









一、问题情况:
- 今天早上收到报警,HDFS namenode 服务异常,发生了自动故障迁移。

二、报错内容:
2021-10-26 07:13:56,310 INFO org.apache.hadoop.hdfs.server.namenode.FileJournalManager: Fina lizing edits file /home/hadoop/dfs/nn/current/edits_inprogress_0000000000824809456 -> /home/ hadoop/dfs/nn/current/edits_0000000000824809456-0000000000824809550
2021-10-26 07:13:56,310 INFO org.apache.hadoop.hdfs.server.namenode.FSEditLog: Starting log segment at 824809551
2021-10-26 07:16:30,946 INFO org.apache.hadoop.hdfs.server.blockmanagement.CacheReplicationM onitor: Rescanning after 162713 milliseconds
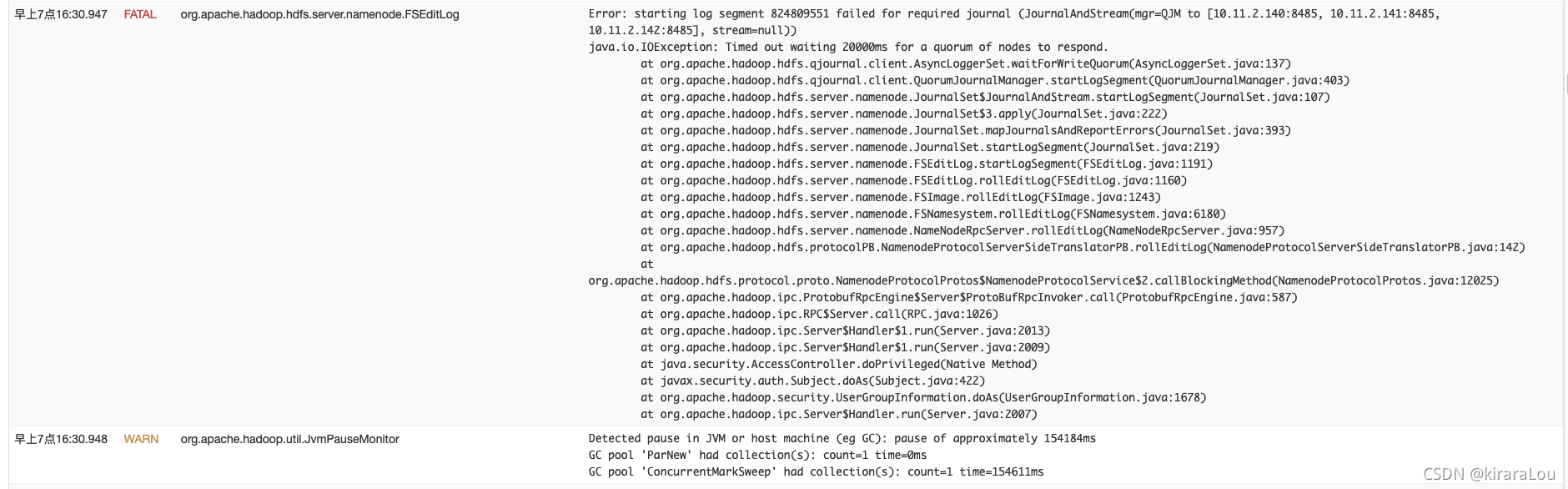
2021-10-26 07:16:30,947 WARN org.apache.hadoop.hdfs.qjournal.client.QuorumJournalManager: Wa ited 154637 ms (timeout=20000 ms) for a response for startLogSegment(824809551). No response s yet.
2021-10-26 07:16:30,947 FATAL org.apache.hadoop.hdfs.server.namenode.FSEditLog: Error: start ing log segment 824809551 failed for required journal (JournalAndStream(mgr=QJM to [10.11.2. 140:8485, 10.11.2.141:8485, 10.11.2.142:8485], stream=null))
java.io.IOException: Timed out waiting 20000ms for a quorum of nodes to respond.
at org.apache.hadoop.hdfs.qjournal.client.AsyncLoggerSet.waitForWriteQuorum(AsyncLoggerS et.java:137)
at org.apache.hadoop.hdfs.qjournal.client.QuorumJournalManager.startLogSegment(QuorumJou rnalManager.java:403)
at org.apache.hadoop.hdfs.server.namenode.JournalSet$JournalAndStream.startLogSegment(Jo urnalSet.java:107)
at org.apache.hadoop.hdfs.server.namenode.JournalSet$3.apply(JournalSet.java:222)
三、问题原因:
仔细查看nn的日志,和对源码的分析,发现是由于 namenode这个时间点进行了多次长时间的 full gc (持续1分钟以上 ),导致写 journalnode 超时(默认是20s), namenode进程退出。同时从jn的日志可以看出,后面是没有nn的请求过来的(因为nn已经挂掉了)。
-
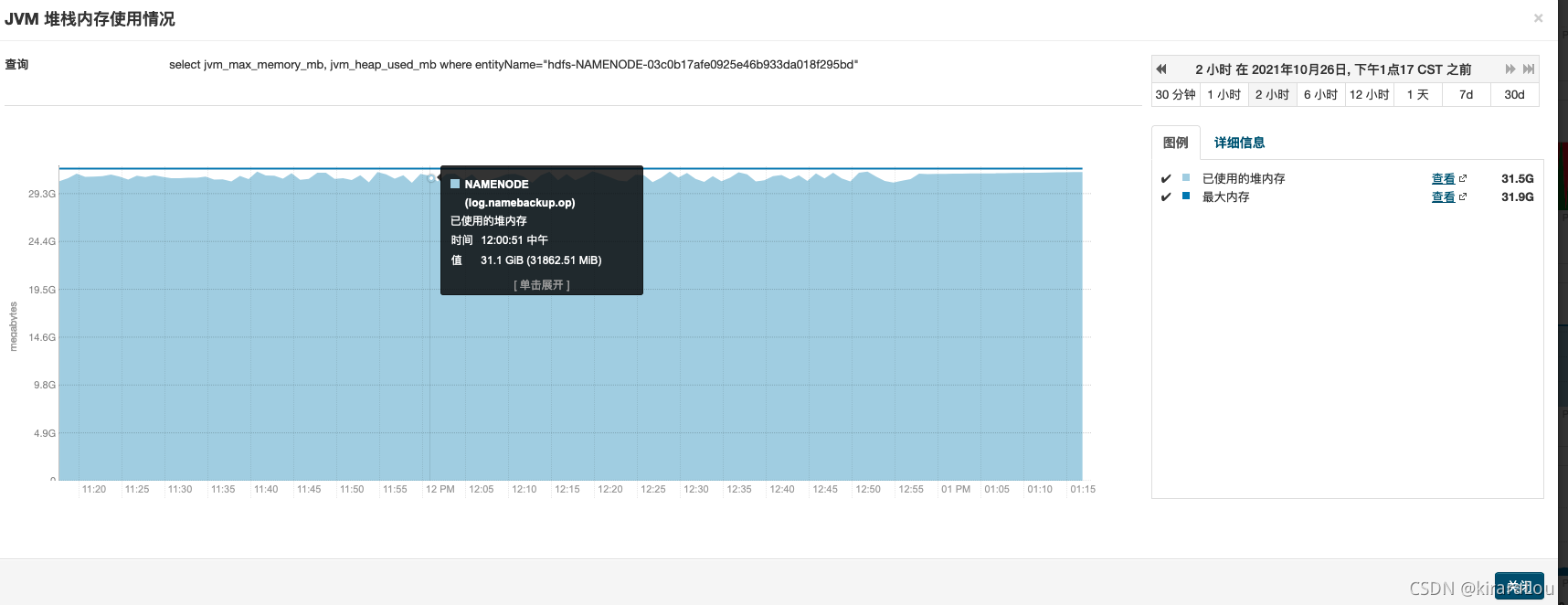
查看下namenode 的堆内存使用情况。目前JVM 配置了32G,已几乎没有剩余。
-
查看下namenode 的gc 情况。

可以看到Full gc 时间基本在1分钟以上,甚至有些数据都无法被正确采集到,而恢复正常的namenode 基本gc 时间是很短的。
那么为什么会导致多次长时间的full gc呢。主要是namenode 堆内存几乎被耗尽。导致一直在做长时间的GC,使得写入journalNode 超时,引发了自动的故障转移。
四、解决方案:
通过这次问题排查,也梳理下集群,发现有些不合理的地方,一并处理了:
- 增加zookeeper 连接数 60 -> 300
- 增加namenode jvm大小 32G -> 40G
- 增加journalNode jvm大小 256M -> 4G
- 增加journalNode 写入数据超时时间为60s
- 降低datanode jvm大小 16 -> 8G















 1782
1782











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









