







目录
9.HashMap在多线程扩容后get时会造成链表的死循环问题流程
10.HashMap get的时间复杂度从O(0)->O(n)?
1.源码分析
HashMap<Object,String> map=new HashMap<>();
map.put("x","xxxx");
System.out.println(map.get("x"));
该源码是根据上面的代码进行调试后所得的结果,源码进行了主要流程的翻译和部分分析过程,有需要者可以自行copy到自己的idea工具进行分析,效果更佳
/*
* Copyright (c) 1997, 2010, Oracle and/or its affiliates. All rights reserved.
* ORACLE PROPRIETARY/CONFIDENTIAL. Use is subject to license terms.
*/
package java.util;
import java.io.*;
/**
* Hash table based implementation of the <tt>Map</tt> interface.
* Hash表是基于Map接口实现
* This implementation provides all of the optional map operations, and permits
* <tt>null</tt> values and the <tt>null</tt> key.
* 这个实现提供所有可选的map操作 并且允许为NULL的值和键
*
* (The <tt>HashMap</tt>
* class is roughly equivalent to <tt>Hashtable</tt>, except that it is
* unsynchronized and permits nulls.) This class makes no guarantees as to
* the order of the map; in particular, it does not guarantee that the order
* will remain constant over time.
*这个大致等同于Hashtable,除了它不是同步和允许为null。这个类不能保证映射顺序;
* 特别是,他不能保持顺序随着时间不变
*
*
*
* <p>This implementation provides constant-time performance for the basic
* operations (<tt>get</tt> and <tt>put</tt>), assuming the hash function
* disperses the elements properly among the buckets. Iteration over
* collection views requires time proportional to the "capacity" of the
* <tt>HashMap</tt> instance (the number of buckets) plus its size (the number
* of key-value mappings). Thus, it's very important not to set the initial
* capacity too high (or the load factor too low) if iteration performance is
* important.
* 这个实现提供空间和时间性能基于put和get操作,假设hash函数将元素合理的分布在桶中。
* 迭代集合视图所需的时间和“容量”也就是HashMap实例(桶的数量)加上它的大小(键值对映射的数量)成比例
* 当然,如果想要迭代表现很突出的话就不能将初始容量设置的很大,这是非常重要的
*
*
*
*
* <p>An instance of <tt>HashMap</tt> has two parameters that affect its
* performance: <i>initial capacity</i> and <i>load factor</i>. The
* capacity is simply the capacity at the time the hash table is created. The
* <i>load factor</i> is a measure of how full the hash table is allowed to
* get before its capacity is automatically increased. When the number of
* entries in the hash table exceeds the product of the load factor and the
* current capacity, the hash table is <i>rehashed</i> (that is, internal data
* structures are rebuilt) so that the hash table has approximately twice the
* number of buckets.
* 一个HsahMap的实例有俩个参数,具体表现在:初始容量和加载因子。
* 它的初始容量是在创建表的时候的容量。
* 它的加载因子是在一定程度上允许哈希表容量在自动增加满了之前的一个刻度。
* 当哈希表里面的对象数量超过负载因子和当前容量的乘积,那么哈希表会重新处理(理解为:扩容)
* (即内部数据重建结构)相当于将哈希表翻了将近俩倍
*
*
*
*
* <p>As a general rule, the default load factor (.75) offers a good tradeoff
* between time and space costs. Higher values decrease the space overhead
* but increase the lookup cost (reflected in most of the operations of the
* <tt>HashMap</tt> class, including <tt>get</tt> and <tt>put</tt>). The
* expected number of entries in the map and its load factor should be taken
* into account when setting its initial capacity, so as to minimize the
* number of rehash operations. If the initial capacity is greater
* than the maximum number of entries divided by the load factor, no
* rehash operations will ever occur.
* 一个普遍的规则,这个默认的加载因子(0.75)提供了空间和时间上成本的平衡。
* 较高的值会减少空间的开心,但是会增加查找的成本(反映在更多的HashMap类操作上,包括get和put)。
* 在设置它的初始容量的时候应该要考虑到map的预期对象数量和加载因子,从而减少rehash的操作次数。
* 如果初始容量大于对象的数量除以加载因子,那么rehash永远不会发生。
*
*
*
* <p>If many mappings are to be stored in a <tt>HashMap</tt> instance,
* creating it with a sufficiently large capacity will allow the mappings to
* be stored more efficiently than letting it perform automatic rehashing as
* needed to grow the table.
* 如果许多的映射被存储在HashMap的实例中,创建一个足够大小的容量会允许映射存储更有效的存储
* 而不是让他自动增长(扩容)哈希表
*
*
*
* <p><strong>Note that this implementation is not synchronized.</strong>
* If multiple threads access a hash map concurrently, and at least one of
* the threads modifies the map structurally, it <i>must</i> be
* synchronized externally. (A structural modification is any operation
* that adds or deletes one or more mappings; merely changing the value
* associated with a key that an instance already contains is not a
* structural modification.) This is typically accomplished by
* synchronizing on some object that naturally encapsulates the map.
* 注意这个实现不是一个同步的。
* 如果一个多线程同时执行一个hashMap,并且至少一个线程修改了map的结构,它必须外部同步。
* (结构修改是指新增和删除的一个或者更多的映射操作;仅仅改变的值所关联的键并不是结构修改。)
* 这通常在自然封装对象上完成同步
*
*
*
* If no such object exists, the map should be "wrapped" using the
* {@link Collections#synchronizedMap Collections.synchronizedMap}
* method. This is best done at creation time, to prevent accidental
* unsynchronized access to the map:<pre>
* Map m = Collections.synchronizedMap(new HashMap(...));</pre>
* 如果不存在这样一个对象,则映射应该使用{@link Collections#synchronizedMap Collections.synchronizedMap}
* 这样一个方法,在创建的时候就完成,防止造成不同步的情况发生
*
*
* <p>The iterators returned by all of this class's "collection view methods"
* are <i>fail-fast</i>: if the map is structurally modified at any time after
* the iterator is created, in any way except through the iterator's own
* <tt>remove</tt> method, the iterator will throw a
* {@link ConcurrentModificationException}. Thus, in the face of concurrent
* modification, the iterator fails quickly and cleanly, rather than risking
* arbitrary, non-deterministic behavior at an undetermined time in the
* future.
* 这个迭代器返回所有这类的“集合视图方法” 快速失败:
* 如果这个映射在迭代创建之前发生了结构修改,任何方式除了迭代器的本身移除方法,
* 那么迭代器会抛出一个{@link ConcurrentModificationException}异常。
* 当然,在面对同时修改,迭代器会快速干净的失败,而不是在未来未确定时间冒着风险做任意、不确定的行为。
*
*
*
* <p>Note that the fail-fast behavior of an iterator cannot be guaranteed
* as it is, generally speaking, impossible to make any hard guarantees in the
* presence of unsynchronized concurrent modification. Fail-fast iterators
* throw <tt>ConcurrentModificationException</tt> on a best-effort basis.
* Therefore, it would be wrong to write a program that depended on this
* exception for its correctness: <i>the fail-fast behavior of iterators
* should be used only to detect bugs.</i>
* 注意不能保证迭代器快速失败的行为,一般来说,在不同步并发修改的面前,可能不能保证。
* 快速失败迭代器在最大的努力上抛出ConcurrentModificationException
* 因此,写一个依赖与这个异常正确性的程序是错误的:快速失败行为迭代器应该只能被用来
* 检测bug。
*
* <p>This class is a member of the
* <a href="{@docRoot}/../technotes/guides/collections/index.html">
* Java Collections Framework</a>.
*
* @param <K> the type of keys maintained by this map
* @param <V> the type of mapped values
*
* @author Doug Lea
* @author Josh Bloch
* @author Arthur van Hoff
* @author Neal Gafter
* @see Object#hashCode()
* @see Collection
* @see Map
* @see TreeMap
* @see Hashtable
* @since 1.2
*/
public class HashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable
{
/**
* The default initial capacity - MUST be a power of two. 默认初始容量 必须为2的指数次幂
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**
* The maximum capacity, used if a higher value is implicitly specified
* by either of the constructors with arguments.
* MUST be a power of two <= 1<<30.
*
* 最大的容量,如果要指定一个较大的值
* 要用另外一个带参的构造函数
* 必须是2的指数次幂
*
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* The load factor used when none specified in constructor. 当没有用指定函数的默认加载因子
* 为什么这个默认的加载因子为
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* An empty table instance to share when the table is not inflated. 一个空table数组实例
*/
static final Entry<?,?>[] EMPTY_TABLE = {};
/**
* The table, resized as necessary(根据需要调整). Length MUST Always be a power of two.
*/
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
/**
* The number of key-value mappings contained in this map. 键值对的数量 不需要被序列化
*/
transient int size;
/**
* The next size value at which to resize (capacity * load factor).
* @serial
*/
// If table == EMPTY_TABLE then this is the initial capacity at which the
// table will be created when inflated.
int threshold;
/**
* The load factor for the hash table.
*
* @serial
*/
final float loadFactor;
/**
* The number of times this HashMap has been structurally modified
* Structural modifications are those that change the number of mappings in
* the HashMap or otherwise modify its internal structure (e.g.,
* rehash). This field is used to make iterators on Collection-views of
* the HashMap fail-fast. (See ConcurrentModificationException).
*记录HashMap结构改变次数
*/
transient int modCount;
/**
* The default threshold of map capacity above which alternative hashing is
* used for String keys. Alternative hashing reduces the incidence of
* collisions due to weak hash code calculation for String keys.
* <p/>
* This value may be overridden by defining the system property
* {@code jdk.map.althashing.threshold}. A property value of {@code 1}
* forces alternative hashing to be used at all times whereas
* {@code -1} value ensures that alternative hashing is never used.
*/
static final int ALTERNATIVE_HASHING_THRESHOLD_DEFAULT = Integer.MAX_VALUE;
/**
* holds values which can't be initialized until after VM is booted.
*/
private static class Holder {
/**
* Table capacity above which to switch to use alternative hashing.
*/
static final int ALTERNATIVE_HASHING_THRESHOLD;
static {
String altThreshold = java.security.AccessController.doPrivileged(
new sun.security.action.GetPropertyAction(
"jdk.map.althashing.threshold"));
int threshold;
try {
threshold = (null != altThreshold)
? Integer.parseInt(altThreshold)
: ALTERNATIVE_HASHING_THRESHOLD_DEFAULT;
// disable alternative hashing if -1
if (threshold == -1) {
threshold = Integer.MAX_VALUE;
}
if (threshold < 0) {
throw new IllegalArgumentException("value must be positive integer.");
}
} catch(IllegalArgumentException failed) {
throw new Error("Illegal value for 'jdk.map.althashing.threshold'", failed);
}
ALTERNATIVE_HASHING_THRESHOLD = threshold;
}
}
/**
* A randomizing value associated with this instance that is applied to
* hash code of keys to make hash collisions harder to find. If 0 then
* alternative hashing is disabled.
*/
transient int hashSeed = 0;
/**
* Constructs an empty <tt>HashMap</tt> with the specified initial
* capacity and load factor.
*
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
threshold = initialCapacity;
init(); //这个是个空方法 (开发人员可以进行逻辑拓展)
}
/**
* Constructs an empty <tt>HashMap</tt> with the specified initial
* capacity and the default load factor (0.75).
*
* @param initialCapacity the initial capacity.
* @throws IllegalArgumentException if the initial capacity is negative.
*/
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
/**
* Constructs an empty <tt>HashMap</tt> with the default initial capacity
* (16) and the default load factor (0.75).
* 在实例化(new Hash())的时候进行默认参数条件(容量和加载因子)的处理 并未进行初始化创建
*/
public HashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
/**
* Constructs a new <tt>HashMap</tt> with the same mappings as the
* specified <tt>Map</tt>. The <tt>HashMap</tt> is created with
* default load factor (0.75) and an initial capacity sufficient to
* hold the mappings in the specified <tt>Map</tt>.
*
* @param m the map whose mappings are to be placed in this map
* @throws NullPointerException if the specified map is null
*/
public HashMap(Map<? extends K, ? extends V> m) {
this(Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1,
DEFAULT_INITIAL_CAPACITY), DEFAULT_LOAD_FACTOR);
inflateTable(threshold);
putAllForCreate(m);
}
private static int roundUpToPowerOf2(int number) {
// assert number >= 0 : "number must be non-negative";
return number >= MAXIMUM_CAPACITY
? MAXIMUM_CAPACITY
: (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1;
}
/**
* Inflates the table.
*/
private void inflateTable(int toSize) {
// Find a power of 2 >= toSize
int capacity = roundUpToPowerOf2(toSize); // 初始化结果16 这个函数作用是往上浮动2的指数次幂 例如:toSize为17的话 capacity=浮动为2的5次幂=32
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1); //初始化结果12 这里是后面的扩容阈值
table = new Entry[capacity]; //初始化数组也就是hash表容量为16 表中bucket数量16个
initHashSeedAsNeeded(capacity);
}
// internal utilities
/**
* Initialization hook for subclasses. This method is called
* in all constructors and pseudo-constructors (clone, readObject)
* after HashMap has been initialized but before any entries have
* been inserted. (In the absence of this method, readObject would
* require explicit knowledge of subclasses.)
*/
void init() {
}
/**
* Initialize the hashing mask value. We defer initialization until we
* really need it.
*/
final boolean initHashSeedAsNeeded(int capacity) {
boolean currentAltHashing = hashSeed != 0; // 初始为currentAltHashing=false
boolean useAltHashing = sun.misc.VM.isBooted() &&
(capacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);
boolean switching = currentAltHashing ^ useAltHashing;
if (switching) {
hashSeed = useAltHashing
? sun.misc.Hashing.randomHashSeed(this)
: 0;
}
return switching;
}
/**
* Retrieve object hash code and applies a supplemental hash function to the
* result hash, which defends against poor quality hash functions. This is
* critical because HashMap uses power-of-two length hash tables, that
* otherwise encounter collisions for hashCodes that do not differ
* in lower bits. Note: Null keys always map to hash 0, thus index 0.
*
* 检索key值对象的哈希码并且对使用哈希函数对哈希结果进行补充,防止质量差的哈希函数。
* 这是至关重要的,因为HsahMap使用的是2的幂次方的哈希表,否则后遇到较低位相同的哈希冲突。
* 注意:Null key映射hash值是0,也就是索引下标为0
*
*
*
*/
final int hash(Object k) {
int h = hashSeed; //hashSeed 在
if (0 != h && k instanceof String) { //这个是对字符串hash处理
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by 确保hashCode唯一
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
/**
* 这一块是通过二进制右移异或运算(让高位也参与后面得hash值的计算)
* 后面再计算索引位置的时候后说明原因
*/
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
/**
* Returns index for hash code h.
*/
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
/**
* 问题1:为什么不用取模运算
* 问题2:为什么length长度一定要为2的幂次方
* 问题3:为什么h在之前hash计算时要用右(>>>)移
*
* 问题1 答:经过测试计算位运算的效率是取模运算的27倍 (可验证)
* 问题2 答:
* 举个例子1:
* 假如h的二进制为 1010....1000100111 (length-1)=17-1=16>二进制:000000...000010000
* 1010....1000100111 & 000000...0000010000 他的结果只有俩种 要么是0000...0000 要么是 0000...10000
* 转化为十进制也就是 0和16 重度hash碰撞
*
* 例子2: 1010....1000100111 & 000000...0000010010 他的结果是 00000 和 10000 和 000010 和10010
* 所以 细致去发现,只要(length-1)的结果低位出现0,那么必定会有空的下表没数据,bucket为空
* 只要(length-1)为单数 即length为2的幂次方 其结果低位都是1 即不会出现空桶。
*
* 问题3 答:
* 例如上述:1010....1000100111 & 000000...0000010000
* 1010....1000100111高位 为1010 000000...0000010000 高位为 00000
* 那么结果都是0,这样的话 高位参与计算不具有意义,所以要在 h计算hash值得时候就处理高位计算
* 这样的结果hash碰撞几率更小,下标更能均等分布。
*
*
*/
return h & (length-1);
}
/**
* Returns the number of key-value mappings in this map.
*
* @return the number of key-value mappings in this map
*/
public int size() {
return size;
}
/**
* Returns <tt>true</tt> if this map contains no key-value mappings.
*
* @return <tt>true</tt> if this map contains no key-value mappings
*/
public boolean isEmpty() {
return size == 0;
}
/**
* Returns the value to which the specified key is mapped,
* or {@code null} if this map contains no mapping for the key.
*
* <p>More formally, if this map contains a mapping from a key
* {@code k} to a value {@code v} such that {@code (key==null ? k==null :
* key.equals(k))}, then this method returns {@code v}; otherwise
* it returns {@code null}. (There can be at most one such mapping.)
*
* <p>A return value of {@code null} does not <i>necessarily</i>
* indicate that the map contains no mapping for the key; it's also
* possible that the map explicitly maps the key to {@code null}.
* The {@link #containsKey containsKey} operation may be used to
* distinguish these two cases.
*
* @see #put(Object, Object)
*/
public V get(Object key) {
if (key == null)
return getForNullKey();
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}
/**
* Offloaded version of get() to look up null keys. Null keys map
* to index 0. This null case is split out into separate methods
* for the sake of performance in the two most commonly used
* operations (get and put), but incorporated with conditionals in
* others.
*/
private V getForNullKey() {
if (size == 0) {
return null;
}
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
}
/**
* Returns <tt>true</tt> if this map contains a mapping for the
* specified key.
*
* @param key The key whose presence in this map is to be tested
* @return <tt>true</tt> if this map contains a mapping for the specified
* key.
*/
public boolean containsKey(Object key) {
return getEntry(key) != null;
}
/**
* Returns the entry associated with the specified key in the
* HashMap. Returns null if the HashMap contains no mapping
* for the key.
*/
final Entry<K,V> getEntry(Object key) {
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : hash(key);
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
/**
* Associates the specified value with the specified key in this map.
* If the map previously contained a mapping for the key, the old
* value is replaced.
*
* @param key key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @return the previous value associated with <tt>key</tt>, or
* <tt>null</tt> if there was no mapping for <tt>key</tt>.
* (A <tt>null</tt> return can also indicate that the map
* previously associated <tt>null</tt> with <tt>key</tt>.)
*/
public V put(K key, V value) { //往HashMap里设值
if (table == EMPTY_TABLE) { //如果为空的
inflateTable(threshold); //初始化容量 threshold在实例化的时候默认值为16
}
if (key == null)
return putForNullKey(value); //空值处理
int hash = hash(key); //key的hash值计算
int i = indexFor(hash, table.length); //下标索引计算
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i); //新增对象
return null;
}
/**
* Offloaded version of put for null keys
*/
private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) { //若table表中有数据
if (e.key == null) { //找到为Null的key
V oldValue = e.value; //table中当前的value值赋值给oldValue属性
e.value = value; //新值替换旧值
e.recordAccess(this); //这是个空方法
return oldValue; // 返回旧值
}
}
modCount++; //结构发生改变进行++
addEntry(0, null, value, 0); //若table表中无数据 null Key和值放入table第一位
return null; //无旧值 返回null
}
/**
* This method is used instead of put by constructors and
* pseudoconstructors (clone, readObject). It does not resize the table,
* check for comodification, etc. It calls createEntry rather than
* addEntry.
*/
private void putForCreate(K key, V value) {
int hash = null == key ? 0 : hash(key);
int i = indexFor(hash, table.length);
/**
* Look for preexisting entry for key. This will never happen for
* clone or deserialize. It will only happen for construction if the
* input Map is a sorted map whose ordering is inconsistent w/ equals.
*/
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
e.value = value;
return;
}
}
createEntry(hash, key, value, i);
}
private void putAllForCreate(Map<? extends K, ? extends V> m) {
for (Map.Entry<? extends K, ? extends V> e : m.entrySet())
putForCreate(e.getKey(), e.getValue());
}
/**
* Rehashes the contents of this map into a new array with a
* larger capacity. This method is called automatically when the
* number of keys in this map reaches its threshold.
* Rehashes的内容是重新创建一个新的更大初始容量的数组。
* 当键的数量超过了map的阈值这个方法自动调用
*
* If current capacity is MAXIMUM_CAPACITY, this method does not
* resize the map, but sets threshold to Integer.MAX_VALUE.
* This has the effect of preventing future calls.
* 若当前的容量已经是最大的了,这个方法不会改变map的大小,但是会把阈值设置到最大,这是将来最有价值的预防
*
* @param newCapacity the new capacity, MUST be a power of two;
* must be greater than current capacity unless current
* capacity is MAXIMUM_CAPACITY (in which case value
* is irrelevant).
*/
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length; //表的大小
if (oldCapacity == MAXIMUM_CAPACITY) { //若当前的容量已经是最大的了,这个方法不会改变map的大小,
threshold = Integer.MAX_VALUE; //但是会把阈值设置到最大,这是将来最有价值的预防
return;
}
Entry[] newTable = new Entry[newCapacity]; //新的容量table
transfer(newTable, initHashSeedAsNeeded(newCapacity)); //扩容操作
table = newTable; //使用新table
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1); //新的阈值 超过扩容
}
/**
* Transfers all entries from current table to newTable.
* 从当前的表转移所有的对象到新表
*/
void transfer(Entry[] newTable, boolean rehash) { //扩容方法 这个方法在多线程的环境下扩容后 get时会造成链表的死循环
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
/**
* Copies all of the mappings from the specified map to this map.
* These mappings will replace any mappings that this map had for
* any of the keys currently in the specified map.
*
* @param m mappings to be stored in this map
* @throws NullPointerException if the specified map is null
*/
public void putAll(Map<? extends K, ? extends V> m) {
int numKeysToBeAdded = m.size();
if (numKeysToBeAdded == 0)
return;
if (table == EMPTY_TABLE) {
inflateTable((int) Math.max(numKeysToBeAdded * loadFactor, threshold));
}
/*
* Expand the map if the map if the number of mappings to be added
* is greater than or equal to threshold. This is conservative; the
* obvious condition is (m.size() + size) >= threshold, but this
* condition could result in a map with twice the appropriate capacity,
* if the keys to be added overlap with the keys already in this map.
* By using the conservative calculation, we subject ourself
* to at most one extra resize.
*/
if (numKeysToBeAdded > threshold) {
int targetCapacity = (int)(numKeysToBeAdded / loadFactor + 1);
if (targetCapacity > MAXIMUM_CAPACITY)
targetCapacity = MAXIMUM_CAPACITY;
int newCapacity = table.length;
while (newCapacity < targetCapacity)
newCapacity <<= 1;
if (newCapacity > table.length)
resize(newCapacity);
}
for (Map.Entry<? extends K, ? extends V> e : m.entrySet())
put(e.getKey(), e.getValue());
}
/**
* Removes the mapping for the specified key from this map if present.
*
* @param key key whose mapping is to be removed from the map
* @return the previous value associated with <tt>key</tt>, or
* <tt>null</tt> if there was no mapping for <tt>key</tt>.
* (A <tt>null</tt> return can also indicate that the map
* previously associated <tt>null</tt> with <tt>key</tt>.)
*/
public V remove(Object key) {
Entry<K,V> e = removeEntryForKey(key);
return (e == null ? null : e.value);
}
/**
* Removes and returns the entry associated with the specified key
* in the HashMap. Returns null if the HashMap contains no mapping
* for this key.
*/
final Entry<K,V> removeEntryForKey(Object key) {
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : hash(key);
int i = indexFor(hash, table.length);
Entry<K,V> prev = table[i];
Entry<K,V> e = prev;
while (e != null) {
Entry<K,V> next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
modCount++;
size--;
if (prev == e)
table[i] = next;
else
prev.next = next;
e.recordRemoval(this);
return e;
}
prev = e;
e = next;
}
return e;
}
/**
* Special version of remove for EntrySet using {@code Map.Entry.equals()}
* for matching.
*/
final Entry<K,V> removeMapping(Object o) {
if (size == 0 || !(o instanceof Map.Entry))
return null;
Map.Entry<K,V> entry = (Map.Entry<K,V>) o;
Object key = entry.getKey();
int hash = (key == null) ? 0 : hash(key);
int i = indexFor(hash, table.length);
Entry<K,V> prev = table[i];
Entry<K,V> e = prev;
while (e != null) {
Entry<K,V> next = e.next;
if (e.hash == hash && e.equals(entry)) {
modCount++;
size--;
if (prev == e)
table[i] = next;
else
prev.next = next;
e.recordRemoval(this);
return e;
}
prev = e;
e = next;
}
return e;
}
/**
* Removes all of the mappings from this map.
* The map will be empty after this call returns.
*/
public void clear() {
modCount++;
Arrays.fill(table, null);
size = 0;
}
/**
* Returns <tt>true</tt> if this map maps one or more keys to the
* specified value.
*
* @param value value whose presence in this map is to be tested
* @return <tt>true</tt> if this map maps one or more keys to the
* specified value
*/
public boolean containsValue(Object value) {
if (value == null)
return containsNullValue();
Entry[] tab = table;
for (int i = 0; i < tab.length ; i++)
for (Entry e = tab[i] ; e != null ; e = e.next)
if (value.equals(e.value))
return true;
return false;
}
/**
* Special-case code for containsValue with null argument
*/
private boolean containsNullValue() {
Entry[] tab = table;
for (int i = 0; i < tab.length ; i++)
for (Entry e = tab[i] ; e != null ; e = e.next)
if (e.value == null)
return true;
return false;
}
/**
* Returns a shallow copy of this <tt>HashMap</tt> instance: the keys and
* values themselves are not cloned.
*
* @return a shallow copy of this map
*/
public Object clone() {
HashMap<K,V> result = null;
try {
result = (HashMap<K,V>)super.clone();
} catch (CloneNotSupportedException e) {
// assert false;
}
if (result.table != EMPTY_TABLE) {
result.inflateTable(Math.min(
(int) Math.min(
size * Math.min(1 / loadFactor, 4.0f),
// we have limits...
HashMap.MAXIMUM_CAPACITY),
table.length));
}
result.entrySet = null;
result.modCount = 0;
result.size = 0;
result.init();
result.putAllForCreate(this);
return result;
}
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o;
Object k1 = getKey();
Object k2 = e.getKey();
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
Object v1 = getValue();
Object v2 = e.getValue();
if (v1 == v2 || (v1 != null && v1.equals(v2)))
return true;
}
return false;
}
public final int hashCode() {
return Objects.hashCode(getKey()) ^ Objects.hashCode(getValue());
}
public final String toString() {
return getKey() + "=" + getValue();
}
/**
* This method is invoked whenever the value in an entry is
* overwritten by an invocation of put(k,v) for a key k that's already
* in the HashMap.
*/
void recordAccess(HashMap<K,V> m) {
}
/**
* This method is invoked whenever the entry is
* removed from the table.
*/
void recordRemoval(HashMap<K,V> m) {
}
}
/**
* Adds a new entry with the specified key, value and hash code to
* the specified bucket. It is the responsibility of this
* 新增一个新的对象指定键,值和哈希码指定到桶,这是职责
*
* method to resize the table if appropriate.
* 方法调整表的大小
*
* Subclass overrides this to alter the behavior of put method.
* 子类重写它改变put的行为
*
*/
void addEntry(int hash, K key, V value, int bucketIndex) { //核心方法
if ((size >= threshold) && (null != table[bucketIndex])) { //当前Hashtable里面的数量大于或者等于阈值(容量*加载因子) 并且当前下标位置有对象
resize(2 * table.length); //进行扩容处理 调整大小
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex); //新增对象
}
/**
* Like addEntry except that this version is used when creating entries
* as part of Map construction or "pseudo-construction" (cloning,
* deserialization). This version needn't worry about resizing the table.
*
* Subclass overrides this to alter the behavior of HashMap(Map),
* clone, and readObject.
*/
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e); //当前计算出来得下表赋上值
size++; //这里计算容器Hashtable里面的数量 (数组+链表)
}
private abstract class HashIterator<E> implements Iterator<E> {
Entry<K,V> next; // next entry to return
int expectedModCount; // For fast-fail
int index; // current slot
Entry<K,V> current; // current entry
HashIterator() {
expectedModCount = modCount;
if (size > 0) { // advance to first entry
Entry[] t = table;
while (index < t.length && (next = t[index++]) == null)
;
}
}
public final boolean hasNext() {
return next != null;
}
final Entry<K,V> nextEntry() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
Entry<K,V> e = next;
if (e == null)
throw new NoSuchElementException();
if ((next = e.next) == null) {
Entry[] t = table;
while (index < t.length && (next = t[index++]) == null)
;
}
current = e;
return e;
}
public void remove() {
if (current == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
Object k = current.key;
current = null;
HashMap.this.removeEntryForKey(k);
expectedModCount = modCount;
}
}
private final class ValueIterator extends HashIterator<V> {
public V next() {
return nextEntry().value;
}
}
private final class KeyIterator extends HashIterator<K> {
public K next() {
return nextEntry().getKey();
}
}
private final class EntryIterator extends HashIterator<Map.Entry<K,V>> {
public Map.Entry<K,V> next() {
return nextEntry();
}
}
// Subclass overrides these to alter behavior of views' iterator() method
Iterator<K> newKeyIterator() {
return new KeyIterator();
}
Iterator<V> newValueIterator() {
return new ValueIterator();
}
Iterator<Map.Entry<K,V>> newEntryIterator() {
return new EntryIterator();
}
// Views
private transient Set<Map.Entry<K,V>> entrySet = null;
/**
* Returns a {@link Set} view of the keys contained in this map.
* The set is backed by the map, so changes to the map are
* reflected in the set, and vice-versa. If the map is modified
* while an iteration over the set is in progress (except through
* the iterator's own <tt>remove</tt> operation), the results of
* the iteration are undefined. The set supports element removal,
* which removes the corresponding mapping from the map, via the
* <tt>Iterator.remove</tt>, <tt>Set.remove</tt>,
* <tt>removeAll</tt>, <tt>retainAll</tt>, and <tt>clear</tt>
* operations. It does not support the <tt>add</tt> or <tt>addAll</tt>
* operations.
*/
public Set<K> keySet() {
Set<K> ks = keySet;
return (ks != null ? ks : (keySet = new KeySet()));
}
private final class KeySet extends AbstractSet<K> {
public Iterator<K> iterator() {
return newKeyIterator();
}
public int size() {
return size;
}
public boolean contains(Object o) {
return containsKey(o);
}
public boolean remove(Object o) {
return HashMap.this.removeEntryForKey(o) != null;
}
public void clear() {
HashMap.this.clear();
}
}
/**
* Returns a {@link Collection} view of the values contained in this map.
* The collection is backed by the map, so changes to the map are
* reflected in the collection, and vice-versa. If the map is
* modified while an iteration over the collection is in progress
* (except through the iterator's own <tt>remove</tt> operation),
* the results of the iteration are undefined. The collection
* supports element removal, which removes the corresponding
* mapping from the map, via the <tt>Iterator.remove</tt>,
* <tt>Collection.remove</tt>, <tt>removeAll</tt>,
* <tt>retainAll</tt> and <tt>clear</tt> operations. It does not
* support the <tt>add</tt> or <tt>addAll</tt> operations.
*/
public Collection<V> values() {
Collection<V> vs = values;
return (vs != null ? vs : (values = new Values()));
}
private final class Values extends AbstractCollection<V> {
public Iterator<V> iterator() {
return newValueIterator();
}
public int size() {
return size;
}
public boolean contains(Object o) {
return containsValue(o);
}
public void clear() {
HashMap.this.clear();
}
}
/**
* Returns a {@link Set} view of the mappings contained in this map.
* The set is backed by the map, so changes to the map are
* reflected in the set, and vice-versa. If the map is modified
* while an iteration over the set is in progress (except through
* the iterator's own <tt>remove</tt> operation, or through the
* <tt>setValue</tt> operation on a map entry returned by the
* iterator) the results of the iteration are undefined. The set
* supports element removal, which removes the corresponding
* mapping from the map, via the <tt>Iterator.remove</tt>,
* <tt>Set.remove</tt>, <tt>removeAll</tt>, <tt>retainAll</tt> and
* <tt>clear</tt> operations. It does not support the
* <tt>add</tt> or <tt>addAll</tt> operations.
*
* @return a set view of the mappings contained in this map
*/
public Set<Map.Entry<K,V>> entrySet() {
return entrySet0();
}
private Set<Map.Entry<K,V>> entrySet0() {
Set<Map.Entry<K,V>> es = entrySet;
return es != null ? es : (entrySet = new EntrySet());
}
private final class EntrySet extends AbstractSet<Map.Entry<K,V>> {
public Iterator<Map.Entry<K,V>> iterator() {
return newEntryIterator();
}
public boolean contains(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry<K,V> e = (Map.Entry<K,V>) o;
Entry<K,V> candidate = getEntry(e.getKey());
return candidate != null && candidate.equals(e);
}
public boolean remove(Object o) {
return removeMapping(o) != null;
}
public int size() {
return size;
}
public void clear() {
HashMap.this.clear();
}
}
/**
* Save the state of the <tt>HashMap</tt> instance to a stream (i.e.,
* serialize it).
*
* @serialData The <i>capacity</i> of the HashMap (the length of the
* bucket array) is emitted (int), followed by the
* <i>size</i> (an int, the number of key-value
* mappings), followed by the key (Object) and value (Object)
* for each key-value mapping. The key-value mappings are
* emitted in no particular order.
*/
private void writeObject(java.io.ObjectOutputStream s)
throws IOException
{
// Write out the threshold, loadfactor, and any hidden stuff
s.defaultWriteObject();
// Write out number of buckets
if (table==EMPTY_TABLE) {
s.writeInt(roundUpToPowerOf2(threshold));
} else {
s.writeInt(table.length);
}
// Write out size (number of Mappings)
s.writeInt(size);
// Write out keys and values (alternating)
if (size > 0) {
for(Map.Entry<K,V> e : entrySet0()) {
s.writeObject(e.getKey());
s.writeObject(e.getValue());
}
}
}
private static final long serialVersionUID = 362498820763181265L;
/**
* Reconstitute the {@code HashMap} instance from a stream (i.e.,
* deserialize it).
*/
private void readObject(java.io.ObjectInputStream s)
throws IOException, ClassNotFoundException
{
// Read in the threshold (ignored), loadfactor, and any hidden stuff
s.defaultReadObject();
if (loadFactor <= 0 || Float.isNaN(loadFactor)) {
throw new InvalidObjectException("Illegal load factor: " +
loadFactor);
}
// set other fields that need values
table = (Entry<K,V>[]) EMPTY_TABLE;
// Read in number of buckets
s.readInt(); // ignored.
// Read number of mappings
int mappings = s.readInt();
if (mappings < 0)
throw new InvalidObjectException("Illegal mappings count: " +
mappings);
// capacity chosen by number of mappings and desired load (if >= 0.25)
int capacity = (int) Math.min(
mappings * Math.min(1 / loadFactor, 4.0f),
// we have limits...
HashMap.MAXIMUM_CAPACITY);
// allocate the bucket array;
if (mappings > 0) {
inflateTable(capacity);
} else {
threshold = capacity;
}
init(); // Give subclass a chance to do its thing.
// Read the keys and values, and put the mappings in the HashMap
for (int i = 0; i < mappings; i++) {
K key = (K) s.readObject();
V value = (V) s.readObject();
putForCreate(key, value);
}
}
// These methods are used when serializing HashSets
int capacity() { return table.length; }
float loadFactor() { return loadFactor; }
}
2.HashMap put Null值如何处理?
/**
* Offloaded version of put for null keys
*/
private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) { //若table表中有数据
if (e.key == null) { //找到为Null的key
V oldValue = e.value; //table中当前的value值赋值给oldValue属性
e.value = value; //新值替换旧值
e.recordAccess(this); //这是个空方法
return oldValue; // 返回旧值
}
}
modCount++; //结构发生改变进行++
addEntry(0, null, value, 0); //若table表中无数据 null Key和值放入table第一位
return null; //无旧值 返回null
}3.为什么key在计算hash的时候要用右移(>>>)?
/**
* Retrieve object hash code and applies a supplemental hash function to the
* result hash, which defends against poor quality hash functions. This is
* critical because HashMap uses power-of-two length hash tables, that
* otherwise encounter collisions for hashCodes that do not differ
* in lower bits. Note: Null keys always map to hash 0, thus index 0.
*
* 检索key值对象的哈希码并且对使用哈希函数对哈希结果进行补充,防止质量差的哈希函数。
* 这是至关重要的,因为HsahMap使用的是2的幂次方的哈希表,否则后遇到较低位相同的哈希冲突。
* 注意:Null key映射hash值是0,也就是索引下标为0
*
*
*
*/
final int hash(Object k) {
int h = hashSeed; //hashSeed 在
if (0 != h && k instanceof String) { //这个是对字符串hash处理
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by 确保hashCode唯一
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
/**
* 这一块是通过二进制右移异或运算(让高位也参与后面得hash值的计算)
* 后面再计算索引位置的时候后说明原因
*/
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
4.在计算下标索引的时候是不是用的取模运算?

5.在计算下标索引的时候数组的长度为什么要是2的指数次幂?
/**
* Returns index for hash code h.
*/
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
/**
* 问题1:为什么不用取模运算
* 问题2:为什么length长度一定要为2的幂次方
* 问题3:为什么h在之前hash计算时要用右(>>>)移
*
* 问题1 答:经过测试计算位运算的效率是取模运算的27倍 (可验证)
* 问题2 答:
* 举个例子1:
* 假如h的二进制为 1010....1000100111 (length-1)=17-1=16>二进制:000000...000010000
* 1010....1000100111 & 000000...0000010000 他的结果只有俩种 要么是0000...0000 要么是 0000...10000
* 转化为十进制也就是 0和16 重度hash碰撞
*
* 例子2: 1010....1000100111 & 000000...0000010010 他的结果是 00000 和 10000 和 000010 和10010
* 所以 细致去发现,只要(length-1)的结果低位出现0,那么必定会有空的下表没数据,bucket为空
* 只要(length-1)为单数 即length为2的幂次方 其结果低位都是1 即不会出现空桶。
*
* 问题3 答:
* 例如上述:1010....1000100111 & 000000...0000010000
* 1010....1000100111高位 为1010 000000...0000010000 高位为 00000
* 那么结果都是0,这样的话 高位参与计算不具有意义,所以要在 h计算hash值得时候就处理高位计算
* 这样的结果hash碰撞几率更小,下标更能均等分布。
*
*
*/
return h & (length-1);
}
6.HashMap是一种什么样的结构?
7.如果HashMap超过了最大临界值会如何处理?
/**
* Rehashes the contents of this map into a new array with a
* larger capacity. This method is called automatically when the
* number of keys in this map reaches its threshold.
* Rehashes的内容是重新创建一个新的更大初始容量的数组。
* 当键的数量超过了map的阈值这个方法自动调用
*
* If current capacity is MAXIMUM_CAPACITY, this method does not
* resize the map, but sets threshold to Integer.MAX_VALUE.
* This has the effect of preventing future calls.
* 若当前的容量已经是最大的了,这个方法不会改变map的大小,但是会把阈值设置到最大,这是将来最有价值的预防
*
* @param newCapacity the new capacity, MUST be a power of two;
* must be greater than current capacity unless current
* capacity is MAXIMUM_CAPACITY (in which case value
* is irrelevant).
*/
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length; //表的大小
if (oldCapacity == MAXIMUM_CAPACITY) { //若当前的容量已经是最大的了,这个方法不会改变map的大小,
threshold = Integer.MAX_VALUE; //但是会把阈值设置到最大,这是将来最有价值的预防
return;
}
Entry[] newTable = new Entry[newCapacity]; //新的容量table
transfer(newTable, initHashSeedAsNeeded(newCapacity)); //扩容操作
table = newTable; //使用新table
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1); //新的阈值 超过扩容
}8.HashMap在扩容的时候会出现什么样的问题?
/**
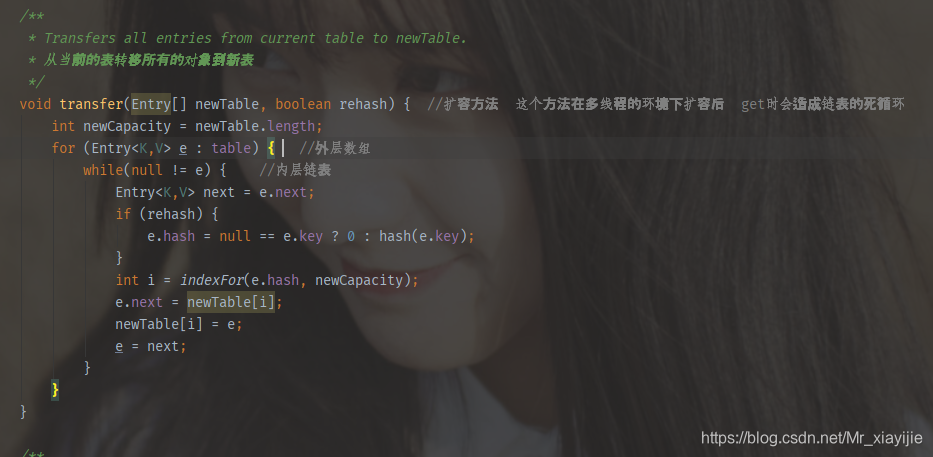
* Transfers all entries from current table to newTable.
* 从当前的表转移所有的对象到新表
*/
void transfer(Entry[] newTable, boolean rehash) { //扩容方法 这个方法在多线程的环境下扩容后 get时会造成链表的死循环
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}9.HashMap在多线程扩容后get时会造成链表的死循环问题流程

上图是线程一扩容的过程========
当线程2开始执行扩容时,e依旧是指向1,next指向2,即在线程1的结果上再进行扩容:

形成循环链表的结果就是在get的时候如果在HashMap找不到对应的keys,那么就会产生死循环,应为get会遍历链表查询值
10.HashMap get的时间复杂度从O(0)->O(n)?
在上面分析的时候,在put的时候,如果碰到key的hash值一致但是key不想等的话,就会生成链表,那么如果遭到Dos攻击的话链表长度会无限变长,那么在get的时候复杂度也就从O(0)->O(n)演变














 191
191











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









