











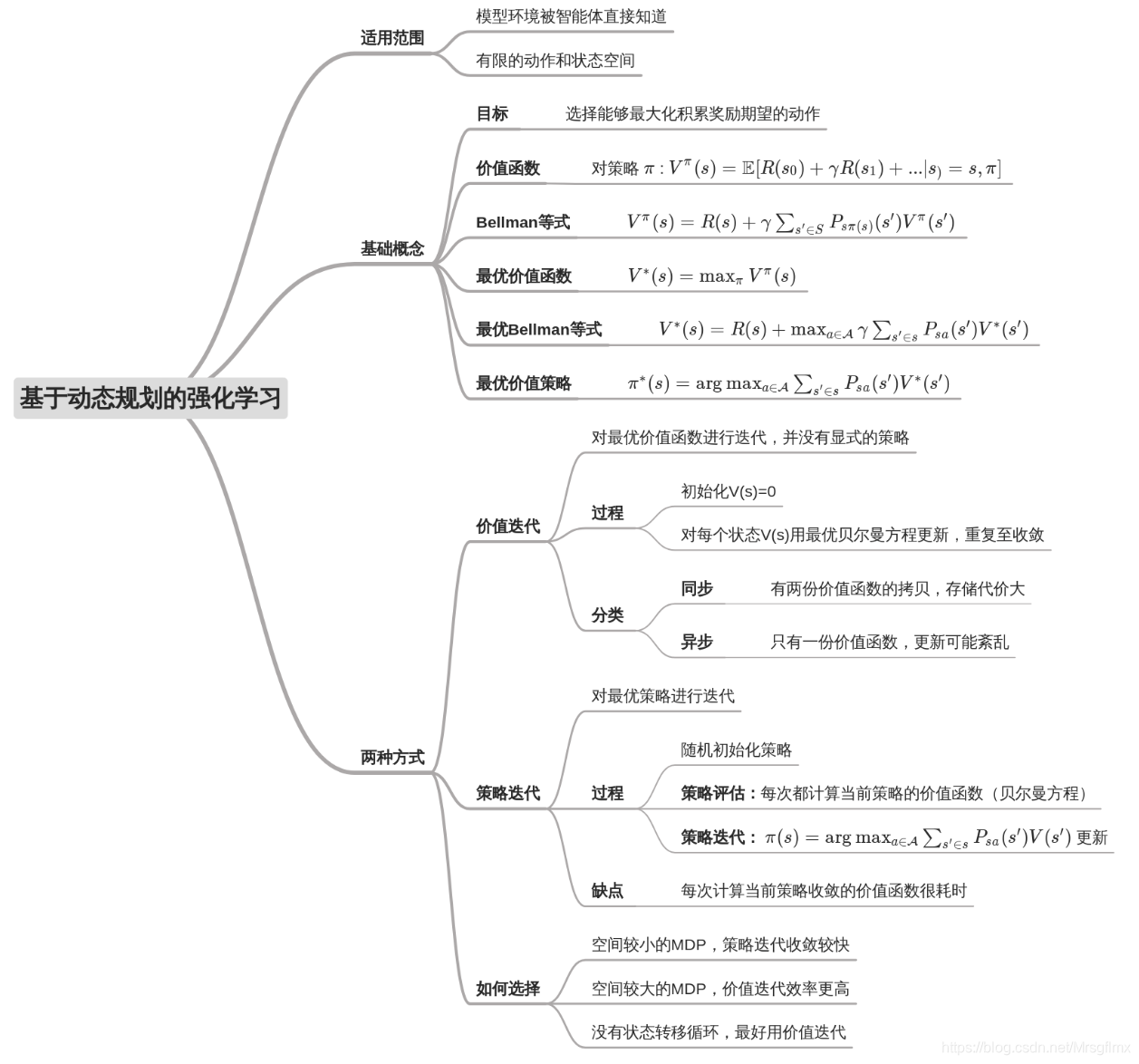
(1)价值迭代的同步更新和异步更新在收敛速度和效果上有什么区别?
异步更新的收敛一般收敛得快一些。但是如果没有达到收敛,异步更新得到的部分状态的价值可能和ground truth差距较大,不敢直接用来构建policy。原因是异步更新可能使得部分状态更新得不如别的状态快。
(2)在价值迭代中,因为gamma这个01之间衰减率的存在,算法可以收敛。那么在策略迭代中,有没有方法证明其一定可以收敛?
有的。在David Silver的DRL课程的Lecture 3中最后有提到,可以利用压缩映射定理(Contraction Mapping Theorem)证明其收敛性。
(3)为什么空间较小的MDP,策略迭代收敛很快;而空间较大,价值迭代更实用?
策略迭代是对于策略的直接优化,所以在空间较小的MDP上可以收敛很快,但是策略本身是基于当前状态动作的分布;价值迭代是对于通过对状态评估间接得出最优的策略,价值迭代本身是基于状态的分布,所以更加稳定高效。
(4)价值迭代可以保证价值函数V收敛到全局最优值吗?
在基于表格的(也就是在状态动作空间有限且较小的环境)价值迭代策略中,价值函数的收敛性是有保证的,但是使用函数近似的价值函数V的收敛性则不一定。
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
如果大家喜欢这篇文章的话,希望大家收藏、转发、关注、评论、点赞,转载请注明出自这里。 PS:本随笔属个人学习小结,文中内容有参考互联网上的相关文章。如果您博文的链接被我引用,我承诺不会参杂经济利益;如果有版权纠纷,请私信留言。其中如果发现文中有不正确的认知或遗漏的地方请评论告知,谢谢! 还是那句话:不是我喜欢copy,是站在巨人的肩膀上~~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









