







定义一个函数
你可以定义一个由自己想要功能的函数,以下是简单的规则:
- 函数代码块以 def 关键词开头,后接函数标识符名称和圆括号()。
- 任何传入参数和自变量必须放在圆括号中间。圆括号之间可以用于定义参数。
- 函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明。
- 函数内容以冒号起始,并且缩进。
- return [表达式] 结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回 None。
-
语法
def functionname( parameters ): "函数_文档字符串" function_suite return [expression]默认情况下,参数值和参数名称是按函数声明中定义的的顺序匹配起来的。
函数调用
定义一个函数只给了函数一个名称,指定了函数里包含的参数,和代码块结构。
这个函数的基本结构完成以后,你可以通过另一个函数调用执行,也可以直接从Python提示符执行。
如下实例调用了printme()函数:#!/usr/bin/python # -*- coding: UTF-8 -*- # 定义函数 def printme( str ): "打印任何传入的字符串" print str; return; # 调用函数 printme("我要调用用户自定义函数!"); printme("再次调用同一函数");以上实例输出结果:
我要调用用户自定义函数! 再次调用同一函数按值传递参数和按引用传递参数
所有参数(自变量)在Python里都是按引用传递。如果你在函数里修改了参数,那么在调用这个函数的函数里,原始的参数也被改变了。例如:
#!/usr/bin/python # -*- coding: UTF-8 -*- # 可写函数说明 def changeme( mylist ): "修改传入的列表" mylist.append([1,2,3,4]); print "函数内取值: ", mylist return # 调用changeme函数 mylist = [10,20,30]; changeme( mylist ); print "函数外取值: ", mylist传入函数的和在末尾添加新内容的对象用的是同一个引用。故输出结果如下:
函数内取值: [10, 20, 30, [1, 2, 3, 4]] 函数外取值: [10, 20, 30, [1, 2, 3, 4]]参数
以下是调用函数时可使用的正式参数类型:
必备参数
关键字参数
默认参数
不定长参数必备参数
必备参数须以正确的顺序传入函数。调用时的数量必须和声明时的一样。
调用printme()函数,你必须传入一个参数,不然会出现语法错误:#!/usr/bin/python # -*- coding: UTF-8 -*- #可写函数说明 def printme( str ): "打印任何传入的字符串" print str; return; #调用printme函数 printme();以上实例输出结果:
Traceback (most recent call last): File "test.py", line 11, in <module> printme(); TypeError: printme() takes exactly 1 argument (0 given)关键字参数
关键字参数和函数调用关系紧密,函数调用使用关键字参数来确定传入的参数值。
使用关键字参数允许函数调用时参数的顺序与声明时不一致,因为 Python 解释器能够用参数名匹配参数值。
以下实例在函数 printme() 调用时使用参数名:
#!/usr/bin/python # -*- coding: UTF-8 -*- #可写函数说明 def printme( str ): "打印任何传入的字符串" print str; return; #调用printme函数 printme( str = "My string"); 以上实例输出结果: My string 下例能将关键字参数顺序不重要展示得更清楚: #!/usr/bin/python # -*- coding: UTF-8 -*- #可写函数说明 def printinfo( name, age ): "打印任何传入的字符串" print "Name: ", name; print "Age ", age; return; #调用printinfo函数 printinfo( age=50, name="miki" );以上实例输出结果:
Name: miki
Age 50缺省参数
调用函数时,缺省参数的值如果没有传入,则被认为是默认值。下例会打印默认的age,如果age没有被传入:
#!/usr/bin/python # -*- coding: UTF-8 -*- #可写函数说明 def printinfo( name, age = 35 ): "打印任何传入的字符串" print "Name: ", name; print "Age ", age; return; #调用printinfo函数 printinfo( age=50, name="miki" ); printinfo( name="miki" );以上实例输出结果:
Name: miki Age 50 Name: miki Age 35不定长参数
你可能需要一个函数能处理比当初声明时更多的参数。这些参数叫做不定长参数,和上述2种参数不同,声明时不会命名。基本语法如下:
def functionname([formal_args,] *var_args_tuple ): "函数_文档字符串" function_suite return [expression]加了星号(*)的变量名会存放所有未命名的变量参数。选择不多传参数也可。如下实例:
#!/usr/bin/python # -*- coding: UTF-8 -*- # 可写函数说明 def printinfo( arg1, *vartuple ): "打印任何传入的参数" print "输出: " print arg1 for var in vartuple: print var return; # 调用printinfo 函数 printinfo( 10 ); printinfo( 70, 60, 50 );以上实例输出结果:
输出: 10 输出: 70 60 50匿名函数
python 使用 lambda 来创建匿名函数。
lambda只是一个表达式,函数体比def简单很多。
lambda的主体是一个表达式,而不是一个代码块。仅仅能在lambda表达式中封装有限的逻辑进去。
lambda函数拥有自己的命名空间,且不能访问自有参数列表之外或全局命名空间里的参数。
虽然lambda函数看起来只能写一行,却不等同于C或C++的内联函数,后者的目的是调用小函数时不占用栈内存从而增加运行效率。
语法
lambda函数的语法只包含一个语句,如下:
lambda [arg1 [,arg2,.....argn]]:expression如下实例:
#!/usr/bin/python # -*- coding: UTF-8 -*- # 可写函数说明 sum = lambda arg1, arg2: arg1 + arg2; # 调用sum函数 print "相加后的值为 : ", sum( 10, 20 ) print "相加后的值为 : ", sum( 20, 20 )以上实例输出结果:
相加后的值为 : 30 相加后的值为 : 40return语句
return语句[表达式]退出函数,选择性地向调用方返回一个表达式。不带参数值的return语句返回None。之前的例子都没有示范如何返回数值,下例便告诉你怎么做:
#!/usr/bin/python # -*- coding: UTF-8 -*- # 可写函数说明 def sum( arg1, arg2 ): # 返回2个参数的和." total = arg1 + arg2 print "函数内 : ", total return total; # 调用sum函数 total = sum( 10, 20 ); print "函数外 : ", total以上实例输出结果:
函数内 : 30 函数外 : 30变量作用域
一个程序的所有的变量并不是在哪个位置都可以访问的。访问权限决定于这个变量是在哪里赋值的。
变量的作用域决定了在哪一部分程序你可以访问哪个特定的变量名称。两种最基本的变量作用域如下:
全局变量
局部变量全局变量和局部变量
定义在函数内部的变量拥有一个局部作用域,定义在函数外的拥有全局作用域。
局部变量只能在其被声明的函数内部访问,而全局变量可以在整个程序范围内访问。调用函数时,所有在函数内声明的变量名称都将被加入到作用域中。如下实例:
#!/usr/bin/python # -*- coding: UTF-8 -*- total = 0; # 这是一个全局变量 # 可写函数说明 def sum( arg1, arg2 ): #返回2个参数的和." total = arg1 + arg2; # total在这里是局部变量. print "函数内是局部变量 : ", total return total; #调用sum函数 sum( 10, 20 ); print "函数外是全局变量 : ", total以上实例输出结果:
函数内是局部变量 : 30 函数外是全局变量 : 0Python 模块
模块让你能够有逻辑地组织你的Python代码段。
把相关的代码分配到一个 模块里能让你的代码更好用,更易懂。
模块也是Python对象,具有随机的名字属性用来绑定或引用。
简单地说,模块就是一个保存了Python代码的文件。模块能定义函数,类和变量。模块里也能包含可执行的代码。
例子一个叫做aname的模块里的Python代码一般都能在一个叫aname.py的文件中找到。下例是个简单的模块support.py。
def print_func( par ): print "Hello : ", par returnimport 语句
想使用Python源文件,只需在另一个源文件里执行import语句,语法如下:
import module1[, module2[,... moduleN]当解释器遇到import语句,如果模块在当前的搜索路径就会被导入。
搜索路径是一个解释器会先进行搜索的所有目录的列表。如想要导入模块hello.py,需要把命令放在脚本的顶端:
#!/usr/bin/python # -*- coding: UTF-8 -*- # 导入模块 import support # 现在可以调用模块里包含的函数了 support.print_func("Zara")以上实例输出结果:
Hello : Zara一个模块只会被导入一次,不管你执行了多少次import。这样可以防止导入模块被一遍又一遍地执行。
From…import 语句
Python的from语句让你从模块中导入一个指定的部分到当前命名空间中。语法如下:
from modname import name1[, name2[, ... nameN]]例如,要导入模块fib的fibonacci函数,使用如下语句:
from fib import fibonacci这个声明不会把整个fib模块导入到当前的命名空间中,它只会将fib里的fibonacci单个引入到执行这个声明的模块的全局符号表。
From…import* 语句
把一个模块的所有内容全都导入到当前的命名空间也是可行的,只需使用如下声明:
from modname import *这提供了一个简单的方法来导入一个模块中的所有项目。然而这种声明不该被过多地使用。
定位模块
当你导入一个模块,Python解析器对模块位置的搜索顺序是:
- 当前目录
- 如果不在当前目录,Python 则搜索在 shell 变量 PYTHONPATH 下的每个目录。
- 如果都找不到,Python会察看默认路径。UNIX下,默认路径一般为/usr/local/lib/python/。
-
模块搜索路径存储在system模块的sys.path变量中。变量里包含当前目录,PYTHONPATH和由安装过程决定的默认目录。
PYTHONPATH变量
作为环境变量,PYTHONPATH由装在一个列表里的许多目录组成。PYTHONPATH的语法和shell变量PATH的一样。
在Windows系统,典型的PYTHONPATH如下:
set PYTHONPATH=c:\python20\lib;在UNIX系统,典型的PYTHONPATH如下:
set PYTHONPATH=/usr/local/lib/python命名空间和作用域
变量是拥有匹配对象的名字(标识符)。命名空间是一个包含了变量名称们(键)和它们各自相应的对象们(值)的字典。
一个Python表达式可以访问局部命名空间和全局命名空间里的变量。如果一个局部变量和一个全局变量重名,则局部变量会覆盖全局变量。
每个函数都有自己的命名空间。类的方法的作用域规则和通常函数的一样。
Python会智能地猜测一个变量是局部的还是全局的,它假设任何在函数内赋值的变量都是局部的。
因此,如果要给全局变量在一个函数里赋值,必须使用global语句。
global VarName的表达式会告诉Python, VarName是一个全局变量,这样Python就不会在局部命名空间里寻找这个变量了。
例如,我们在全局命名空间里定义一个变量money。我们再在函数内给变量money赋值,然后Python会假定money是一个局部变量。然而,我们并没有在访问前声明一个局部变量money,结果就是会出现一个UnboundLocalError的错误。取消global语句的注释就能解决这个问题。
#!/usr/bin/python # -*- coding: UTF-8 -*- Money = 2000 def AddMoney(): # 想改正代码就取消以下注释: # global Money Money = Money + 1 print Money AddMoney() print Moneydir()函数
dir()函数一个排好序的字符串列表,内容是一个模块里定义过的名字。
返回的列表容纳了在一个模块里定义的所有模块,变量和函数。如下一个简单的实例:
#!/usr/bin/python # -*- coding: UTF-8 -*- # 导入内置math模块 import math content = dir(math) print content;以上实例输出结果:
['__doc__', '__file__', '__name__', 'acos', 'asin', 'atan', 'atan2', 'ceil', 'cos', 'cosh', 'degrees', 'e', 'exp', 'fabs', 'floor', 'fmod', 'frexp', 'hypot', 'ldexp', 'log', 'log10', 'modf', 'pi', 'pow', 'radians', 'sin', 'sinh', 'sqrt', 'tan', 'tanh']在这里,特殊字符串变量name指向模块的名字,file指向该模块的导入文件名。
globals()和locals()函数
根据调用地方的不同,globals()和locals()函数可被用来返回全局和局部命名空间里的名字。
如果在函数内部调用locals(),返回的是所有能在该函数里访问的命名。
如果在函数内部调用globals(),返回的是所有在该函数里能访问的全局名字。
两个函数的返回类型都是字典。所以名字们能用keys()函数摘取。
reload()函数
当一个模块被导入到一个脚本,模块顶层部分的代码只会被执行一次。
因此,如果你想重新执行模块里顶层部分的代码,可以用reload()函数。该函数会重新导入之前导入过的模块。语法如下:
reload(module_name)在这里,module_name要直接放模块的名字,而不是一个字符串形式。比如想重载hello模块,如下:
reload(hello)Python中的包
包是一个分层次的文件目录结构,它定义了一个由模块及子包,和子包下的子包等组成的Python的应用环境。
考虑一个在Phone目录下的pots.py文件。这个文件有如下源代码:
#!/usr/bin/python # -*- coding: UTF-8 -*- def Pots(): print "I'm Pots Phone"同样地,我们有另外两个保存了不同函数的文件:
Phone/Isdn.py 含有函数Isdn() Phone/G3.py 含有函数G3()现在,在Phone目录下创建file init.py:
Phone/__init__.py当你导入Phone时,为了能够使用所有函数,你需要在init.py里使用显式的导入语句,如下:
from Pots import Pots from Isdn import Isdn from G3 import G3当你把这些代码添加到init.py之后,导入Phone包的时候这些类就全都是可用的了。
#!/usr/bin/python # -*- coding: UTF-8 -*- # 导入 Phone 包 import Phone Phone.Pots() Phone.Isdn() Phone.G3()以上实例输出结果:
I'm Pots Phone I'm 3G Phone I'm ISDN Phone如上,为了举例,我们只在每个文件里放置了一个函数,但其实你可以放置许多函数。你也可以在这些文件里定义Python的类,然后为这些类建一个包。
Python 文件I/O
本章只讲述所有基本的的I/O函数,更多函数请参考Python标准文档。
打印到屏幕
最简单的输出方法是用print语句,你可以给它传递零个或多个用逗号隔开的表达式。此函数把你传递的表达式转换成一个字符串表达式,并将结果写到标准输出如下:
#!/usr/bin/python # -*- coding: UTF-8 -*- print "Python 是一个非常棒的语言,不是吗?";你的标准屏幕上会产生以下结果:
Python 是一个非常棒的语言,不是吗?读取键盘输入
Python提供了两个内置函数从标准输入读入一行文本,默认的标准输入是键盘。如下:
raw_input inputraw_input函数
raw_input([prompt]) 函数从标准输入读取一个行,并返回一个字符串(去掉结尾的换行符):
#!/usr/bin/python # -*- coding: UTF-8 -*- str = raw_input("请输入:"); print "你输入的内容是: ", str这将提示你输入任意字符串,然后在屏幕上显示相同的字符串。当我输入”Hello Python!”,它的输出如下:
请输入:Hello Python! 你输入的内容是: Hello Python!input函数
input([prompt]) 函数和 raw_input([prompt]) 函数基本类似,但是 input 可以接收一个Python表达式作为输入,并将运算结果返回。
#!/usr/bin/python # -*- coding: UTF-8 -*- str = input("请输入:"); print "你输入的内容是: ", str这会产生如下的对应着输入的结果:
请输入:[x*5 for x in range(2,10,2)] 你输入的内容是: [10, 20, 30, 40]打开和关闭文件
现在,您已经可以向标准输入和输进行读写。现在,来看看怎么读写实际的数据文件。
Python 提供了必要的函数和方法进行默认情况下的文件基本操作。你可以用 file 对象做大部分的文件操作。
open 函数
你必须先用Python内置的open()函数打开一个文件,创建一个file对象,相关的方法才可以调用它进行读写。
语法:file object = open(file_name [, access_mode][, buffering])各个参数的细节如下:
- file_name:file_name变量是一个包含了你要访问的文件名称的字符串值。
- access_mode:access_mode决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读(r)。
- buffering:如果buffering的值被设为0,就不会有寄存。如果buffering的值取1,访问文件时会寄存行。如果将
- buffering的值设为大于1的整数,表明了这就是的寄存区的缓冲大小。如果取负值,寄存区的缓冲大小则为系统默认。
-
不同模式打开文件的完全列表:
File对象的属性
一个文件被打开后,你有一个file对象,你可以得到有关该文件的各种信息。
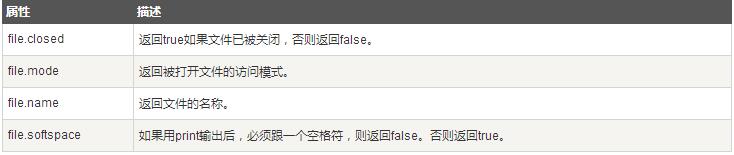
以下是和file对象相关的所有属性的列表:
如下实例:#!/usr/bin/python # -*- coding: UTF-8 -*- # 打开一个文件 fo = open("foo.txt", "wb") print "文件名: ", fo.name print "是否已关闭 : ", fo.closed print "访问模式 : ", fo.mode print "末尾是否强制加空格 : ", fo.softspace以上实例输出结果:
文件名: foo.txt 是否已关闭 : False 访问模式 : wb 末尾是否强制加空格 : 0close()方法
File 对象的 close()方法刷新缓冲区里任何还没写入的信息,并关闭该文件,这之后便不能再进行写入。
当一个文件对象的引用被重新指定给另一个文件时,Python 会关闭之前的文件。用 close()方法关闭文件是一个很好的习惯。
语法:fileObject.close();例子:
#!/usr/bin/python # -*- coding: UTF-8 -*- # 打开一个文件 fo = open("foo.txt", "wb") print "文件名: ", fo.name # 关闭打开的文件 fo.close()以上实例输出结果:
文件名: foo.txt读写文件:
file对象提供了一系列方法,能让我们的文件访问更轻松。来看看如何使用read()和write()方法来读取和写入文件。write()方法
write()方法可将任何字符串写入一个打开的文件。需要重点注意的是,Python字符串可以是二进制数据,而不是仅仅是文字。
write()方法不会在字符串的结尾添加换行符(‘\n’):
语法:
fileObject.write(string);在这里,被传递的参数是要写入到已打开文件的内容。
例子:#!/usr/bin/python # -*- coding: UTF-8 -*- # 打开一个文件 fo = open("foo.txt", "wb") fo.write( "www.runoob.com!\nVery good site!\n"); # 关闭打开的文件 fo.close()上述方法会创建foo.txt文件,并将收到的内容写入该文件,并最终关闭文件。如果你打开这个文件,将看到以下内容:
$ cat foo.txt www.runoob.com! Very good site!`read()方法
read()方法从一个打开的文件中读取一个字符串。需要重点注意的是,Python字符串可以是二进制数据,而不是仅仅是文字。
语法:
fileObject.read([count]);在这里,被传递的参数是要从已打开文件中读取的字节计数。该方法从文件的开头开始读入,如果没有传入count,它会尝试尽可能多地读取更多的内容,很可能是直到文件的末尾。
例子:
这里我们用到以上创建的 foo.txt 文件。
#!/usr/bin/python # -*- coding: UTF-8 -*- # 打开一个文件 fo = open("foo.txt", "r+") str = fo.read(10); print "读取的字符串是 : ", str # 关闭打开的文件 fo.close()以上实例输出结果:
读取的字符串是 : www.runoob


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









