






哈夫曼树是一种基于二叉树结构的存储结构,它利用二叉树将数据转换为对应的哈夫曼编码,在数据传输或存储时对数据进行压缩以减少空间的占用。
举一个例子:如果要存储字符串"AAAAAABBBCDDAA",14个字符在内存中需要14个字节(112比特)。接下来我们看看如何得到该字符串的哈夫曼编码。
我们当然可以用最简单的方式为字符串中的每个字符分配一个编号,如图:
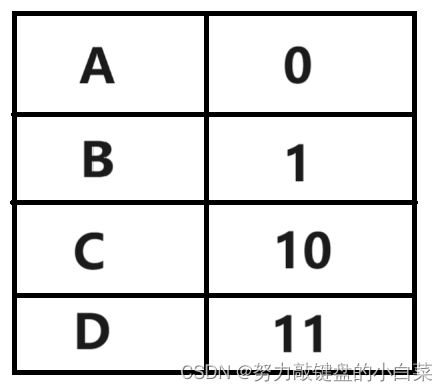
按照这种做法,编码后的字符串应表示为:00000011110111100。这时我们会发现编码后的字符串可能会被错误的译码,如刚才的字符串可以被译码成AAAAAADDADDAA,那么显然这样做是不可取的。
正确的做法应该是确保每一个字符编码都不会是另一个字符编码的前缀,比如上面例子中B的编码0就是C和D的编码前缀。为了确保解码的唯一性,我们就需要用到哈夫曼树,具体操作步骤如下:
1. 将字符串中的每一个字符视为二叉树中的一个节点放进集合中,节点的值为该字符在字符串中出现的次数。
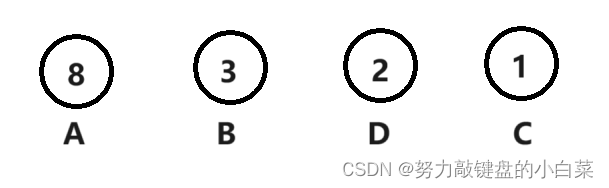
2. 每次取其中两个值最小的节点,为他们构造一个父节点,父结点的值为两个节点的值的和。如:
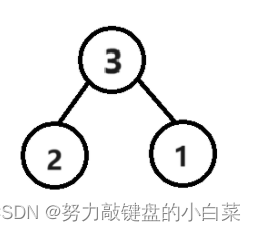
3. 将新构造的父节点(即上图中的3)再次放进节点集合中。
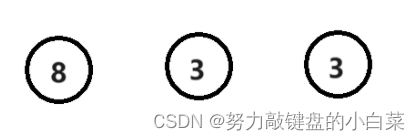
4. 重复步骤2,3直到集合中没有剩余节点。
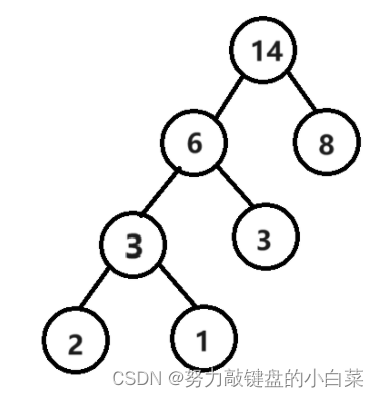
最终效果如上图,此时一棵哈夫曼树已经构造完成,树中的每一个叶子节点(没有孩子的节点)就是我们原本的字符。在此基础上,我们将其左侧的度编码为1,右侧的度编码为0,就会得到如下的结果:
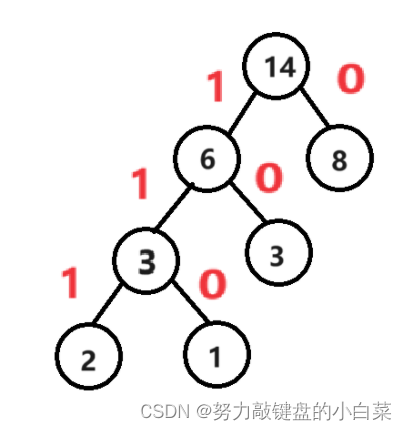
此时,每个字符的编码就会是从根节点到叶子节点的路径。A的编码是0,B的编码是10,C的编码是110,D的编码是111。此时任何一个字符的编码都不是另一个字符编码的前缀。
如果我们用这种方式对数据进行存储,结果只会占用23(WPL值)个比特,对比原来的122个比特节省了不少空间。注:这里还需要注意,出现频次越高的字符编码越短,这是因为我们在建树时在树的底部优先选择了出现频次较少的字符。















 5659
5659











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









