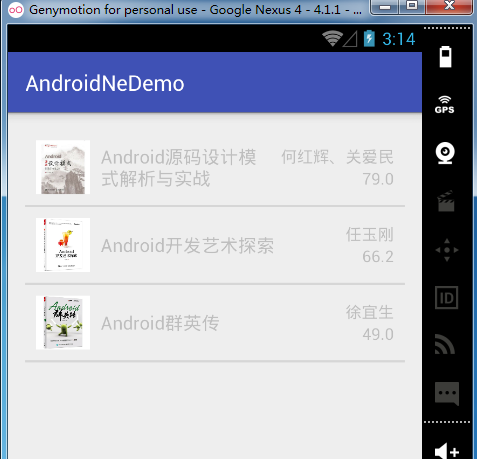
至此,我们已经学习完了XML的解析方法,三种方法,我个人认为还是使用Pull方法进行比较方便,同时在实际工作中,我也推荐大家使用Pull方法进行解析。另外补充一个知识点,以上我们都是对XML文件进行解析,所以补充的知识点就是对XML文件的序列本地化。例如下面的demo:
/**
* 进行XML文件的序列化
* @param list
* @param outputStream
*/
private void XmlSerializerUtils(List<T_BookEntity> list,OutputStream outputStream){
XmlSerializer xmlSerializer = Xml.newSerializer();
try {
xmlSerializer.setOutput(outputStream, "utf-8");
xmlSerializer.startDocument("utf-8", true);
xmlSerializer.startTag(null,"books");
for(T_BookEntity t_bookEntity : list){
xmlSerializer.startTag(null,"book");
xmlSerializer.startTag(null,"icon");
xmlSerializer.text(t_bookEntity.getIconId());
xmlSerializer.endTag(null, "icon");
xmlSerializer.startTag(null, "name");
xmlSerializer.text(t_bookEntity.getName());
xmlSerializer.endTag(null, "name");
xmlSerializer.startTag(null, "author");
xmlSerializer.text(t_bookEntity.getAuthor());
xmlSerializer.endTag(null, "author");
xmlSerializer.startTag(null, "price");
xmlSerializer.text(t_bookEntity.getPrice());
xmlSerializer.endTag(null,"price");
xmlSerializer.endTag(null,"book");
}
xmlSerializer.endTag(null,"books");
xmlSerializer.endDocument();
} catch (IOException e) {
e.printStackTrace();
}
}分析三种方式:
1、占用内存
这是一个根本问题,由于Android系统对内存比较吃紧,所以xml的解析速度回直接影响程序的性能。SAX、Pull的解析方式占用内存比DOM方式少。
2、编程方式
1、SAX是一种事件驱动的方式,说白了就是通过重写父类的方法,然后进行处理。也就是说针对不同的xml文件需要编写不同的处理类,同时这样造成了有需要写大量的代码,不是很方便。Dom方式是W3C所规范的,所以是用比较广泛,它通过将xml文档解析称一种树的形式进行解析,所以比较消耗内存和时间。Pull方式是android系统独具的,代码编写比较简单,所以推荐使用。
上面,我们已经完成了网络数据传输中的XML文件的解析。下篇,我们讲解下在手机端与服务器交互的比较流行的一种数据格式解析Json。
作者:mr_dsw 欢迎转载,与人分享是进步的源泉!
转载请保留地址:http://blog.csdn.net/mr_dsw















 1199
1199











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









