







chan
channel 是Golang在语言层面提供的goroutine间的通信方式,比Unix管道更易用也更轻便。channel主要用于进程内各goroutine间通信,如果需要跨进程通信,建议使用分布式系统的方法来解决。
chan数据结构:循环队列+阻塞队列
-
源代码
type hchan struct { qcount uint // 当前队列中剩余元素个数 dataqsiz uint // 环形队列长度,即可以存放的元素个数 buf unsafe.Pointer // 环形队列指针 elemsize uint16 // 每个元素的大小,用于在buf中定位元素位置 closed uint32 // 标识关闭状态 elemtype *_type // 元素类型,用于数据传递过程中的赋值; sendx uint // 队列下标,指示元素写入时存放到队列中的位置 recvx uint // 队列下标,指示元素从队列的该位置读出 recvq waitq // 等待读消息的goroutine队列 sendq waitq // 等待写消息的goroutine队列 lock mutex // 互斥锁,chan不允许并发读写。一个channel同时仅允许被一个goroutine读写,为简单起见 } -
循环队列 chan内部实现了一个环形队列作为其缓冲区buf,队列的长度是创建chan时指定的,存储了recvx 和 sendx 两个指针,表示现在已经读到了哪里,接下来往哪里写
-
等待队列 recvq 和 sendq
- 从channel读数据,如果channel缓冲区为空或者没有缓冲区,当前goroutine会被阻塞,放到sendq中
- 向channel写数据,如果channel缓冲区已满或者没有缓冲区,当前goroutine会被阻塞,放到recvq中。
- 如果是没有缓冲区的chan,那么两个队列至少有一个为空。
-
类型信息:一个channel只能传递一种类型的值,类型信息存储在hchan数据结构中。
channel读写
-
创建channel
创建channel的过程实际上是初始化hchan结构。其中类型信息和缓冲区长度由make语句传入,buf的大小则与元素大小和缓冲区长度共同决定。func makechan(t *chantype, size int) *hchan { var c *hchan c = new(hchan) c.buf = malloc(元素类型大小*size) c.elemsize = 元素类型大小 c.elemtype = 元素类型 c.dataqsiz = size return c } -
向channel写数据
- 如果等待接收队列recvq不为空,说明缓冲区中没有数据或者没有缓冲区,此时直接从recvq取出G,并把数据写入,最后把该G唤醒,结束发送过程;
- 如果缓冲区中有空余位置,将数据写入缓冲区,结束发送过程;
- 如果缓冲区中没有空余位置,将待发送数据写入G,将当前G加入sendq,进入睡眠,等待被读goroutine唤醒;
-
从channel读数据
- 如果等待发送队列sendq不为空,且没有缓冲区,直接从sendq中取出G,把G中数据读出,最后把G唤醒,结束读取过程;
- 如果等待发送队列sendq不为空,此时说明缓冲区已满,从缓冲区中首部读出数据,把G中数据写入缓冲区尾部,把G唤醒,结束读取过程;
- 如果缓冲区中有数据,则从缓冲区取出数据,结束读取过程;将当前goroutine加入recvq,进入睡眠,等待被写goroutine唤醒;
-
关闭channel
关闭channel时会把recvq中的G全部唤醒,本该写入G的数据位置为nil。把sendq中的G全部唤醒,但这些G会panic。
单向channel
顾名思义,单向channel指只能用于发送或接收数据,实际上也没有单向channel。
我们知道channel可以通过参数传递,所谓单向channel只是对channel的一种使用限制,这跟C语言使用const修饰函数参数为只读是一个道理。
func readChan(chanName <-chan int): 通过形参限定函数内部只能从channel中读取数据func writeChan(chanName chan<- int): 通过形参限定函数内部只能向channel中写入数据
一个简单的示例程序如下:
func readChan(chanName <-chan int) {
<- chanName
}
func writeChan(chanName chan<- int) {
chanName <- 1
}
func main() {
var mychan = make(chan int, 10)
writeChan(mychan)
readChan(mychan)
}
mychan是个正常的channel,而readChan()参数限制了传入的channel只能用来读,writeChan()参数限制了传入的channel只能用来写。
select
使用select可以监控多channel,比如监控多个channel,当其中某一个channel有数据时,就从其读出数据。理解为会把这个groutine挂在所有channel的读等待队列中
一个简单的示例程序如下:
package main
import (
"fmt"
"time"
)
func addNumberToChan(chanName chan int) {
for {
chanName <- 1
time.Sleep(1 * time.Second)
}
}
func main() {
var chan1 = make(chan int, 10)
var chan2 = make(chan int, 10)
go addNumberToChan(chan1)
go addNumberToChan(chan2)
for {
select {
case e := <- chan1 :
fmt.Printf("Get element from chan1: %d\n", e)
case e := <- chan2 :
fmt.Printf("Get element from chan2: %d\n", e)
default:
fmt.Printf("No element in chan1 and chan2.\n")
time.Sleep(1 * time.Second)
}
}
}
range
通过range可以持续从channel中读出数据,好像在遍历一个数组一样,当channel中没有数据时会阻塞当前goroutine,与读channel时阻塞处理机制一样。
func chanRange(chanName chan int) {
for e := range chanName {
fmt.Printf("Get element from chan: %d\n", e)
}
}
slice
Slice依托数组实现,底层数组对用户屏蔽,在底层数组容量不足时可以实现自动重分配并生成新的Slice。 自动重分配会重新找一片空间,即新老使用的数组不一样
接下来按照实际使用场景分别介绍其实现机制。
Slice数据结构
type slice struct {
array unsafe.Pointer
len int
cap int
}
从数据结构看Slice很清晰, array指针指向底层数组,len表示切片长度,cap表示底层数组容量。
-
使用make创建Slice
使用make来创建Slice时,可以同时指定长度和容量,创建时底层会分配一个数组,数组的长度即容量。 -
使用数组创建Slice
使用数组来创建Slice时,Slice将与原数组共用一部分内存。
例如,语句slice := array[5:7]所创建的Slice
根据数组或切片生成新的切片一般使用slice := array[start:end]方式,这种新生成的切片并没有指定切片的容量,实际上新切片的容量是从start开始直至array的结束。 -
Slice 扩容
使用append向Slice追加元素时,如果Slice空间不足,将会触发Slice扩容,扩容实际上是重新分配一块更大的内存,将原Slice数据拷贝进新Slice,然后返回新Slice,扩容后再将数据追加进去。 -
扩容容量的选择遵循以下规则:
- 如果原Slice容量小于1024,则新Slice容量将扩大为原来的2倍;
- 如果原Slice容量大于等于1024,则新Slice容量将扩大为原来的1.25倍;
-
使用append()向Slice添加一个元素的实现步骤如下:
- 假如Slice容量够用,则将新元素追加进去,Slice.len++,返回原Slice
- 原Slice容量不够,则将Slice先扩容,扩容后得到新Slice
- 将新元素追加进新Slice,Slice.len++,返回新的Slice。
-
Slice Copy
使用copy()内置函数拷贝两个切片时,会将源切片的数据逐个拷贝到目的切片指向的数组中,拷贝数量取两个切片长度的最小值。例如长度为10的切片拷贝到长度为5的切片时,将会拷贝5个元素。也就是说,copy过程中不会发生扩容。
Slice总结
- 每个切片都指向一个底层数组=
- 每个切片都保存了当前切片的长度、底层数组可用容量
- 使用len()计算切片长度时间复杂度为O(1),不需要遍历切片
- 使用cap()计算切片容量时间复杂度为O(1),不需要遍历切片
- 通过函数传递切片时,不会拷贝整个切片,因为切片本身只是个结构体而已
- 使用append()向切片追加元素时有可能触发扩容,扩容后将会生成新的切片
map
Golang的map使用哈希表作为底层实现,一个哈希表里可以有多个哈希表节点,也即bucket,而每个bucket就保存了map中的一个或一组键值对。
type hmap struct {
count int // 当前保存的元素个数
...
B uint8 //指针数组的size
...
buckets unsafe.Pointer // bucket数组指针,数组的大小为2^B
...
}
下图展示一个拥有4个bucket的map:
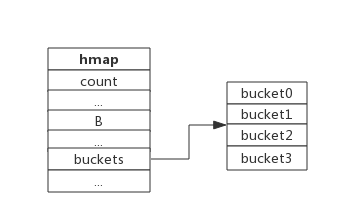
本例中, hmap.B=2, 而hmap.buckets长度是2^B为4. 元素经过哈希运算后会落到某个bucket中进行存储。查找过程类似。 一个k-v表示一个桶
bucket数据结构
type bmap struct {
tophash [8]uint8 //存储哈希值的高8位
data byte[1] //key value数据:key/key/key/.../value/value/value...
overflow *bmap //溢出bucket的地址
}
- 每个bucket可以存储8个键值对。
- tophash是个长度为8的数组,哈希值相同的键(准确的说是哈希值低位相同的键)存入当前bucket时会将哈希值的高位存储在该数组中,以方便后续匹配。
- data区存放的是key-value数据,存放顺序是key/key/key/…value/value/value,如此存放是为了节省字节对齐带来的空间浪费。
- overflow 指针指向的是下一个bucket,据此将所有冲突的键连接起来。
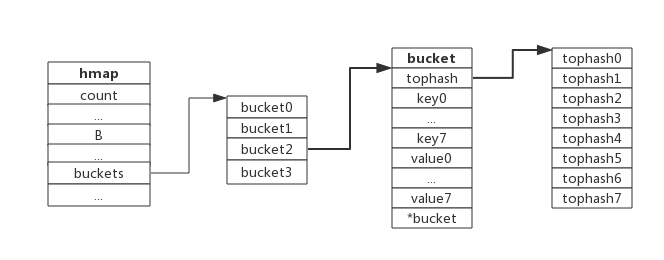
- 所以可以简单的理解为GO语言中的map其实是桶+数组(数组大小为8)+链表法解决冲突的结构
哈希冲突
-
当有两个或以上数量的键被哈希到了同一个bucket时,我们称这些键发生了冲突。Go使用链地址法来解决键冲突。
-
由于每个bucket可以存放8个键值对,所以同一个bucket存放超过8个键值对时就会再创建一个键值对,用类似链表的方式将bucket连接起来。
-
下图展示产生冲突后的map:
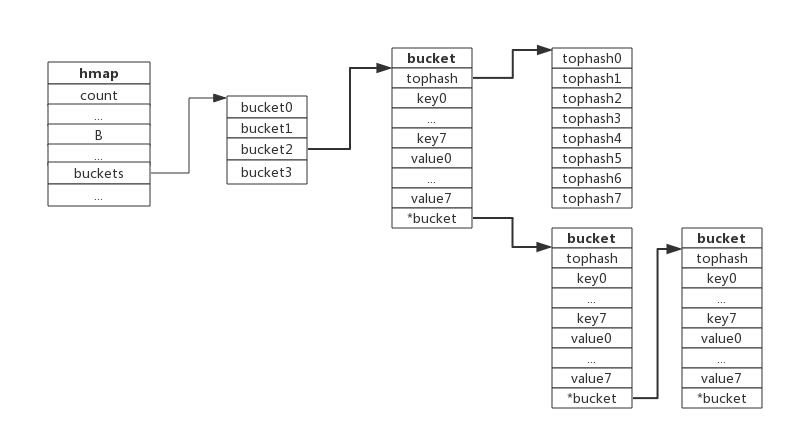
-
bucket数据结构指示下一个bucket的指针称为overflow bucket,意为当前bucket盛不下而溢出的部分。事实上哈希冲突并不是好事情,它降低了存取效率,好的哈希算法可以保证哈希值的随机性,但冲突过多也是要控制的,后面会再详细介绍。
负载因子
负载因子用于衡量一个哈希表冲突情况,公式为:
负载因子 = 键数量/bucket数量
例如,对于一个bucket数量为4,包含4个键值对的哈希表来说,这个哈希表的负载因子为1.
哈希表需要将负载因子控制在合适的大小,超过其阀值需要进行rehash,也即键值对重新组织:
- 哈希因子过小,说明空间利用率低
- 哈希因子过大,说明冲突严重,存取效率低
每个哈希表的实现对负载因子容忍程度不同,比如Redis实现中负载因子大于1时就会触发rehash,而Go则在在负载因子达到6.5时才会触发rehash,因为Redis的每个bucket只能存1个键值对,而Go的bucket可能存8个键值对,所以Go可以容忍更高的负载因子。
map 中的扩容
渐进式扩容
- 前提条件: 为了保证访问效率,当新元素将要添加进map时,都会检查是否需要扩容,扩容实际上是以空间换时间的手段。触发扩容的条件有二个:
- 负载因子 > 6.5时,也即平均每个bucket存储的键值对达到6.5个。
- overflow数量 > 2^15时,也即overflow数量超过32768时。
- 增量扩容: 当负载因子过大时,就新建一个bucket,新的bucket长度是原来的2倍,然后旧bucket数据搬迁到新的bucket。
考虑到如果map存储了数以亿计的key-value,一次性搬迁将会造成比较大的延时,Go采用逐步搬迁策略,即每次访问map时都会触发一次搬迁,每次搬迁2个键值对。- 当前map存储了7个键值对,只有1个bucket。此地负载因子为7。再次插入数据时将会触发扩容操作,扩容之后再将新插入键写入新的bucket。
- 当第8个键值对插入时,将会触发扩容:hmap数据结构中oldbuckets成员指身原bucket,而buckets指向了新申请的bucket。新的键值对被插入新的bucket中。
- 后续对map的访问操作会触发迁移,将oldbuckets中的键值对逐步的搬迁过来。当oldbuckets中的键值对全部搬迁完毕后,删除oldbuckets。
等量扩容
- 所谓等量扩容,实际上并不是扩大容量,buckets数量不变,重新做一遍类似增量扩容的搬迁动作,把松散的键值对重新排列一次,以使bucket的使用率更高,进而保证更快的存取。
- 在极端场景下,比如不断地增删,而键值对正好集中在一小部分的bucket,这样会造成overflow的bucket数量增多,但负载因子又不高,从而无法执行增量搬迁的情况,可以理解为将稀疏数据压缩到一起
查找过程
查找过程如下:
- 根据key值算出哈希值
- 取哈希值低位与hmap.B取模确定bucket位置
- 取哈希值高位在tophash数组中查询(这个过程是一个遍历的过程)
- 如果tophash[i]中存储值也哈希值相等,则去找到该bucket中的key值进行比较
- 当前bucket没有找到,则继续从下个overflow的bucket中查找。
- 如果当前处于搬迁过程,则优先从oldbuckets查找
注:如果查找不到,也不会返回空值,而是返回相应类型的0值。
插入过程
新元素插入过程如下:
- 根据key值算出哈希值
- 取哈希值低位与hmap.B取模确定bucket位置
- 查找该key是否已经存在,如果存在则直接更新值
- 如果没找到将key,将key插入
struct
Tag
Go的struct声明允许字段附带 Tag 来对字段做一些标记。
- 该Tag不仅仅是一个字符串那么简单,因为其主要用于反射场景,reflect包中提供了操作Tag的方法,所以Tag写法也要遵循一定的规则。
- Tag本身是一个字符串,但字符串中却是:以空格分隔的 key:value 对。
- key: 必须是非空字符串,字符串不能包含控制字符、空格、引号、冒号。
- value: 以双引号标记的字符串
注意:冒号前后不能有空格
如下代码所示,如此写没有实际意义,仅用于说明Tag规则
type Server struct {
ServerName string `key1: "value1" key11:"value11"`
ServerIP string `key2: "value2"`
}
上述代码 ServerName 字段的Tag包含两个key-value对。ServerIP字段的Tag只包含一个key-value对。
反射
Tag只有在反射场景中才有用,而反射包中提供了操作Tag的方法。在说方法前,有必要先了解一下Go是如何管理struct字段的。
-
以下是reflect包中的类型声明,省略了部分与本文无关的字段。
// A StructField describes a single field in a struct. type StructField struct { // Name is the field name. Name string ... Type Type // field type Tag StructTag // field tag string ... } type StructTag string可见,描述一个结构体成员的结构中包含了 StructTag,而其本身是一个string。也就是说Tag其实是结构体字段的一个组成部分。
获取Tag
-
StructTag提供了
Get(key string) string方法来获取Tag,示例如下:package main import ( "reflect" "fmt" ) type Server struct { ServerName string `key1:"value1" key11:"value11"` ServerIP string `key2:"value2"` } func main() { s := Server{} st := reflect.TypeOf(s) field1 := st.Field(0) fmt.Printf("key1:%v\n", field1.Tag.Get("key1")) fmt.Printf("key11:%v\n", field1.Tag.Get("key11")) filed2 := st.Field(1) fmt.Printf("key2:%v\n", filed2.Tag.Get("key2")) } -
程序输出如下:
key1:value1 key11:value11 key2:value2
Tag存在的意义
- 官方的encoding/json包,可以将一个JSON数据Unmarshal进一个结构体,此过程中就使用了Tag。该包定义一些规则,只要参考该规则设置tag就可以将不同的JSON数据转换成结构体。
Tag常见用法
- 常见的tag用法,主要是JSON数据解析、ORM映射等。
string
Go标准库builtin给出了所有内置类型的定义。其中关于string的描述如下:
// string is the set of all strings of 8-bit bytes, conventionally but not
// necessarily representing UTF-8-encoded text. A string may be empty, but
// not nil. Values of string type are immutable.
type string string
所以string是8比特字节的集合,通常是但并不一定非得是UTF-8编码的文本。
另外,还提到了两点,非常重要:
- string可以为空(长度为0),但不会是nil;
- string对象不可以修改。
string 数据结构
源码包src/runtime/string.go:stringStruct定义了string的数据结构:
type stringStruct struct {
str unsafe.Pointer
len int
}
其数据结构很简单:
- stringStruct.str:字符串的首地址;
- stringStruct.len:字符串的长度;
string操作
声明
-
如下代码所示,可以声明一个string变量变赋予初值:
var str string str = "Hello World" -
字符串构建过程是先根据字符串构建stringStruct,再转换成string。转换的源码如下:
func gostringnocopy(str *byte) string { // 根据字符串地址构建string ss := stringStruct{str: unsafe.Pointer(str), len: findnull(str)} // 先构造stringStruct s := *(*string)(unsafe.Pointer(&ss)) // 再将stringStruct转换成string return s } -
string在runtime包中就是stringStruct,对外呈现叫做string。
[]byte转string
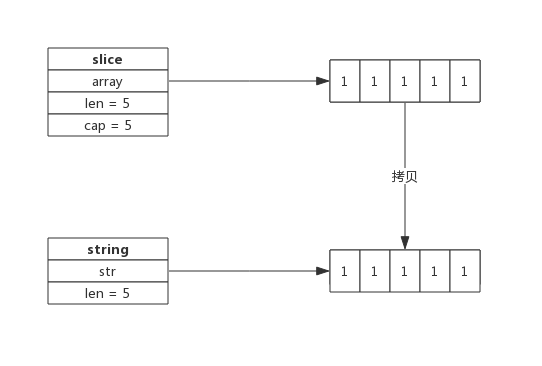
-
byte切片可以很方便的转换成string,如下所示:
func GetStringBySlice(s []byte) string { return string(s) }需要注意的是这种转换需要一次内存拷贝。
-
转换过程如下:
- 根据切片的长度申请内存空间,假设内存地址为p,切片长度为len(b);
- 构建string(string.str = p;string.len = len;)
- 拷贝数据(切片中数据拷贝到新申请的内存空间)
转换示意图:
string转[]byte
-
string也可以方便的转成byte切片,如下所示:
func GetSliceByString(str string) []byte { return []byte(str) } -
string转换成byte切片,也需要一次内存拷贝,其过程如下:
- 申请切片内存空间
- 将string拷贝到切片
-
转换示意图:

字符串拼接
-
字符串可以很方便的拼接,像下面这样:
str := "Str1" + "Str2" + "Str3"即便有非常多的字符串需要拼接,性能上也有比较好的保证,因为新字符串的内存空间是一次分配完成的,所以性能消耗主要在拷贝数据上。
-
一个拼接语句的字符串编译时都会被存放到一个切片中,拼接过程需要遍历两次切片,第一次遍历获取总的字符串长度,据此申请内存,第二次遍历会把字符串逐个拷贝过去。
字符串拼接伪代码如下:func concatstrings(a []string) string { // 字符串拼接 length := 0 // 拼接后总的字符串长度 for _, str := range a { length += len(str) } s, b := rawstring(length) // 生成指定大小的字符串,返回一个string和切片,二者共享内存空间 for _, str := range a { copy(b, str) // string无法修改,只能通过切片修改 b = b[len(str):] } return s } -
因为string是无法直接修改的,所以这里使用rawstring()方法初始化一个指定大小的string,同时返回一个切片,二者共享同一块内存空间,后面向切片中拷贝数据,也就间接修改了string。
rawstring()源代码如下:func rawstring(size int) (s string, b []byte) { // 生成一个新的string,返回的string和切片共享相同的空间 p := mallocgc(uintptr(size), nil, false) stringStructOf(&s).str = p stringStructOf(&s).len = size *(*slice)(unsafe.Pointer(&b)) = slice{p, size, size} return }
为什么字符串不允许修改?
像C++语言中的string,其本身拥有内存空间,修改string是支持的。但Go的实现中,string不包含内存空间,只有一个内存的指针,这样做的好处是string变得非常轻量,可以很方便的进行传递而不用担心内存拷贝。
- 因为string通常指向字符串字面量,而字符串字面量存储位置是只读段,而不是堆或栈上,所以才有了string不可修改的约定。
[]byte转换成string一定会拷贝内存吗?
byte切片转换成string的场景很多,为了性能上的考虑,有时候只是临时需要字符串的场景下,byte切片转换成string时并不会拷贝内存,而是直接返回一个string,这个string的指针(string.str)指向切片的内存。
比如,编译器会识别如下临时场景:
- 使用m[string(b)]来查找map(map是string为key,临时把切片b转成string);
- 字符串拼接,如”<” + “string(b)” + “>”;
- 字符串比较:string(b) == “foo”
因为是 临时 把byte切片转换成string,也就避免了因byte切片同容改成而导致string引用失败的情况,所以此时可以不必拷贝内存新建一个string。
string和[]byte如何取舍
string和[]byte都可以表示字符串,但因数据结构不同,其衍生出来的方法也不同,要根据实际应用场景来选择。
string 擅长的场景:
- 需要字符串比较的场景;
- 不需要nil字符串的场景;
[]byte擅长的场景:
- 修改字符串的场景,尤其是修改粒度为1个字节;
- 函数返回值,需要用nil表示含义的场景;
需要切片操作的场景;
- 虽然看起来string适用的场景不如[]byte多,但因为string直观,在实际应用中还是大量存在,在偏底层的实现中[]byte使用更多。















 433
433











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









