







列表
在学习列表之前先了解一下什么是序列。
序列:成员有序排列的,且可以通过下标偏移量访问到它的一个或者几个成员,这类类型统称为序列。
序列数据类型包括:字符串,列表,和元组类型。
序列的特点: 成员关系操作符(in , not),连接操作符(+),重复操作符(*),索引与切片操作符。
1.列表的创建
列表也是数组的一种形式,但是数组和列表有什么不同呢?
数组:存储同一种数据类型的集和。例如:scores=[12,95.5]
列表(打了激素的数组):可以存储任意数据类型的集和。例如:li=[25,40,'hello']
- 创建一个空列表 list = []
- 创建一个包含元素的列表,元素可以是任意类型,包括数值类型,列表,字符串等均可, 也可以嵌套列表。
例如: list = ["fentiao", 4, 'gender'] list = [['粉条', 100], ["粉丝", 90], ["粉带", 98]]
2.列表的特性
练习1 (成员操作符)
根据指定月份,打印该月份所属的季节。
提示: 3,4,5 春季 6,7,8 夏季 9,10,11 秋季 12, 1, 2 冬季
考察点: 列表的成员操作符, if判断语句
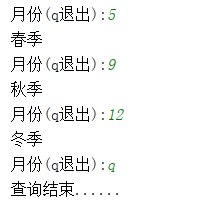
代码如下:
while True:
month = input('月份(q退出):')
# if month in ['3','4','5']:
if month in '345':
print("春季")
elif month in '678':
print("夏季")
elif month in ['9', '10', '11']:
print("秋季")
elif month in ['12', '1', '2']:
print("冬季")
elif month == 'q':
print("查询结束......")
break
else:
print("请输入正确的月份")结果示例:
练习2 (连接操作符,索引和切片)
假定有下面这样的列表: names = ['fentiao', 'fendai', 'fensi', 'apple']
要求输出结果为:'I have fentiao, fendai, fensi and apple.'
代码如下:
names = ['fentiao', 'fendai', 'fensi', 'apple']
# 列表切片和索引的掌握案例;
print('I have ' + ",".join(names[:-1]) + ' and ' + names[-1] + '.')输出结果为:
![]()
3.列表的操作(增加、删除、修改、查找)
1)元素的增加方法(.append .extend .insert)
- 列表可通过append追加一个元素到列表中。
例如:

- 列表可通过extend方法拉伸,实现追加多个元素到列表中
例如:

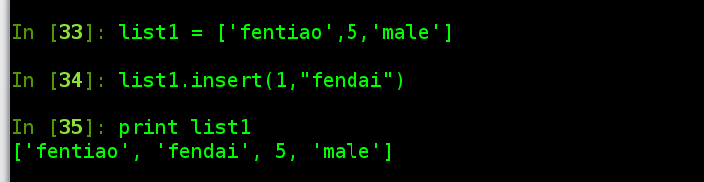
- 在指定位置添加元素可以使用insert方法
例如:
2)元素的删除方法(.remove .pop .clear)
- list.remove() 删除列表中的指定元素。
- list.pop() 弹出, 默认删除最后一个元素; 当然可以通过传索引值去指定要删除的元素。
- list.clear: 清空列表里面的所有元素。
例如:

3)列表的修改(通过索引和切片)
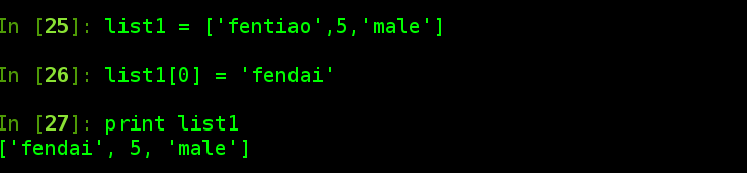
修改列表的元素:直接通过索引和切片重新赋值就可以实现修改。
例如:
4)列表的查找(.index .count)
- 查看某个列表元素的下标(索引值)用index方法,默认从索引值0处开始依次查找,要查找的元素后可以跟两个数字,表示从指定位置开始查找到指定位置结束;
- 查看某个列表元素出现的次数用count方法
例如:

5)其他操作
- .copy 可以复制列表到一个新的列表中
- .sort 对列表中的数字进行从小到大重新排序
4.补充说明
1) is和==的区别
is和==两种运算符在应用上的本质区别是什么?
- Python中对象的三个基本要素,分别是:id(内存位置)、type(数据类型)和value(值)。
- is和==都是对对象进行比较判断作用的,但对对象比较判断的内容并不相同。
- ==用来比较判断两个对象的value(值)是否相等;(比较type和value)
- is也被叫做同一性运算符, 会判断id是否相同;(比较id, type 和value)
例如:
a = [1,2,3]
b = [1,2,3]
a == b
Out[3]: True
a is b
Out[4]: False
id(a)
Out[5]: 139715958128456
id(b)
Out[6]: 139715958186248
a=1;b='1'
a == b
Out[7]: False
2)深拷贝和浅拷贝
赋值: 创建了对象的一个新的引用,修改其中任意一个变量都会影响到另一个。(=)
浅拷贝: 对另外一个变量的内存地址的拷贝,这两个变量指向同一个内存地址的变量值。(li.copy(), copy.copy())
- 公用一个值;
- 这两个变量的内存地址一样;
- 对其中一个变量的值改变,另外一个变量的值也会改变;
例如:
scores = [100, 100, [100, 100, 100]]
scores1 = scores[:]
print(scores, id(scores))
print(scores1, id(scores1))
scores[-1][0] = 200
print(scores)
print(scores1)
#浅拷贝第2种实现方式
import copy
scores2 = copy.copy(scores)
print(scores, id(scores))
print(scores2, id(scores1))
scores[-1][0] = 200
print(scores)
print(scores2)输出结果为:

深拷贝: 一个变量对另外一个变量的值拷贝。(copy.deepcopy())
- 两个变量的内存地址不同;
- 两个变量各有自己的值,且互不影响;
- 对其任意一个变量的值的改变不会影响另外一个
例如:
import copy
scores = [100, 100, [100, 100, 100]]
# 深拷贝
scores1 = copy.deepcopy(scores)
print(scores, id(scores))
print(scores1, id(scores1))
scores[-1][0] = 200
print(scores)
print(scores1)输出结果为:

元组
元组可以说是带了紧箍咒的列表,因为元组是不可变的。
1.元组的创建
- 定义空元组 tuple = ()
- 定义单个值的元组 tuple = (fentiao)
- 一般的元组 tuple = (fentiao, 8, male)
注意: 不能对元组的值任意更改

2.元组的特性
元组和列表的特性一样,都有连接操作符,重复操作符,成员操作符 索引, 切片。
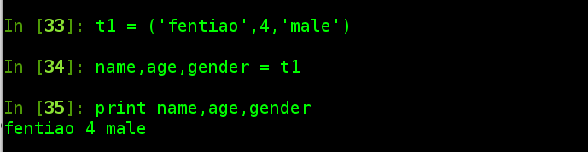
但是元组有一个不一样的特性:多元赋值,对元组分别赋值,引申对多个变量也可通过元组方式分别赋值。方式如下:
3.元组的方法
- t.count(value)-->int 返回value在元组中出现的次数;
- t.index(value) 返回value在元组中的偏移量(即索引值)
4.命名元组
1)用法简介
Tuple还有一个兄弟,叫namedtuple。虽然都是tuple,但是功能更为强大。
collections.namedtuple(typename, field_names)
其中 typename:类名称
field_names: 元组中元素的名称
2)定义命名元组类与应用
- 命名元组是一个类,有两种方式来定义命名元组:

- 实例化命名元组,获得类的一个实例:
![]()
- 访问命名元组:通过逗号运算符和属性名来访问元组字段的值
例如: user.name; user.age, user.id
3)命名元组的属性
- 类属性 _fields:包含这个类所有字段名的元组
![]()
- 类方法 _make(iterable):接受一个可迭代对象来生产这个类的实例
![]()
- 实例方法_replace():用于修改实例的属性
下面是对命名元组的综合应用代码:
import collections
# 定义一个命名元组的类, 类名User, 属性有三个, 分别是'name', 'age', 'scores';
User = collections.namedtuple("User", ['name', 'age', 'scores'])
# 实例化一个类, 名字叫粉条, 等等其他信息;
user = User("粉条", 10, [100, 100, 100])
# 打印该对象的属性;
print(user)
print(user.name)
print(user.age)
print(user.scores)
# ****************************
print(user._fields)
user1 = User._make(['粉丝', 10, [100, 90, 90]])
print(user1)
# 间接改变属性信息;
user2 = user1._replace(name="粉带")
print(user2)输出结果为:
















 1622
1622











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









