







 本文详细阐述了HDFS的文件储存机制、副本策略、负载均衡、心跳机制,以及HDFS的写入、读取流程。同时介绍了元数据管理、归档机制、HDFS安全模式和MapReduce/YARN组件的执行流程与调度策略。
本文详细阐述了HDFS的文件储存机制、副本策略、负载均衡、心跳机制,以及HDFS的写入、读取流程。同时介绍了元数据管理、归档机制、HDFS安全模式和MapReduce/YARN组件的执行流程与调度策略。
HDFS组件
储存文件的Block数据块
因为HDFS是分布式储存文件的模式,所以在储存文件的数据时,会将文件切分为大小一致的数据块,如果出现文件大小不是128M的倍数时,那么最后一个文件会与之前切分文件大小不一致。被切分成的数据块就是Block块,NameNode将Block块进行分布式储存到DataNode中。 (Block块的默认大小是128M)
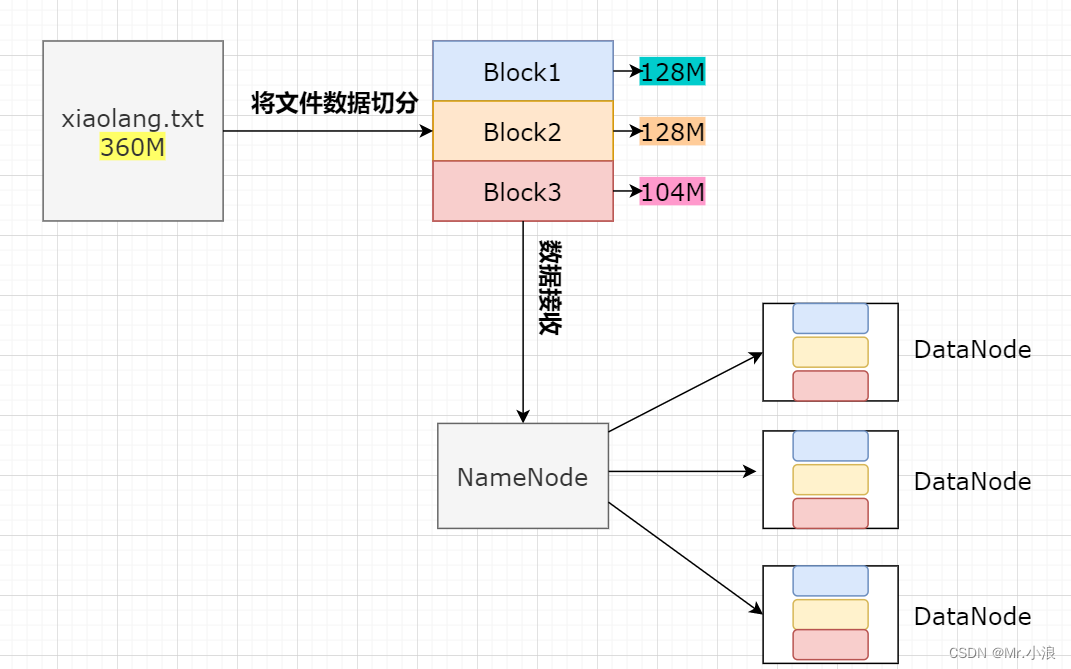
HDFS三大机制
副本机制:为了保证数据的安全和效率,将每个BLOCK块存储到多个副本中
第一副本:
优先本机,否则就近随机
第二副本:
随机保存在与第一副本不同的机柜服务器上
第三副本:
随机保存在与副本二同一机柜的不同服务器上
负载均衡机制:
NameNode为了保证DataNode中Block块大小一样,分配储存任务时,会优先分配到余量比较大的DataNode
心跳机制:
(NameNode与DataNode的沟通)
DataNode每3秒会向NameNode发送自己状态信息,当DataNode 30秒不向NameNode发送自己的状态信息时,NameNode会每隔5分钟发送一次确认消息,连续两次后,没有收到回复,就会认定DataNode宕机了。
HDFS数据的写入原理
1、首先客户端发送上传文件请求到 NameNode 。
2、其次 NameNode 判断客户端是否有权限,如果有就判断该目录下是否已经存在该文件,确认有权限并且存在文件就执行下一步。
3、第三步,客户端会对文件进行切块成最大为默认128MB大小的块,然后再向 NameNode发送请求将‘Block块’上传到哪里。
4、然后 NameNode 根据 HDFS三大机制 找到储存该块的 DataNode 列表。
5、紧接着客户端接收到 DataNode 列表后与列表中的节点连接形成传输管道,再通过数据包(MAX=64KB) 的方式传输数据,并建立 ACK(方向应答机制)。
6、具体过程是:假设有三个节点第一节点为 node1 第二节点为 node2 第三节点为 node3。node1 接收到第一个数据包后向 node2 发送接收到的数据包,同时又向客户端反馈并且接收第二个数据包,node2 向 node1
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3995
3995

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









