







前言
众所周知,CDH为了推自家的Impala,阉割掉了Spark的spark-sql工具,虽然很多时候我们并不需要spark-sql,但是架不住特殊情况下有使用它的时候,这个根据项目或者团队(个人)情况而异。我这边就是因为项目原因,需要使用spark-sql,因此从网上各种查资料,折腾了好几天,最终在CDH集群上集成了spark-sql,以下操作并不能保证百分百适配你的环境,但思路可供借鉴。
集成步骤
下载Apache-spark2.4.0
因为CDH6.3.2使用的Spark版本是2.4.0,为了避免使用过程中出现某些版本不匹配的隐患,因此需要从官网下载spark2.4.0,下载地址:
https://archive.apache.org/dist/spark/spark-2.4.0/

将下载好的压缩包解压到CDH集群服务器的合适目录下
此处我将其放到/opt/cloudera/parcels/CDH/lib/下并起名为spark2
tar -zxvf spark-2.4.0-bin-hadoop2.7.tgz
mv spark-2.4.0-bin-hadoop2.7 /opt/cloudera/parcels/CDH/lib/spark2
修改配置文件
将spark2/conf下的所有配置全部删除,并将集群spark的conf文件复制到此处
cd /opt/cloudera/parcels/CDH/lib/spark2/conf
rm -rf *
cp -r /etc/spark/conf/* ./
mv spark-env.sh spark-env
说明:
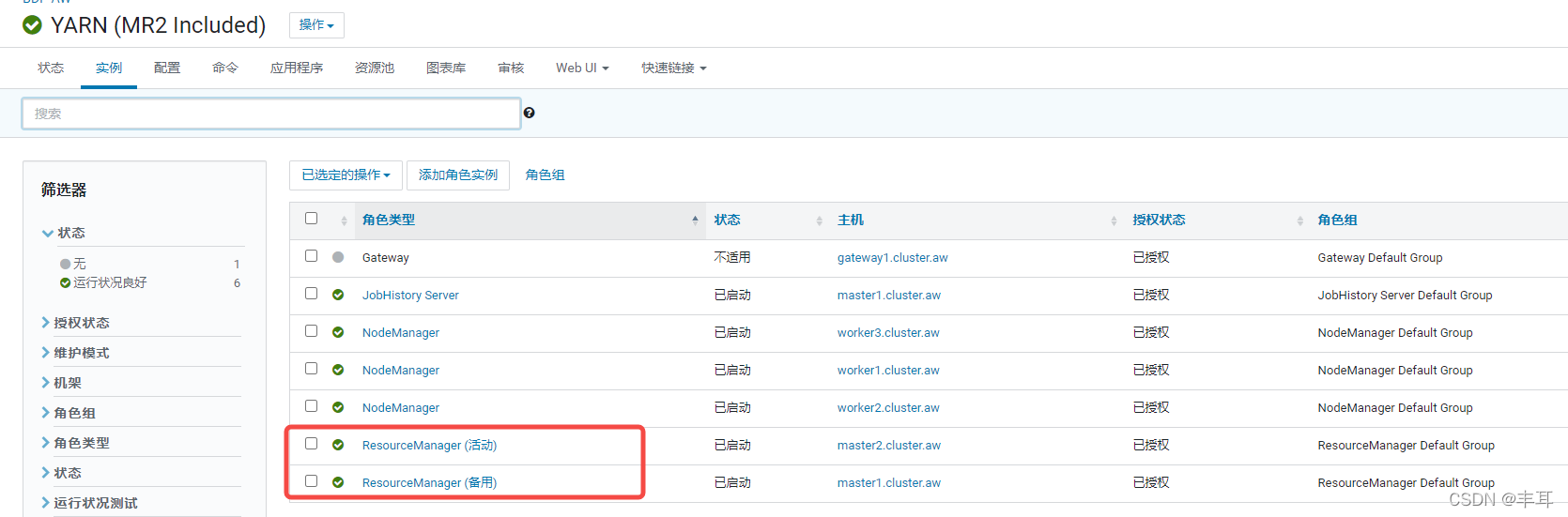
- spark/conf我是取自ResourceManager节点的,一开始我是在gateway节点上安装spark-sql,conf文件也是直接复制的gateway节点,但是最后死活无法正常链接yarn,后来在ResourceManager(master)节点执行同样的配置,却能正常使用spark-sql,所以应该是gateway节点上的配置有不通的地方,具体原因不明,请大神赐教。
scp -r root@master1:/etc/etc/spark/conf/* ./
- 将spark-env.sh改名是为了不让spark-sql走spark环境,而是走hive源数据库。
添加hive-site.xml
将gateway节点的hive-site.xml复制到spark2/conf目录下,不需要做变动
cp /etc/hive/conf/hive-site.xml /opt/cloudera/parcels/CDH/lib/spark2/conf/
配置yarn.resourcemanager
查看你CDH的yarn配置里是否有如下配置,需要开启
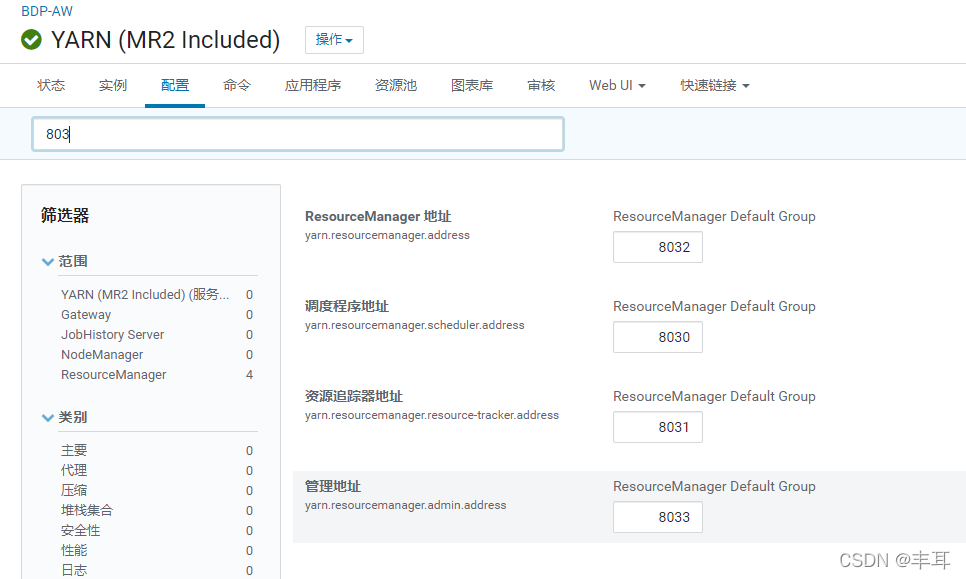
正常情况下,resourcemanager应该会默认启用以上配置的
创建spark-sql
cat /opt/cloudera/parcels/CDH/bin/spark-sql
#!/bin/bash
# Reference: http://stackoverflow.com/questions/59895/can-a-bash-script-tell-what-directory-its-stored-in
export HADOOP_CONF_DIR=/etc/hadoop/conf
export YARN_CONF_DIR=/etc/hadoop/conf
SOURCE="${BASH_SOURCE[0]}"
BIN_DIR="$( dirname "$SOURCE" )"
while [ -h "$SOURCE" ]
do
SOURCE="$(readlink "$SOURCE")"
[[ $SOURCE != /* ]] && SOURCE="$BIN_DIR/$SOURCE"
BIN_DIR="$( cd -P "$( dirname "$SOURCE" )" && pwd )"
done
BIN_DIR="$( cd -P "$( dirname "$SOURCE" )" && pwd )"
LIB_DIR=$BIN_DIR/../lib
export HADOOP_HOME=$LIB_DIR/hadoop
# Autodetect JAVA_HOME if not defined
. $LIB_DIR/bigtop-utils/bigtop-detect-javahome
exec $LIB_DIR/spark2/bin/spark-submit --class org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver "$@"
配置快捷方式
alternatives --install /usr/bin/spark-sql spark-sql /opt/cloudera/parcels/CDH/bin/spark-sql 1
说明
本篇内容主要参考以下文章,并根据自己集群的情况进行了相应修改
http://blog.51yip.com/hadoop/2286.html/comment-page-1
介于网友们参照我的文章依然无法使用spark-sql的问题,这里做一下说明:
因为每个人搭建的集群及安装的组件不一定一样,这里我把我集群的相关信息发出来,供大家参考
集群情况:
附安装部署过程,上传与解压过程略,解压后的完整操作:
[root@gateway1 pkg]# ll /opt/cloudera/parcels/CDH/lib/spark2
ls: cannot access /opt/cloudera/parcels/CDH/lib/spark2: No such file or directory
[root@gateway1 pkg]# mv spark-2.4.0-bin-hadoop2.7 /opt/cloudera/parcels/CDH/lib/spark2
[root@gateway1 pkg]# cd cd /opt/cloudera/parcels/CDH/lib/spark2/conf^C
[root@gateway1 pkg]# cd /opt/cloudera/parcels/CDH/lib/spark2/conf
[root@gateway1 conf]# ll
total 36
-rw-r--r-- 1 aw-bdp-collect bdp 996 Oct 29 2018 docker.properties.template
-rw-r--r-- 1 aw-bdp-collect bdp 1105 Oct 29 2018 fairscheduler.xml.template
-rw-r--r-- 1 aw-bdp-collect bdp 2025 Oct 29 2018 log4j.properties.template
-rw-r--r-- 1 aw-bdp-collect bdp 7801 Oct 29 2018 metrics.properties.template
-rw-r--r-- 1 aw-bdp-collect bdp 865 Oct 29 2018 slaves.template
-rw-r--r-- 1 aw-bdp-collect bdp 1292 Oct 29 2018 spark-defaults.conf.template
-rwxr-xr-x 1 aw-bdp-collect bdp 4221 Oct 29 2018 spark-env.sh.template
[root@gateway1 conf]# rm -rf *
[root@gateway1 conf]# pwd
/opt/cloudera/parcels/CDH/lib/spark2/conf
[root@gateway1 conf]# scp -r root@master1:/etc/etc/spark/conf/* ./
The authenticity of host 'master1 (192.168.0.11)' can't be established.
ECDSA key fingerprint is SHA256:+D1XEzAjCwxLbmLy9ezk9Dc7cKnjorDXBghFZpLp/fE.
ECDSA key fingerprint is MD5:b2:9f:c7:f0:a5:ba:03:02:42:61:50:14:db:b2:07:03.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'master1,192.168.0.11' (ECDSA) to the list of known hosts.
root@master1's password:
scp: /etc/etc/spark/conf/*: No such file or directory
[root@gateway1 conf]# scp -r root@master1:/etc/spark/conf/* ./
root@master1’s password:
docker.properties.template 100% 996 1.5MB/s 00:00
fairscheduler.xml.template 100% 1105 2.2MB/s 00:00
log4j.properties.template 100% 2025 4.0MB/s 00:00
metrics.properties.template 100% 7801 11.2MB/s 00:00
slaves.template 100% 865 2.0MB/s 00:00
spark-defaults.conf 100% 1292 2.6MB/s 00:00
spark-defaults.conf.template 100% 1292 3.0MB/s 00:00
spark-env.sh 100% 5556 9.7MB/s 00:00
spark-env.sh.template 100% 4221 8.0MB/s 00:00
[root@gateway1 conf]# ll
total 48
-rw-r--r-- 1 root root 996 Aug 12 09:12 docker.properties.template
-rw-r--r-- 1 root root 1105 Aug 12 09:12 fairscheduler.xml.template
-rw-r--r-- 1 root root 2025 Aug 12 09:12 log4j.properties.template
-rw-r--r-- 1 root root 7801 Aug 12 09:12 metrics.properties.template
-rw-r--r-- 1 root root 865 Aug 12 09:12 slaves.template
-rw-r--r-- 1 root root 1292 Aug 12 09:12 spark-defaults.conf
-rw-r--r-- 1 root root 1292 Aug 12 09:12 spark-defaults.conf.template
-rwxr-xr-x 1 root root 5556 Aug 12 09:12 spark-env.sh
-rwxr-xr-x 1 root root 4221 Aug 12 09:12 spark-env.sh.template
[root@gateway1 conf]# mv spark-env.sh spark-env
[root@gateway1 conf]# ll
total 48
-rw-r--r-- 1 root root 996 Aug 12 09:12 docker.properties.template
-rw-r--r-- 1 root root 1105 Aug 12 09:12 fairscheduler.xml.template
-rw-r--r-- 1 root root 2025 Aug 12 09:12 log4j.properties.template
-rw-r--r-- 1 root root 7801 Aug 12 09:12 metrics.properties.template
-rw-r--r-- 1 root root 865 Aug 12 09:12 slaves.template
-rw-r--r-- 1 root root 1292 Aug 12 09:12 spark-defaults.conf
-rw-r--r-- 1 root root 1292 Aug 12 09:12 spark-defaults.conf.template
-rwxr-xr-x 1 root root 5556 Aug 12 09:12 spark-env
-rwxr-xr-x 1 root root 4221 Aug 12 09:12 spark-env.sh.template
[root@gateway1 conf]# cp /etc/hive/conf/hive-site.xml /opt/cloudera/parcels/CDH/lib/spark2/conf/
[root@gateway1 conf]# ll
total 56
-rw-r--r-- 1 root root 996 Aug 12 09:12 docker.properties.template
-rw-r--r-- 1 root root 1105 Aug 12 09:12 fairscheduler.xml.template
-rw-r--r-- 1 root root 6792 Aug 12 09:12 hive-site.xml
-rw-r--r-- 1 root root 2025 Aug 12 09:12 log4j.properties.template
-rw-r--r-- 1 root root 7801 Aug 12 09:12 metrics.properties.template
-rw-r--r-- 1 root root 865 Aug 12 09:12 slaves.template
-rw-r--r-- 1 root root 1292 Aug 12 09:12 spark-defaults.conf
-rw-r--r-- 1 root root 1292 Aug 12 09:12 spark-defaults.conf.template
-rwxr-xr-x 1 root root 5556 Aug 12 09:12 spark-env
-rwxr-xr-x 1 root root 4221 Aug 12 09:12 spark-env.sh.template
[root@gateway1 conf]# cd /opt/cloudera/parcels/CDH/bin/
[root@gateway1 bin]# ll
total 308
-rwxr-xr-x 1 root root 594 Nov 9 2019 avro-tools
-rwxr-xr-x 1 root root 771 Nov 9 2019 beeline
lrwxrwxrwx 1 root root 42 Nov 9 2019 bigtop-detect-javahome -> ../lib/bigtop-utils/bigtop-detect-javahome
-rwxr-xr-x 1 root root 2536 Nov 9 2019 catalogd
-rwxr-xr-x 1 root root 600 Nov 9 2019 cli_mt
-rwxr-xr-x 1 root root 600 Nov 9 2019 cli_st
-rwxr-xr-x 1 root root 642 Nov 9 2019 flume-ng
-rwxr-xr-x 1 root root 626 Nov 9 2019 hadoop
-rwxr-xr-x 1 root root 1361 Nov 9 2019 hadoop-fuse-dfs
-rwxr-xr-x 1 root root 1055 Nov 9 2019 hbase
-rwxr-xr-x 1 root root 583 Nov 9 2019 hbase-indexer
-rwxr-xr-x 1 root root 595 Nov 9 2019 hbase-indexer-sentry
-rwxr-xr-x 1 root root 950 Nov 9 2019 hcat
-rwxr-xr-x 1 root root 690 Nov 9 2019 hdfs
-rwxr-xr-x 1 root root 768 Nov 9 2019 hive
-rwxr-xr-x 1 root root 775 Nov 9 2019 hiveserver2
-rwxr-xr-x 1 root root 539 Nov 9 2019 impala-collect-diagnostics
-rwxr-xr-x 1 root root 537 Nov 9 2019 impala-collect-minidumps
-rwxr-xr-x 1 root root 2535 Nov 9 2019 impalad
-rwxr-xr-x 1 root root 2582 Nov 9 2019 impala-shell
-rwxr-xr-x 1 root root 645 Nov 9 2019 kafka-acls
-rwxr-xr-x 1 root root 660 Nov 9 2019 kafka-broker-api-versions
-rwxr-xr-x 1 root root 648 Nov 9 2019 kafka-configs
-rwxr-xr-x 1 root root 657 Nov 9 2019 kafka-console-consumer
-rwxr-xr-x 1 root root 657 Nov 9 2019 kafka-console-producer
-rwxr-xr-x 1 root root 656 Nov 9 2019 kafka-consumer-groups
-rwxr-xr-x 1 root root 659 Nov 9 2019 kafka-consumer-perf-test
-rwxr-xr-x 1 root root 658 Nov 9 2019 kafka-delegation-tokens
-rwxr-xr-x 1 root root 655 Nov 9 2019 kafka-delete-records
-rwxr-xr-x 1 root root 649 Nov 9 2019 kafka-dump-log
-rwxr-xr-x 1 root root 649 Nov 9 2019 kafka-log-dirs
-rwxr-xr-x 1 root root 653 Nov 9 2019 kafka-mirror-maker
-rwxr-xr-x 1 root root 667 Nov 9 2019 kafka-preferred-replica-election
-rwxr-xr-x 1 root root 659 Nov 9 2019 kafka-producer-perf-test
-rwxr-xr-x 1 root root 660 Nov 9 2019 kafka-reassign-partitions
-rwxr-xr-x 1 root root 661 Nov 9 2019 kafka-replica-verification
-rwxr-xr-x 1 root root 650 Nov 9 2019 kafka-run-class
-rwxr-xr-x 1 root root 647 Nov 9 2019 kafka-sentry
-rwxr-xr-x 1 root root 653 Nov 9 2019 kafka-server-start
-rwxr-xr-x 1 root root 652 Nov 9 2019 kafka-server-stop
-rwxr-xr-x 1 root root 666 Nov 9 2019 kafka-streams-application-reset
-rwxr-xr-x 1 root root 647 Nov 9 2019 kafka-topics
-rwxr-xr-x 1 root root 660 Nov 9 2019 kafka-verifiable-consumer
-rwxr-xr-x 1 root root 660 Nov 9 2019 kafka-verifiable-producer
-rwxr-xr-x 1 root root 576 Nov 9 2019 kite-dataset
-rwxr-xr-x 1 root root 527 Nov 9 2019 kudu
-rwxr-xr-x 1 root root 602 Nov 9 2019 load_gen
-rwxr-xr-x 1 root root 702 Nov 9 2019 mapred
-rwxr-xr-x 1 root root 1353 Nov 9 2019 oozie
-rwxr-xr-x 1 root root 1525 Nov 9 2019 oozie-setup
-rwxr-xr-x 1 root root 580 Nov 9 2019 parquet-tools
-rwxr-xr-x 1 root root 1646 Nov 9 2019 pig
-rwxr-xr-x 1 root root 607 Nov 9 2019 pyspark
-rwxr-xr-x 1 root root 674 Nov 9 2019 sentry
-rwxr-xr-x 1 root root 694 Nov 9 2019 solrctl
-rwxr-xr-x 1 root root 611 Nov 9 2019 spark-shell
-rwxr-xr-x 1 root root 612 Nov 9 2019 spark-submit
-rwxr-xr-x 1 root root 922 Nov 9 2019 sqoop
-rwxr-xr-x 1 root root 930 Nov 9 2019 sqoop-codegen
-rwxr-xr-x 1 root root 940 Nov 9 2019 sqoop-create-hive-table
-rwxr-xr-x 1 root root 927 Nov 9 2019 sqoop-eval
-rwxr-xr-x 1 root root 929 Nov 9 2019 sqoop-export
-rwxr-xr-x 1 root root 927 Nov 9 2019 sqoop-help
-rwxr-xr-x 1 root root 929 Nov 9 2019 sqoop-import
-rwxr-xr-x 1 root root 940 Nov 9 2019 sqoop-import-all-tables
-rwxr-xr-x 1 root root 926 Nov 9 2019 sqoop-job
-rwxr-xr-x 1 root root 937 Nov 9 2019 sqoop-list-databases
-rwxr-xr-x 1 root root 934 Nov 9 2019 sqoop-list-tables
-rwxr-xr-x 1 root root 928 Nov 9 2019 sqoop-merge
-rwxr-xr-x 1 root root 932 Nov 9 2019 sqoop-metastore
-rwxr-xr-x 1 root root 930 Nov 9 2019 sqoop-version
-rwxr-xr-x 1 root root 2539 Nov 9 2019 statestored
-rwxr-xr-x 1 root root 743 Nov 9 2019 yarn
-rwxr-xr-x 1 root root 849 Nov 9 2019 zookeeper-client
-rwxr-xr-x 1 root root 663 Nov 9 2019 zookeeper-security-migration
-rwxr-xr-x 1 root root 1175 Nov 9 2019 zookeeper-server
-rwxr-xr-x 1 root root 1176 Nov 9 2019 zookeeper-server-cleanup
-rwxr-xr-x 1 root root 1186 Nov 9 2019 zookeeper-server-initialize
[root@gateway1 bin]# vim spark-sql
[root@gateway1 bin]# chmod + x spark-sql
chmod: cannot access ‘x’: No such file or directory
[root@gateway1 bin]# chmod +x spark-sql
[root@gateway1 bin]# ./spark-sql
2022-08-12 09:14:57 WARN HiveConf:2753 - HiveConf of name hive.vectorized.use.checked.expressions does not exist
2022-08-12 09:14:57 WARN HiveConf:2753 - HiveConf of name hive.strict.checks.no.partition.filter does not exist
2022-08-12 09:14:57 WARN HiveConf:2753 - HiveConf of name hive.vectorized.use.vector.serde.deserialize does not exist
2022-08-12 09:14:57 WARN HiveConf:2753 - HiveConf of name hive.strict.checks.orderby.no.limit does not exist
2022-08-12 09:14:57 WARN HiveConf:2753 - HiveConf of name hive.vectorized.adaptor.usage.mode does not exist
2022-08-12 09:14:57 WARN HiveConf:2753 - HiveConf of name hive.vectorized.use.vectorized.input.format does not exist
2022-08-12 09:14:57 WARN HiveConf:2753 - HiveConf of name hive.vectorized.input.format.excludes does not exist
2022-08-12 09:14:57 WARN HiveConf:2753 - HiveConf of name hive.strict.checks.bucketing does not exist
2022-08-12 09:14:57 WARN HiveConf:2753 - HiveConf of name hive.strict.checks.type.safety does not exist
2022-08-12 09:14:57 WARN HiveConf:2753 - HiveConf of name hive.strict.checks.cartesian.product does not exist
2022-08-12 09:14:57 INFO metastore:376 - Trying to connect to metastore with URI thrift://utility1.cdh6.aw:9083
2022-08-12 09:14:57 INFO metastore:472 - Connected to metastore.
2022-08-12 09:14:58 WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2022-08-12 09:14:59 INFO SessionState:641 - Created HDFS directory: /tmp/hive/root
2022-08-12 09:14:59 INFO SessionState:641 - Created local directory: /tmp/root
2022-08-12 09:14:59 INFO SessionState:641 - Created local directory: /tmp/2da6581d-f664-4dad-ba0d-70d0d8ed02d3_resources
2022-08-12 09:14:59 INFO SessionState:641 - Created HDFS directory: /tmp/hive/root/2da6581d-f664-4dad-ba0d-70d0d8ed02d3
2022-08-12 09:14:59 INFO SessionState:641 - Created local directory: /tmp/root/2da6581d-f664-4dad-ba0d-70d0d8ed02d3
2022-08-12 09:14:59 INFO SessionState:641 - Created HDFS directory: /tmp/hive/root/2da6581d-f664-4dad-ba0d-70d0d8ed02d3/_tmp_space.db
2022-08-12 09:14:59 INFO SparkContext:54 - Running Spark version 2.4.0
2022-08-12 09:14:59 INFO SparkContext:54 - Submitted application: SparkSQL::192.168.0.13
2022-08-12 09:14:59 INFO SecurityManager:54 - Changing view acls to: root
2022-08-12 09:14:59 INFO SecurityManager:54 - Changing modify acls to: root
2022-08-12 09:14:59 INFO SecurityManager:54 - Changing view acls groups to:
2022-08-12 09:14:59 INFO SecurityManager:54 - Changing modify acls groups to:
2022-08-12 09:14:59 INFO SecurityManager:54 - SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); groups with view permissions: Set(); users with modify permissions: Set(root); groups with modify permissions: Set()
2022-08-12 09:14:59 INFO Utils:54 - Successfully started service 'sparkDriver' on port 46813.
2022-08-12 09:14:59 INFO SparkEnv:54 - Registering MapOutputTracker
2022-08-12 09:14:59 INFO SparkEnv:54 - Registering BlockManagerMaster
2022-08-12 09:14:59 INFO BlockManagerMasterEndpoint:54 - Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
2022-08-12 09:14:59 INFO BlockManagerMasterEndpoint:54 - BlockManagerMasterEndpoint up
2022-08-12 09:14:59 INFO DiskBlockManager:54 - Created local directory at /tmp/blockmgr-3356a81b-b797-40d6-9d1f-a9d816f1de54
2022-08-12 09:14:59 INFO MemoryStore:54 - MemoryStore started with capacity 366.3 MB
2022-08-12 09:14:59 INFO SparkEnv:54 - Registering OutputCommitCoordinator
2022-08-12 09:14:59 INFO log:192 - Logging initialized @3892ms
2022-08-12 09:14:59 INFO Server:351 - jetty-9.3.z-SNAPSHOT, build timestamp: unknown, git hash: unknown
2022-08-12 09:14:59 INFO Server:419 - Started @3974ms
2022-08-12 09:14:59 INFO AbstractConnector:278 - Started ServerConnector@6944e53e{HTTP/1.1,[http/1.1]}{0.0.0.0:4040}
2022-08-12 09:14:59 INFO Utils:54 - Successfully started service 'SparkUI' on port 4040.
2022-08-12 09:14:59 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@587a1cfb{/jobs,null,AVAILABLE,@Spark}
2022-08-12 09:14:59 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@508a65bf{/jobs/json,null,AVAILABLE,@Spark}
2022-08-12 09:14:59 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@17f2dd85{/jobs/job,null,AVAILABLE,@Spark}
2022-08-12 09:14:59 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@210308d5{/jobs/job/json,null,AVAILABLE,@Spark}
2022-08-12 09:14:59 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@22a736d7{/stages,null,AVAILABLE,@Spark}
2022-08-12 09:14:59 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@23b8d9f3{/stages/json,null,AVAILABLE,@Spark}
2022-08-12 09:14:59 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@7f353d99{/stages/stage,null,AVAILABLE,@Spark}
2022-08-12 09:14:59 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@38d17d80{/stages/stage/json,null,AVAILABLE,@Spark}
2022-08-12 09:14:59 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@6ede46f6{/stages/pool,null,AVAILABLE,@Spark}
2022-08-12 09:14:59 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@66273da0{/stages/pool/json,null,AVAILABLE,@Spark}
2022-08-12 09:14:59 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@2127e66e{/storage,null,AVAILABLE,@Spark}
2022-08-12 09:14:59 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@1229a2b7{/storage/json,null,AVAILABLE,@Spark}
2022-08-12 09:14:59 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@e5cbff2{/storage/rdd,null,AVAILABLE,@Spark}
2022-08-12 09:14:59 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@51c959a4{/storage/rdd/json,null,AVAILABLE,@Spark}
2022-08-12 09:14:59 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@4fc3c165{/environment,null,AVAILABLE,@Spark}
2022-08-12 09:14:59 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@10a0fe30{/environment/json,null,AVAILABLE,@Spark}
2022-08-12 09:14:59 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@7b6860f9{/executors,null,AVAILABLE,@Spark}
2022-08-12 09:14:59 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@60f70249{/executors/json,null,AVAILABLE,@Spark}
2022-08-12 09:14:59 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@31ee2fdb{/executors/threadDump,null,AVAILABLE,@Spark}
2022-08-12 09:14:59 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@262816a8{/executors/threadDump/json,null,AVAILABLE,@Spark}
2022-08-12 09:14:59 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@1effd53c{/static,null,AVAILABLE,@Spark}
2022-08-12 09:14:59 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@3968bc60{/,null,AVAILABLE,@Spark}
2022-08-12 09:14:59 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@26f46fa6{/api,null,AVAILABLE,@Spark}
2022-08-12 09:14:59 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@70228253{/jobs/job/kill,null,AVAILABLE,@Spark}
2022-08-12 09:14:59 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@63c12e52{/stages/stage/kill,null,AVAILABLE,@Spark}
2022-08-12 09:14:59 INFO SparkUI:54 - Bound SparkUI to 0.0.0.0, and started at http://gateway1.cdh6.aw:4040
2022-08-12 09:14:59 INFO Executor:54 - Starting executor ID driver on host localhost
2022-08-12 09:14:59 INFO Utils:54 - Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 44931.
2022-08-12 09:14:59 INFO NettyBlockTransferService:54 - Server created on gateway1.cdh6.aw:44931
2022-08-12 09:14:59 INFO BlockManager:54 - Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
2022-08-12 09:14:59 INFO BlockManagerMaster:54 - Registering BlockManager BlockManagerId(driver, gateway1.cdh6.aw, 44931, None)
2022-08-12 09:14:59 INFO BlockManagerMasterEndpoint:54 - Registering block manager gateway1.cdh6.aw:44931 with 366.3 MB RAM, BlockManagerId(driver, gateway1.cdh6.aw, 44931, None)
2022-08-12 09:14:59 INFO BlockManagerMaster:54 - Registered BlockManager BlockManagerId(driver, gateway1.cdh6.aw, 44931, None)
2022-08-12 09:14:59 INFO BlockManager:54 - Initialized BlockManager: BlockManagerId(driver, gateway1.cdh6.aw, 44931, None)
2022-08-12 09:15:00 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@4b31a708{/metrics/json,null,AVAILABLE,@Spark}
2022-08-12 09:15:00 INFO SharedState:54 - loading hive config file: file:/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/spark2/conf/hive-site.xml
2022-08-12 09:15:00 INFO SharedState:54 - spark.sql.warehouse.dir is not set, but hive.metastore.warehouse.dir is set. Setting spark.sql.warehouse.dir to the value of hive.metastore.warehouse.dir ('/user/hive/warehouse').
2022-08-12 09:15:00 INFO SharedState:54 - Warehouse path is '/user/hive/warehouse'.
2022-08-12 09:15:00 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@49d30c6f{/SQL,null,AVAILABLE,@Spark}
2022-08-12 09:15:00 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@1115433e{/SQL/json,null,AVAILABLE,@Spark}
2022-08-12 09:15:00 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@3bed3315{/SQL/execution,null,AVAILABLE,@Spark}
2022-08-12 09:15:00 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@119b0892{/SQL/execution/json,null,AVAILABLE,@Spark}
2022-08-12 09:15:00 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@3bc4ef12{/static/sql,null,AVAILABLE,@Spark}
2022-08-12 09:15:00 INFO HiveUtils:54 - Initializing HiveMetastoreConnection version 1.2.1 using Spark classes.
2022-08-12 09:15:00 INFO HiveClientImpl:54 - Warehouse location for Hive client (version 1.2.2) is /user/hive/warehouse
2022-08-12 09:15:00 INFO StateStoreCoordinatorRef:54 - Registered StateStoreCoordinator endpoint
Spark master: local[*], Application Id: local-1660266899850
2022-08-12 09:15:01 INFO SparkSQLCLIDriver:951 - Spark master: local[*], Application Id: local-1660266899850
spark-sql> show databases;
2022-08-12 09:15:28 INFO CodeGenerator:54 - Code generated in 173.089909 ms
app
default
dmt
dwh
src
tmp
Time taken: 1.872 seconds, Fetched 6 row(s)
2022-08-12 09:15:28 INFO SparkSQLCLIDriver:951 - Time taken: 1.872 seconds, Fetched 6 row(s)
spark-sql>
安装后可能遇到的问题
1. 执行spark-sql没问题,但是执行spark-sql --master yarn --deploy-mode client的时候报错如下:
2022-08-12 09:48:48 INFO RMProxy:98 - Connecting to ResourceManager at /0.0.0.0:8032
2022-08-12 09:48:49 INFO Client:871 - Retrying connect to server: 0.0.0.0/0.0.0.0:8032. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
2022-08-12 09:48:50 INFO Client:871 - Retrying connect to server: 0.0.0.0/0.0.0.0:8032. Already tried 1 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
2022-08-12 09:48:51 INFO Client:871 - Retrying connect to server: 0.0.0.0/0.0.0.0:8032. Already tried 2 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
2022-08-12 09:48:52 INFO Client:871 - Retrying connect to server: 0.0.0.0/0.0.0.0:8032. Already tried 3 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
2022-08-12 09:48:53 INFO Client:871 - Retrying connect to server: 0.0.0.0/0.0.0.0:8032. Already tried 4 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
2022-08-12 09:48:54 INFO Client:871 - Retrying connect to server: 0.0.0.0/0.0.0.0:8032. Already tried 5 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
2022-08-12 09:48:55 INFO Client:871 - Retrying connect to server: 0.0.0.0/0.0.0.0:8032. Already tried 6 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
主要原因是当前机器上找不到ResourceManager的相关信息。这时你可以先检查一下/etc/hadoop/conf/目录,应该缺少yarn-site.xml文件,直接从相关服务器上复制一份过来即可。
当然,按照CDH的特性,一旦配置更新,所有配置都重置了,所以为了用CDH管理集群,最好的办法就是在这台机器上安装上yarn的gateway,一劳永逸。
2. 当你直接使用spark-sql时能正常使用,但是使用spark-sql --master yarn --deploy-mode client时报错,报错内容如下,从报错内容中我们很明显发现,root不具备操作hdfs的权限,换一个有hdfs写权限的用户执行即可,如sudo -u hive spark-sql --master yarn --deploy-mode client
2022-08-12 09:47:52 ERROR SparkContext:91 - Error initializing SparkContext.
org.apache.hadoop.security.AccessControlException: Permission denied: user=root, access=WRITE, inode="/user":hdfs:supergroup:drwxr-xr-x
完整报错如下:
[root@master1 bin]# spark-sql --master yarn --deploy-mode client
2022-08-12 09:47:49 WARN HiveConf:2753 - HiveConf of name hive.vectorized.use.checked.expressions does not exist
2022-08-12 09:47:49 WARN HiveConf:2753 - HiveConf of name hive.strict.checks.no.partition.filter does not exist
2022-08-12 09:47:49 WARN HiveConf:2753 - HiveConf of name hive.vectorized.use.vector.serde.deserialize does not exist
2022-08-12 09:47:49 WARN HiveConf:2753 - HiveConf of name hive.strict.checks.orderby.no.limit does not exist
2022-08-12 09:47:49 WARN HiveConf:2753 - HiveConf of name hive.vectorized.adaptor.usage.mode does not exist
2022-08-12 09:47:49 WARN HiveConf:2753 - HiveConf of name hive.vectorized.use.vectorized.input.format does not exist
2022-08-12 09:47:49 WARN HiveConf:2753 - HiveConf of name hive.vectorized.input.format.excludes does not exist
2022-08-12 09:47:49 WARN HiveConf:2753 - HiveConf of name hive.strict.checks.bucketing does not exist
2022-08-12 09:47:49 WARN HiveConf:2753 - HiveConf of name hive.strict.checks.type.safety does not exist
2022-08-12 09:47:49 WARN HiveConf:2753 - HiveConf of name hive.strict.checks.cartesian.product does not exist
2022-08-12 09:47:50 INFO metastore:376 - Trying to connect to metastore with URI thrift://utility1.cdh6.aw:9083
2022-08-12 09:47:50 INFO metastore:472 - Connected to metastore.
2022-08-12 09:47:51 WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2022-08-12 09:47:51 INFO SessionState:641 - Created local directory: /tmp/root
2022-08-12 09:47:51 INFO SessionState:641 - Created local directory: /tmp/6022c9c1-dc51-428a-a8b0-87193c45d846_resources
2022-08-12 09:47:51 INFO SessionState:641 - Created HDFS directory: /tmp/hive/root/6022c9c1-dc51-428a-a8b0-87193c45d846
2022-08-12 09:47:51 INFO SessionState:641 - Created local directory: /tmp/root/6022c9c1-dc51-428a-a8b0-87193c45d846
2022-08-12 09:47:51 INFO SessionState:641 - Created HDFS directory: /tmp/hive/root/6022c9c1-dc51-428a-a8b0-87193c45d846/_tmp_space.db
2022-08-12 09:47:51 INFO SparkContext:54 - Running Spark version 2.4.0
2022-08-12 09:47:51 INFO SparkContext:54 - Submitted application: SparkSQL::192.168.0.11
2022-08-12 09:47:51 INFO SecurityManager:54 - Changing view acls to: root
2022-08-12 09:47:51 INFO SecurityManager:54 - Changing modify acls to: root
2022-08-12 09:47:51 INFO SecurityManager:54 - Changing view acls groups to:
2022-08-12 09:47:51 INFO SecurityManager:54 - Changing modify acls groups to:
2022-08-12 09:47:51 INFO SecurityManager:54 - SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); groups with view permissions: Set(); users with modify permissions: Set(root); groups with modify permissions: Set()
2022-08-12 09:47:51 INFO Utils:54 - Successfully started service 'sparkDriver' on port 36099.
2022-08-12 09:47:51 INFO SparkEnv:54 - Registering MapOutputTracker
2022-08-12 09:47:51 INFO SparkEnv:54 - Registering BlockManagerMaster
2022-08-12 09:47:51 INFO BlockManagerMasterEndpoint:54 - Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
2022-08-12 09:47:51 INFO BlockManagerMasterEndpoint:54 - BlockManagerMasterEndpoint up
2022-08-12 09:47:51 INFO DiskBlockManager:54 - Created local directory at /tmp/blockmgr-d93412b1-33df-49d1-a745-ed4cd89e232e
2022-08-12 09:47:51 INFO MemoryStore:54 - MemoryStore started with capacity 366.3 MB
2022-08-12 09:47:51 INFO SparkEnv:54 - Registering OutputCommitCoordinator
2022-08-12 09:47:51 INFO log:192 - Logging initialized @3564ms
2022-08-12 09:47:51 INFO Server:351 - jetty-9.3.z-SNAPSHOT, build timestamp: unknown, git hash: unknown
2022-08-12 09:47:52 INFO Server:419 - Started @3647ms
2022-08-12 09:47:52 INFO AbstractConnector:278 - Started ServerConnector@6920614{HTTP/1.1,[http/1.1]}{0.0.0.0:4040}
2022-08-12 09:47:52 INFO Utils:54 - Successfully started service 'SparkUI' on port 4040.
2022-08-12 09:47:52 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@4c6007fb{/jobs,null,AVAILABLE,@Spark}
2022-08-12 09:47:52 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@3dffc764{/jobs/json,null,AVAILABLE,@Spark}
2022-08-12 09:47:52 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@4b6e1c0{/jobs/job,null,AVAILABLE,@Spark}
2022-08-12 09:47:52 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@654c7d2d{/jobs/job/json,null,AVAILABLE,@Spark}
2022-08-12 09:47:52 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@26cb5207{/stages,null,AVAILABLE,@Spark}
2022-08-12 09:47:52 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@15400fff{/stages/json,null,AVAILABLE,@Spark}
2022-08-12 09:47:52 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@18d910b3{/stages/stage,null,AVAILABLE,@Spark}
2022-08-12 09:47:52 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@77774571{/stages/stage/json,null,AVAILABLE,@Spark}
2022-08-12 09:47:52 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@277b8fa4{/stages/pool,null,AVAILABLE,@Spark}
2022-08-12 09:47:52 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@6cd64ee8{/stages/pool/json,null,AVAILABLE,@Spark}
2022-08-12 09:47:52 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@620c8641{/storage,null,AVAILABLE,@Spark}
2022-08-12 09:47:52 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@2f1d0bbc{/storage/json,null,AVAILABLE,@Spark}
2022-08-12 09:47:52 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@5460b754{/storage/rdd,null,AVAILABLE,@Spark}
2022-08-12 09:47:52 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@a9f023e{/storage/rdd/json,null,AVAILABLE,@Spark}
2022-08-12 09:47:52 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@c27a3a2{/environment,null,AVAILABLE,@Spark}
2022-08-12 09:47:52 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@4b200971{/environment/json,null,AVAILABLE,@Spark}
2022-08-12 09:47:52 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@1a2bcd56{/executors,null,AVAILABLE,@Spark}
2022-08-12 09:47:52 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@68d7a2df{/executors/json,null,AVAILABLE,@Spark}
2022-08-12 09:47:52 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@59dc36d4{/executors/threadDump,null,AVAILABLE,@Spark}
2022-08-12 09:47:52 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@12fcc71f{/executors/threadDump/json,null,AVAILABLE,@Spark}
2022-08-12 09:47:52 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@5679e96b{/static,null,AVAILABLE,@Spark}
2022-08-12 09:47:52 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@5e519ad3{/,null,AVAILABLE,@Spark}
2022-08-12 09:47:52 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@7bc44ce8{/api,null,AVAILABLE,@Spark}
2022-08-12 09:47:52 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@53e800f9{/jobs/job/kill,null,AVAILABLE,@Spark}
2022-08-12 09:47:52 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@337bbfdf{/stages/stage/kill,null,AVAILABLE,@Spark}
2022-08-12 09:47:52 INFO SparkUI:54 - Bound SparkUI to 0.0.0.0, and started at http://master1.cdh6.aw:4040
2022-08-12 09:47:52 INFO ConfiguredRMFailoverProxyProvider:100 - Failing over to rm363
2022-08-12 09:47:52 INFO Client:54 - Requesting a new application from cluster with 3 NodeManagers
2022-08-12 09:47:52 INFO Client:54 - Verifying our application has not requested more than the maximum memory capability of the cluster (1537 MB per container)
2022-08-12 09:47:52 INFO Client:54 - Will allocate AM container, with 896 MB memory including 384 MB overhead
2022-08-12 09:47:52 INFO Client:54 - Setting up container launch context for our AM
2022-08-12 09:47:52 INFO Client:54 - Setting up the launch environment for our AM container
2022-08-12 09:47:52 INFO Client:54 - Preparing resources for our AM container
2022-08-12 09:47:52 ERROR SparkContext:91 - Error initializing SparkContext.
org.apache.hadoop.security.AccessControlException: Permission denied: user=root, access=WRITE, inode="/user":hdfs:supergroup:drwxr-xr-x
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:400)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:256)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:194)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1855)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1839)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkAncestorAccess(FSDirectory.java:1798)
at org.apache.hadoop.hdfs.server.namenode.FSDirMkdirOp.mkdirs(FSDirMkdirOp.java:61)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.mkdirs(FSNamesystem.java:3101)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.mkdirs(NameNodeRpcServer.java:1123)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.mkdirs(ClientNamenodeProtocolServerSideTranslatorPB.java:696)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:523)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:991)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:869)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:815)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1875)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2675)
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.hadoop.ipc.RemoteException.instantiateException(RemoteException.java:106)
at org.apache.hadoop.ipc.RemoteException.unwrapRemoteException(RemoteException.java:73)
at org.apache.hadoop.hdfs.DFSClient.primitiveMkdir(DFSClient.java:3002)
at org.apache.hadoop.hdfs.DFSClient.mkdirs(DFSClient.java:2970)
at org.apache.hadoop.hdfs.DistributedFileSystem$21.doCall(DistributedFileSystem.java:1047)
at org.apache.hadoop.hdfs.DistributedFileSystem$21.doCall(DistributedFileSystem.java:1043)
at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)
at org.apache.hadoop.hdfs.DistributedFileSystem.mkdirsInternal(DistributedFileSystem.java:1061)
at org.apache.hadoop.hdfs.DistributedFileSystem.mkdirs(DistributedFileSystem.java:1036)
at org.apache.hadoop.fs.FileSystem.mkdirs(FileSystem.java:1881)
at org.apache.hadoop.fs.FileSystem.mkdirs(FileSystem.java:600)
at org.apache.spark.deploy.yarn.Client.prepareLocalResources(Client.scala:427)
at org.apache.spark.deploy.yarn.Client.createContainerLaunchContext(Client.scala:864)
at org.apache.spark.deploy.yarn.Client.submitApplication(Client.scala:178)
at org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend.start(YarnClientSchedulerBackend.scala:57)
at org.apache.spark.scheduler.TaskSchedulerImpl.start(TaskSchedulerImpl.scala:178)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:501)
at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:2520)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$7.apply(SparkSession.scala:935)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$7.apply(SparkSession.scala:926)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:926)
at org.apache.spark.sql.hive.thriftserver.SparkSQLEnv$.init(SparkSQLEnv.scala:48)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.<init>(SparkSQLCLIDriver.scala:315)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver$.main(SparkSQLCLIDriver.scala:166)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.main(SparkSQLCLIDriver.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:849)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:167)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:195)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:86)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:924)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:933)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Caused by: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.AccessControlException): Permission denied: user=root, access=WRITE, inode="/user":hdfs:supergroup:drwxr-xr-x
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:400)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:256)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:194)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1855)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1839)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkAncestorAccess(FSDirectory.java:1798)
at org.apache.hadoop.hdfs.server.namenode.FSDirMkdirOp.mkdirs(FSDirMkdirOp.java:61)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.mkdirs(FSNamesystem.java:3101)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.mkdirs(NameNodeRpcServer.java:1123)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.mkdirs(ClientNamenodeProtocolServerSideTranslatorPB.java:696)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:523)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:991)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:869)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:815)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1875)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2675)
at org.apache.hadoop.ipc.Client.call(Client.java:1475)
at org.apache.hadoop.ipc.Client.call(Client.java:1412)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:229)
at com.sun.proxy.$Proxy12.mkdirs(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.mkdirs(ClientNamenodeProtocolTranslatorPB.java:558)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:191)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:102)
at com.sun.proxy.$Proxy13.mkdirs(Unknown Source)
at org.apache.hadoop.hdfs.DFSClient.primitiveMkdir(DFSClient.java:3000)
... 35 more
2022-08-12 09:47:52 INFO AbstractConnector:318 - Stopped Spark@6920614{HTTP/1.1,[http/1.1]}{0.0.0.0:4040}
2022-08-12 09:47:52 INFO SparkUI:54 - Stopped Spark web UI at http://master1.cdh6.aw:4040
2022-08-12 09:47:52 WARN YarnSchedulerBackend$YarnSchedulerEndpoint:66 - Attempted to request executors before the AM has registered!
2022-08-12 09:47:52 INFO YarnClientSchedulerBackend:54 - Stopped
2022-08-12 09:47:52 INFO MapOutputTrackerMasterEndpoint:54 - MapOutputTrackerMasterEndpoint stopped!
2022-08-12 09:47:52 INFO MemoryStore:54 - MemoryStore cleared
2022-08-12 09:47:52 INFO BlockManager:54 - BlockManager stopped
2022-08-12 09:47:52 INFO BlockManagerMaster:54 - BlockManagerMaster stopped
2022-08-12 09:47:52 WARN MetricsSystem:66 - Stopping a MetricsSystem that is not running
2022-08-12 09:47:52 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint:54 - OutputCommitCoordinator stopped!
2022-08-12 09:47:52 INFO SparkContext:54 - Successfully stopped SparkContext
Exception in thread "main" org.apache.hadoop.security.AccessControlException: Permission denied: user=root, access=WRITE, inode="/user":hdfs:supergroup:drwxr-xr-x
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:400)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:256)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:194)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1855)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1839)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkAncestorAccess(FSDirectory.java:1798)
at org.apache.hadoop.hdfs.server.namenode.FSDirMkdirOp.mkdirs(FSDirMkdirOp.java:61)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.mkdirs(FSNamesystem.java:3101)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.mkdirs(NameNodeRpcServer.java:1123)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.mkdirs(ClientNamenodeProtocolServerSideTranslatorPB.java:696)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:523)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:991)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:869)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:815)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1875)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2675)
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.hadoop.ipc.RemoteException.instantiateException(RemoteException.java:106)
at org.apache.hadoop.ipc.RemoteException.unwrapRemoteException(RemoteException.java:73)
at org.apache.hadoop.hdfs.DFSClient.primitiveMkdir(DFSClient.java:3002)
at org.apache.hadoop.hdfs.DFSClient.mkdirs(DFSClient.java:2970)
at org.apache.hadoop.hdfs.DistributedFileSystem$21.doCall(DistributedFileSystem.java:1047)
at org.apache.hadoop.hdfs.DistributedFileSystem$21.doCall(DistributedFileSystem.java:1043)
at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)
at org.apache.hadoop.hdfs.DistributedFileSystem.mkdirsInternal(DistributedFileSystem.java:1061)
at org.apache.hadoop.hdfs.DistributedFileSystem.mkdirs(DistributedFileSystem.java:1036)
at org.apache.hadoop.fs.FileSystem.mkdirs(FileSystem.java:1881)
at org.apache.hadoop.fs.FileSystem.mkdirs(FileSystem.java:600)
at org.apache.spark.deploy.yarn.Client.prepareLocalResources(Client.scala:427)
at org.apache.spark.deploy.yarn.Client.createContainerLaunchContext(Client.scala:864)
at org.apache.spark.deploy.yarn.Client.submitApplication(Client.scala:178)
at org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend.start(YarnClientSchedulerBackend.scala:57)
at org.apache.spark.scheduler.TaskSchedulerImpl.start(TaskSchedulerImpl.scala:178)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:501)
at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:2520)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$7.apply(SparkSession.scala:935)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$7.apply(SparkSession.scala:926)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:926)
at org.apache.spark.sql.hive.thriftserver.SparkSQLEnv$.init(SparkSQLEnv.scala:48)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.<init>(SparkSQLCLIDriver.scala:315)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver$.main(SparkSQLCLIDriver.scala:166)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.main(SparkSQLCLIDriver.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:849)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:167)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:195)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:86)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:924)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:933)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Caused by: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.AccessControlException): Permission denied: user=root, access=WRITE, inode="/user":hdfs:supergroup:drwxr-xr-x
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:400)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:256)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:194)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1855)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1839)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkAncestorAccess(FSDirectory.java:1798)
at org.apache.hadoop.hdfs.server.namenode.FSDirMkdirOp.mkdirs(FSDirMkdirOp.java:61)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.mkdirs(FSNamesystem.java:3101)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.mkdirs(NameNodeRpcServer.java:1123)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.mkdirs(ClientNamenodeProtocolServerSideTranslatorPB.java:696)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:523)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:991)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:869)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:815)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1875)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2675)
at org.apache.hadoop.ipc.Client.call(Client.java:1475)
at org.apache.hadoop.ipc.Client.call(Client.java:1412)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:229)
at com.sun.proxy.$Proxy12.mkdirs(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.mkdirs(ClientNamenodeProtocolTranslatorPB.java:558)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:191)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:102)
at com.sun.proxy.$Proxy13.mkdirs(Unknown Source)
at org.apache.hadoop.hdfs.DFSClient.primitiveMkdir(DFSClient.java:3000)
... 35 more
2022-08-12 09:47:52 INFO ShutdownHookManager:54 - Shutdown hook called
2022-08-12 09:47:52 INFO ShutdownHookManager:54 - Deleting directory /tmp/spark-3b285f1e-200e-4779-9b96-6c02c3200751
2022-08-12 09:47:52 INFO ShutdownHookManager:54 - Deleting directory /tmp/spark-7ee59a88-7409-45c2-9e39-82d295bd5467
3.java.lang.ClassNotFoundException: org.apache.spark.scheduler.cluster.CoarseGrainedClusterMessages$RetrieveDelegationTokens$
单机安装的时候执行spark-sql遇到报错
ERROR server.TransportRequestHandler: Error while invoking RpcHandler#receive() on RPC id 6405719561689998953
java.lang.ClassNotFoundException: org.apache.spark.scheduler.cluster.CoarseGrainedClusterMessages$RetrieveDelegationTokens$
.......
Caused by: java.lang.ClassNotFoundException: com.cloudera.spark.lineage.NavigatorAppListener
完整报错如下:
[aw-bdp-dwh@node00 ~]$ spark-sql
22/10/14 15:05:26 WARN conf.HiveConf: HiveConf of name hive.vectorized.use.checked.expressions does not exist
22/10/14 15:05:26 WARN conf.HiveConf: HiveConf of name hive.strict.checks.no.partition.filter does not exist
22/10/14 15:05:26 WARN conf.HiveConf: HiveConf of name hive.vectorized.use.vector.serde.deserialize does not exist
22/10/14 15:05:26 WARN conf.HiveConf: HiveConf of name hive.strict.checks.orderby.no.limit does not exist
22/10/14 15:05:26 WARN conf.HiveConf: HiveConf of name hive.vectorized.adaptor.usage.mode does not exist
22/10/14 15:05:26 WARN conf.HiveConf: HiveConf of name hive.vectorized.use.vectorized.input.format does not exist
22/10/14 15:05:26 WARN conf.HiveConf: HiveConf of name hive.vectorized.input.format.excludes does not exist
22/10/14 15:05:26 WARN conf.HiveConf: HiveConf of name hive.strict.checks.bucketing does not exist
22/10/14 15:05:26 WARN conf.HiveConf: HiveConf of name hive.strict.checks.type.safety does not exist
22/10/14 15:05:26 WARN conf.HiveConf: HiveConf of name hive.strict.checks.cartesian.product does not exist
22/10/14 15:05:26 INFO hive.metastore: Trying to connect to metastore with URI thrift://node00.cdh6.test:9083
22/10/14 15:05:26 INFO hive.metastore: Connected to metastore.
22/10/14 15:05:27 INFO session.SessionState: Created local directory: /tmp/9d7c2114-cef7-4963-a0ce-c5e41267550e_resources
22/10/14 15:05:27 INFO session.SessionState: Created HDFS directory: /tmp/hive/aw-bdp-dwh/9d7c2114-cef7-4963-a0ce-c5e41267550e
22/10/14 15:05:27 INFO session.SessionState: Created local directory: /tmp/aw-bdp-dwh/9d7c2114-cef7-4963-a0ce-c5e41267550e
22/10/14 15:05:27 INFO session.SessionState: Created HDFS directory: /tmp/hive/aw-bdp-dwh/9d7c2114-cef7-4963-a0ce-c5e41267550e/_tmp_space.db
22/10/14 15:05:28 INFO util.log: Logging initialized @3411ms
22/10/14 15:05:28 INFO server.Server: jetty-9.3.z-SNAPSHOT, build timestamp: unknown, git hash: unknown
22/10/14 15:05:28 INFO server.Server: Started @3491ms
22/10/14 15:05:28 INFO server.AbstractConnector: Started ServerConnector@7a0ef219{HTTP/1.1,[http/1.1]}{0.0.0.0:4040}
22/10/14 15:05:28 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@6403e24c{/jobs,null,AVAILABLE,@Spark}
22/10/14 15:05:28 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@54e3658c{/jobs/json,null,AVAILABLE,@Spark}
22/10/14 15:05:28 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@43e9089{/jobs/job,null,AVAILABLE,@Spark}
22/10/14 15:05:28 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@352c44a8{/jobs/job/json,null,AVAILABLE,@Spark}
22/10/14 15:05:28 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@7aac8884{/stages,null,AVAILABLE,@Spark}
22/10/14 15:05:28 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@a66e580{/stages/json,null,AVAILABLE,@Spark}
22/10/14 15:05:28 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@5b852b49{/stages/stage,null,AVAILABLE,@Spark}
22/10/14 15:05:28 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@2f5ac102{/stages/stage/json,null,AVAILABLE,@Spark}
22/10/14 15:05:28 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@5df778c3{/stages/pool,null,AVAILABLE,@Spark}
22/10/14 15:05:28 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@895416d{/stages/pool/json,null,AVAILABLE,@Spark}
22/10/14 15:05:28 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@71a06021{/storage,null,AVAILABLE,@Spark}
22/10/14 15:05:28 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@80bfdc6{/storage/json,null,AVAILABLE,@Spark}
22/10/14 15:05:28 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@6edcad64{/storage/rdd,null,AVAILABLE,@Spark}
22/10/14 15:05:28 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@4c6007fb{/storage/rdd/json,null,AVAILABLE,@Spark}
22/10/14 15:05:28 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@3e33d73e{/environment,null,AVAILABLE,@Spark}
22/10/14 15:05:28 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@6981f8f3{/environment/json,null,AVAILABLE,@Spark}
22/10/14 15:05:28 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@623dcf2a{/executors,null,AVAILABLE,@Spark}
22/10/14 15:05:28 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@2eae4349{/executors/json,null,AVAILABLE,@Spark}
22/10/14 15:05:28 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@e84fb85{/executors/threadDump,null,AVAILABLE,@Spark}
22/10/14 15:05:28 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@68a4dcc6{/executors/threadDump/json,null,AVAILABLE,@Spark}
22/10/14 15:05:28 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@646c0a67{/static,null,AVAILABLE,@Spark}
22/10/14 15:05:28 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@15400fff{/,null,AVAILABLE,@Spark}
22/10/14 15:05:28 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@18d910b3{/api,null,AVAILABLE,@Spark}
22/10/14 15:05:28 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@277b8fa4{/jobs/job/kill,null,AVAILABLE,@Spark}
22/10/14 15:05:28 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@6cd64ee8{/stages/stage/kill,null,AVAILABLE,@Spark}
22/10/14 15:05:28 INFO client.RMProxy: Connecting to ResourceManager at node00.cdh6.test/192.168.8.11:8032
22/10/14 15:05:29 INFO impl.YarnClientImpl: Submitted application application_1665728941521_0007
22/10/14 15:05:32 ERROR server.TransportRequestHandler: Error while invoking RpcHandler#receive() on RPC id 6405719561689998953
java.lang.ClassNotFoundException: org.apache.spark.scheduler.cluster.CoarseGrainedClusterMessages$RetrieveDelegationTokens$
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:348)
at org.apache.spark.serializer.JavaDeserializationStream$$anon$1.resolveClass(JavaSerializer.scala:67)
at java.io.ObjectInputStream.readNonProxyDesc(ObjectInputStream.java:1868)
at java.io.ObjectInputStream.readClassDesc(ObjectInputStream.java:1751)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2042)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1573)
at java.io.ObjectInputStream.readObject(ObjectInputStream.java:431)
at org.apache.spark.serializer.JavaDeserializationStream.readObject(JavaSerializer.scala:75)
at org.apache.spark.serializer.JavaSerializerInstance.deserialize(JavaSerializer.scala:108)
at org.apache.spark.rpc.netty.NettyRpcEnv$$anonfun$deserialize$1$$anonfun$apply$1.apply(NettyRpcEnv.scala:271)
at scala.util.DynamicVariable.withValue(DynamicVariable.scala:58)
at org.apache.spark.rpc.netty.NettyRpcEnv.deserialize(NettyRpcEnv.scala:320)
at org.apache.spark.rpc.netty.NettyRpcEnv$$anonfun$deserialize$1.apply(NettyRpcEnv.scala:270)
at scala.util.DynamicVariable.withValue(DynamicVariable.scala:58)
at org.apache.spark.rpc.netty.NettyRpcEnv.deserialize(NettyRpcEnv.scala:269)
at org.apache.spark.rpc.netty.RequestMessage$.apply(NettyRpcEnv.scala:611)
at org.apache.spark.rpc.netty.NettyRpcHandler.internalReceive(NettyRpcEnv.scala:662)
at org.apache.spark.rpc.netty.NettyRpcHandler.receive(NettyRpcEnv.scala:647)
at org.apache.spark.network.server.TransportRequestHandler.processRpcRequest(TransportRequestHandler.java:181)
at org.apache.spark.network.server.TransportRequestHandler.handle(TransportRequestHandler.java:103)
at org.apache.spark.network.server.TransportChannelHandler.channelRead(TransportChannelHandler.java:118)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:362)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:348)
at io.netty.channel.AbstractChannelHandlerContext.fireChannelRead(AbstractChannelHandlerContext.java:340)
at io.netty.handler.timeout.IdleStateHandler.channelRead(IdleStateHandler.java:286)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:362)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:348)
at io.netty.channel.AbstractChannelHandlerContext.fireChannelRead(AbstractChannelHandlerContext.java:340)
at io.netty.handler.codec.MessageToMessageDecoder.channelRead(MessageToMessageDecoder.java:102)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:362)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:348)
at io.netty.channel.AbstractChannelHandlerContext.fireChannelRead(AbstractChannelHandlerContext.java:340)
at org.apache.spark.network.util.TransportFrameDecoder.channelRead(TransportFrameDecoder.java:85)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:362)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:348)
at io.netty.channel.AbstractChannelHandlerContext.fireChannelRead(AbstractChannelHandlerContext.java:340)
at io.netty.channel.DefaultChannelPipeline$HeadContext.channelRead(DefaultChannelPipeline.java:1359)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:362)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:348)
at io.netty.channel.DefaultChannelPipeline.fireChannelRead(DefaultChannelPipeline.java:935)
at io.netty.channel.nio.AbstractNioByteChannel$NioByteUnsafe.read(AbstractNioByteChannel.java:138)
at io.netty.channel.nio.NioEventLoop.processSelectedKey(NioEventLoop.java:645)
at io.netty.channel.nio.NioEventLoop.processSelectedKeysOptimized(NioEventLoop.java:580)
at io.netty.channel.nio.NioEventLoop.processSelectedKeys(NioEventLoop.java:497)
at io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:459)
at io.netty.util.concurrent.SingleThreadEventExecutor$5.run(SingleThreadEventExecutor.java:858)
at io.netty.util.concurrent.DefaultThreadFactory$DefaultRunnableDecorator.run(DefaultThreadFactory.java:138)
at java.lang.Thread.run(Thread.java:748)
22/10/14 15:05:33 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@5e67a490{/metrics/json,null,AVAILABLE,@Spark}
22/10/14 15:05:33 WARN cluster.YarnSchedulerBackend$YarnSchedulerEndpoint: Attempted to request executors before the AM has registered!
22/10/14 15:05:33 INFO server.AbstractConnector: Stopped Spark@7a0ef219{HTTP/1.1,[http/1.1]}{0.0.0.0:4040}
22/10/14 15:05:33 WARN cluster.YarnSchedulerBackend$YarnSchedulerEndpoint: Attempted to request executors before the AM has registered!
22/10/14 15:05:33 ERROR spark.SparkContext: Error initializing SparkContext.
org.apache.spark.SparkException: Exception when registering SparkListener
at org.apache.spark.SparkContext.setupAndStartListenerBus(SparkContext.scala:2398)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:555)
at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:2520)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$7.apply(SparkSession.scala:935)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$7.apply(SparkSession.scala:926)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:926)
at org.apache.spark.sql.hive.thriftserver.SparkSQLEnv$.init(SparkSQLEnv.scala:48)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.<init>(SparkSQLCLIDriver.scala:315)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver$.main(SparkSQLCLIDriver.scala:166)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.main(SparkSQLCLIDriver.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:849)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:167)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:195)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:86)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:924)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:933)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Caused by: java.lang.ClassNotFoundException: com.cloudera.spark.lineage.NavigatorAppListener
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:348)
at org.apache.spark.util.Utils$.classForName(Utils.scala:238)
at org.apache.spark.util.Utils$$anonfun$loadExtensions$1.apply(Utils.scala:2682)
at org.apache.spark.util.Utils$$anonfun$loadExtensions$1.apply(Utils.scala:2680)
at scala.collection.TraversableLike$$anonfun$flatMap$1.apply(TraversableLike.scala:241)
at scala.collection.TraversableLike$$anonfun$flatMap$1.apply(TraversableLike.scala:241)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48)
at scala.collection.TraversableLike$class.flatMap(TraversableLike.scala:241)
at scala.collection.AbstractTraversable.flatMap(Traversable.scala:104)
at org.apache.spark.util.Utils$.loadExtensions(Utils.scala:2680)
at org.apache.spark.SparkContext$$anonfun$setupAndStartListenerBus$1.apply(SparkContext.scala:2387)
at org.apache.spark.SparkContext$$anonfun$setupAndStartListenerBus$1.apply(SparkContext.scala:2386)
at scala.Option.foreach(Option.scala:257)
at org.apache.spark.SparkContext.setupAndStartListenerBus(SparkContext.scala:2386)
... 22 more
Exception in thread "main" org.apache.spark.SparkException: Exception when registering SparkListener
at org.apache.spark.SparkContext.setupAndStartListenerBus(SparkContext.scala:2398)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:555)
at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:2520)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$7.apply(SparkSession.scala:935)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$7.apply(SparkSession.scala:926)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:926)
at org.apache.spark.sql.hive.thriftserver.SparkSQLEnv$.init(SparkSQLEnv.scala:48)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.<init>(SparkSQLCLIDriver.scala:315)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver$.main(SparkSQLCLIDriver.scala:166)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.main(SparkSQLCLIDriver.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:849)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:167)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:195)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:86)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:924)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:933)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Caused by: java.lang.ClassNotFoundException: com.cloudera.spark.lineage.NavigatorAppListener
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:348)
at org.apache.spark.util.Utils$.classForName(Utils.scala:238)
at org.apache.spark.util.Utils$$anonfun$loadExtensions$1.apply(Utils.scala:2682)
at org.apache.spark.util.Utils$$anonfun$loadExtensions$1.apply(Utils.scala:2680)
at scala.collection.TraversableLike$$anonfun$flatMap$1.apply(TraversableLike.scala:241)
at scala.collection.TraversableLike$$anonfun$flatMap$1.apply(TraversableLike.scala:241)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48)
at scala.collection.TraversableLike$class.flatMap(TraversableLike.scala:241)
at scala.collection.AbstractTraversable.flatMap(Traversable.scala:104)
at org.apache.spark.util.Utils$.loadExtensions(Utils.scala:2680)
at org.apache.spark.SparkContext$$anonfun$setupAndStartListenerBus$1.apply(SparkContext.scala:2387)
at org.apache.spark.SparkContext$$anonfun$setupAndStartListenerBus$1.apply(SparkContext.scala:2386)
at scala.Option.foreach(Option.scala:257)
at org.apache.spark.SparkContext.setupAndStartListenerBus(SparkContext.scala:2386)
... 22 more
解决方案:
主要修改点在下面标注处,此方法主要使用于local调用方式。
如果集群调用,建议将相关jar包上传hdfs,然后此处写hdfs的路径,
例如:spark.yarn.jars=hdfs://nameservice1/user/spark2/jars/*
上传的jar包:hdfs dfs -put /opt/cloudera/parcels/CDH/lib/spark2/jars/* hdfs://nameservice1/user/spark2/jars/
[root@node00 conf]# cat /opt/cloudera/parcels/CDH/lib/spark2/conf/spark-defaults.conf
spark.authenticate=false
spark.driver.log.dfsDir=/user/spark/driverLogs
spark.driver.log.persistToDfs.enabled=true
spark.dynamicAllocation.enabled=true
spark.dynamicAllocation.executorIdleTimeout=60
spark.dynamicAllocation.minExecutors=0
spark.dynamicAllocation.schedulerBacklogTimeout=1
spark.eventLog.enabled=true
spark.io.encryption.enabled=false
spark.network.crypto.enabled=false
spark.serializer=org.apache.spark.serializer.KryoSerializer
spark.shuffle.service.enabled=true
spark.shuffle.service.port=7337
spark.ui.enabled=true
spark.ui.killEnabled=true
spark.lineage.log.dir=/var/log/spark/lineage
spark.lineage.enabled=true
spark.master=yarn
spark.submit.deployMode=client
spark.eventLog.dir=hdfs://node00.cdh6.test:8020/user/spark/applicationHistory
spark.yarn.historyServer.address=http://node00.cdh6.test:18088
spark.yarn.jars=local:/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/spark2/jars/*,local:/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/spark2/hive/*
spark.driver.extraLibraryPath=/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/hadoop/lib/native
spark.executor.extraLibraryPath=/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/hadoop/lib/native
spark.yarn.am.extraLibraryPath=/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/hadoop/lib/native
spark.yarn.config.gatewayPath=/opt/cloudera/parcels
spark.yarn.config.replacementPath={{HADOOP_COMMON_HOME}}/…/…/…
spark.yarn.historyServer.allowTracking=true
spark.yarn.appMasterEnv.MKL_NUM_THREADS=1
spark.executorEnv.MKL_NUM_THREADS=1
spark.yarn.appMasterEnv.OPENBLAS_NUM_THREADS=1
spark.executorEnv.OPENBLAS_NUM_THREADS=1
#spark.extraListeners=com.cloudera.spark.lineage.NavigatorAppListener
#spark.sql.queryExecutionListeners=com.cloudera.spark.lineage.NavigatorQueryListener
















 943
943











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











