







目录
- 前言
- 回顾prometheus架构图
- 说明
- 下载 kube-prometheus 安装包
- 暴露Prometheus的svc端口
- 修改Prometheus的容器时间-失败了
- 访问prometheus
- 访问grafana、dashboard N/A问题排查思路
- 两个Prometheus容器是什么关系,高可用?
- 什么是kube-state-metrics
- 配置prometheus、grafana数据持久化
- 问题处理
- 卸载kube-prometheus
- 解读servicemonitors资源
- 创建servicemonitors,实现自定义监控
- 手动访问k8s组件的metrics接口
- prometheus的配置文件
- 了解普罗米修斯的服务发现
- 告警规则
- 二进制部署Prometheus和kube-promethus对比
前言
环境:centos7.9、k8s-v1.22.6、kube-prometheus-release-0.10.zip
回顾prometheus架构图
我们来回顾一下prometheus的架构:
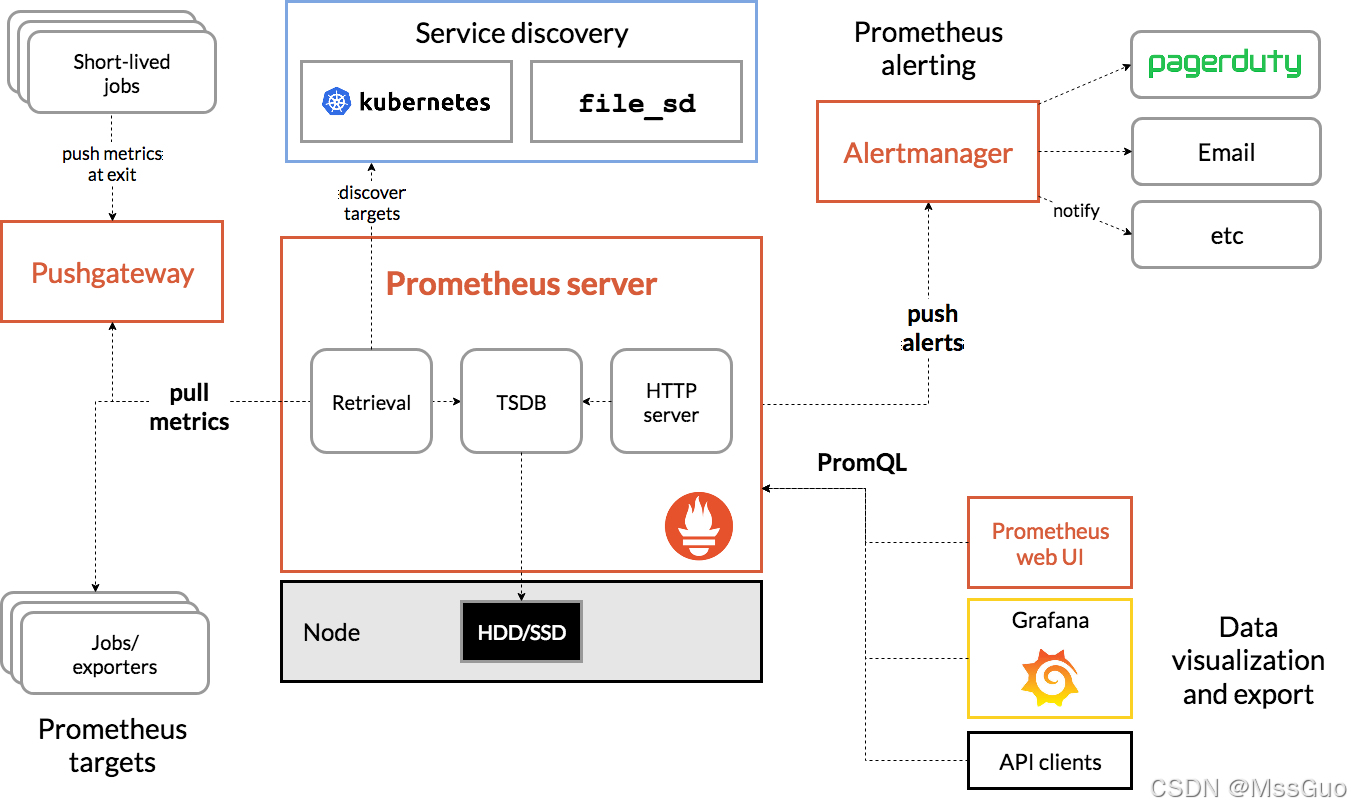
我们来解读一下prometheus 的架构图:
1、prometheus server是最重要的核心部分,它使用一个叫做TSDB的数据库(时间序列数据库)作为存储。
2、时间序列数据 (TimeSeries Data) : 按照时间顺序记录系统、设备状态变化的数据被称为时序数据 。
3、prometheus 可以有两种方式获取数据,一种是主动拉取数据,即pull拉取目标对象的数据指标,另外一种是在目标主机上编写采集脚本,将数据推送给pushgateway,pushgateway将数据推送给Prometheus Server。大多数情况下我们推荐prometheus 使用pull主动拉取数据的方式,这样可以减轻目标主机的业务负担,把负担交给prometheus server。
4、prometheus server要拉取哪些目标主机的数据呢,我们即可以在prometheus server中静态的配置指定要拉取的目标主机,也可以使用prometheus 的自动服务发现功能来自动获取目标主机,在k8s中就会使用服务发现机制来自动配置目标主机。
5、prometheus 获取到了指标数据,需要定义告警规则,然后根据构建规则产生告警,prometheus 会将告警推送给altermanager(在prometheus 的配置文件中定义有altermanager的主机IP地址端口),由altermanager发送告警信息给邮箱、钉钉、微信等通信工具。
6、prometheus 的web UI并不是十分漂亮,所以需要一个友好展示数据的图形化界面,grafana就是用于展示数据的,grafana通过获取prometheus server的数据来展示友好的图形化页面。
说明
我们采用prometheus-operator的方式在k8s集群上安装prometheus监控软件,这个项目的软件在GitHub上面;

github 上 coreos 下有两个项目:kube-prometheus 和 prometheus-operator,两者都可以实现 prometheus 的创建及管理。
需要注意的是,kube-prometheus 上的配置操作也是基于 prometheus-operator 的,并提供了大量的默认配置,故这里使用的是 kube-prometheus 项目的配置。
另外使用前需注意 k8s 版本要求,找到对应的 kube-prometheus 版本。

下载 kube-prometheus 安装包
去https://github.com/prometheus-operator/kube-prometheus/tree/release-0.10下载 kube-prometheus-release-0.10.zip压缩包,上传到服务器。
mkdir /root/kube-prometheus
cd /root/kube-prometheus
unzip kube-prometheus-release-0.10.zip
cd /root/kube-prometheus/kube-prometheus-release-0.10
#查看这些yaml文件需要哪些镜像
find ./manifests -type f | xargs grep 'image: '|sort|uniq |awk '{print $3}'|grep ^[a-zA-Z]grep -Evw
quay.io/prometheus/alertmanager:v0.23.0
jimmidyson/configmap-reload:v0.5.0
quay.io/brancz/kube-rbac-proxy:v0.11.0
quay.io/prometheus/blackbox-exporter:v0.19.0
grafana/grafana:8.3.3
k8s.gcr.io/kube-state-metrics/kube-state-metrics:v2.3.0
quay.io/brancz/kube-rbac-proxy:v0.11.0
quay.io/brancz/kube-rbac-proxy:v0.11.0
quay.io/prometheus/node-exporter:v1.3.1
k8s.gcr.io/prometheus-adapter/prometheus-adapter:v0.9.1
quay.io/brancz/kube-rbac-proxy:v0.11.0
quay.io/prometheus-operator/prometheus-operator:v0.53.1
quay.io/prometheus/prometheus:v2.32.1
# 可以先下载镜像,发现其中有2个镜像一直拉取不下来,所以找了下面的方法解决:
# 失败的镜像
k8s.gcr.io/prometheus-adapter/prometheus-adapter:v0.9.1
k8s.gcr.io/kube-state-metrics/kube-state-metrics:v2.3.0
# 平替镜像
docker pull lbbi/prometheus-adapter:v0.9.1
docker pull bitnami/kube-state-metrics:latest
# 下载不下来的镜像可以尝试加 m.daocloud.io,如 m.daocloud.io/k8s.gcr.io/prometheus-adapter/prometheus-adapter:v0.9.1
# 打标签替换
docker tag lbbi/prometheus-adapter:v0.9.1 k8s.gcr.io/prometheus-adapter/prometheus-adapter:v0.9.1
docker tag bitnami/kube-state-metrics:latest k8s.gcr.io/kube-state-metrics/kube-state-metrics:v2.3.0
#正式安装
kubectl apply --server-side -f manifests/setup
kubectl wait \
--for condition=Established \
--all CustomResourceDefinition \
--namespace=monitoring
kubectl apply -f manifests/
# 解读
# manifests/setup/目录下是创建monitoring命名空间和创建自定义资源CRD的yaml资源清单文件
# manifests/目录下有大量的yaml文件,这些文件就是用于创建prometheus组件的,如sts/deloyment/servicemonitors/svc/alertmanagers/prometheusrules等待资源文件
#--server-side选项告诉Kubernetes在服务器端执行操作,而不是在客户端,通常用于确保集群状态与配置文件一致
#kubectl wait 命令等待所有CustomResourceDefinition资源在指定的monitoring命名空间中达到Established状态
暴露Prometheus的svc端口
安装好prometheus的service是ClusterIP类型,所以为了能从外网访问,这里简单的修改为NodePort类型(生产环境根据实际情况将端口暴露出去),然后从浏览器访问:
# 修改svc类型为NodePort
kubectl -n monitoring edit svc prometheus-k8s
kubectl -n monitoring edit svc grafana
kubectl -n monitoring edit svc alertmanager-main
#查看service暴露的NodePort端口:
kubectl -n monitoring get svc | grep -i nodeport
修改Prometheus的容器时间-失败了
启动后的prometheus-k8s-0、prometheus-k8s-1容器内部的时间是不正确的,需要修改为服务器时间:
#在线编辑sts
kubectl -n monitoring edit sts prometheus-k8s
containers:
- name: mycontainer
image: myimage
volumeMounts:
- mountPath: /etc/localtime # 添加一个挂载点
name: localtime
volumes:
- name: localtime #追加一个挂载卷
hostPath:
path: /etc/localtime
type: File
# 重启pod
kubectl -n monitoring delete pod prometheus-k8s-0
kubectl -n monitoring delete pod prometheus-k8s-1
# 发现statefulset设置localtime挂载卷之后,又被还原了,应该是叫k8s的这种自定义资源prometheus还原的,因为就是它控制的statefulset。
# 这里不知道怎么修改容器时间了。
访问prometheus
http://192.168.118.133:32539 #访问prometheus
http://192.168.118.133:31757 #访问grafana,默认已经监控起来k8s集群了,默认账号密码 admin/admin
http://192.168.118.133:31206 #访问alertmanager
访问grafana、dashboard N/A问题排查思路
浏览器访问grafana: http://192.168.118.133:31757 admin/admin
左侧方格图标-Browse-Default目录下已经内置了很多dashboard。都可以直接使用。
如果发现没有自己想要的dashboard,可以去grafan官网下载:https://grafana.com/grafana/dashboards
比如,默认安装好的kube-promethus的granfan没有kube-state-metrics的监控面板,则去https://grafana.com/grafana/dashboards上搜索
kube-state-metrics,然后下载JSON文件,在grafana页面上导入即可。这里在线导入17519这个dashboardID即可。
同理,当需要redis、mysql的监控面板都可以去官网下载并在grafana导入。
# 问题排查-思路
当我们导入一个redis dashboard了,然后某个数据是N/A,表示数据空,这肯定存在问题,可以编辑这个panel查看其具体的PromQL表达式是什么,然
后将表达式复制粘贴到Prometheus的web页面上执行,查看是否有数据,同时,要确定是否存在这个指标,可能你下载的redis dashboard写的指标在你
的redis版本中就不存在或名字存在差异,所以肯定获取不到数据了。
去到服务器上curl redis-exporter-IP:9014/metrics | grep '指标' 实际看一下该指标是否存在或有数值.
就是这样排查问题的啦
两个Prometheus容器是什么关系,高可用?
我们发现,部署完成之后,创建了两个Prometheus实例,就是prometheus-k8s-0、prometheus-k8s-1两个容器,但是这两个容器是什么关系呀?看yaml清单文件,看statefulset的容器启动命令,既没有发现存在主从、主备的关系,也没有发现什么高可以的关系,好像两个prometheus-k8s-0、prometheus-k8s-1是单独的实例,因为他们都有各自的PVC。所以,他两到底啥啥关系?
# 测试验证
# 先设置全部节点不可调度
kubectl cordon master
kubectl cordon node1
kubectl cordon node2
# 删掉prometheus-k8s-1容器,此时prometheus-k8s-1 pod再拉起来已经处于penging状态
kubectl -n monitoring delete pod prometheus-k8s-1
# master节点模拟高负载
cat > TestCpu.java <<'EOF'
public class TestCpu {
public static void main(String[] args) {
cpu();
}
private static void cpu(){
while (true) {
System.out.println("66666");
}
}
}
EOF
java TestCpu.java
# 登录grafana,设置查询时间范围为一小时,观察master节点负载情况并截图记录
# 将master设置为可调度,此时prometheus-k8s-1 pod将会被创建
kubectl uncordon master
#将master设置为不可调度
kubectl cordon master ;
# 删除 prometheus-k8s-0 pod,此时只剩下 prometheus-k8s-1 pod正常运行了
kubectl -n monitoring delete pod prometheus-k8s-0
# master节点模拟高负载
java TestCpu.java
# 登录grafana,设置查询时间范围为一小时,观察master节点负载情况并与上一步的截图做对比
# 我们发现,同一个时间点的时候,两次负载的情况是不一样
# 这说明底层是两个不用的TSDB,所以应该可以说明prometheus-k8s-0、prometheus-k8s-0是完全两个不同的Prometheus实例。
什么是kube-state-metrics
当部署了kube-prmoethus之后,我们发现存在一个kube-state-metrics 这种pod,这个pod是干啥的呢? 和我们以前的metrics-server一样吗?
答:kube-state-metrics 是用来暴露k8s集群整体的数据指标的,让Prometheus可以对k8s集群进行监控,比如pod的数量,命名空间个数,k8s集群的信息CPU,内容容量等等这些信息的。而我们以前部署的metrics-server是给命令行kubectl top使用的。所以这两种是不相同的。
#通过curl kube-state-metrics pod的IP接口可以拿到指标数据
curl -s -k -H "Authorization: Bearer $token" https://10.244.0.48:8443/metrics
kube-state-metrics : 它通过查询 Kubernetes 的 API 服务器,收集关于 Kubernetes 中各种资源(如节点、pod、服务等)的状态信息,并将这些信息转换成 Prometheus 可以使用的指标
kube-state-metrics 主要功能:
节点状态信息:如节点 CPU 和内存的使用情况、节点状态、节点标签等
Pod 的状态信息,如 Pod 状态、容器状态、容器镜像信息、Pod 的标签和注释等
Deployment、Daemonset、Statefulset 和 ReplicaSet 等控制器的状态信息,如副本数、副本状态、创建时间等
Service 的状态信息,如服务类型、服务 IP 和端口等
存储卷的状态信息,如存储卷类型、存储卷容量等
Kubernetes 的 API 服务器状态信息,如 API 服务器的状态、请求次数、响应时间等
所以,简单一句话,那就是 kube-state-metrics用于暴露k8s集群状态信息的,这些信息数据指标将会被Prometheus 抓取,用于Prometheus 对 Kubernetes 集群进行监控,发现问题,以及提前预警。
配置prometheus、grafana数据持久化
参考另一篇文章:https://blog.csdn.net/MssGuo/article/details/127891331
prometheus数据持久化
[root@matser manifests]# kubectl get pods -n monitoring
NAME READY STATUS RESTARTS AGE
........................
prometheus-k8s-0 2/2 Running 0 68m #这个就是真正在跑prometheus-server的pod
prometheus-k8s-1 2/2 Running 0 68m #这个就是真正在跑prometheus-server的pod
#由此知prometheus的主服务其实就是使用pod启动的,其实就是prometheus-k8s-0、prometheus-k8s-1
[root@matser manifests]# kubectl get sts -n monitoring
NAME READY AGE
alertmanager-main 3/3 69m
prometheus-k8s 2/2 69m #这个
# 但是我们查了一遍,发现当初创建kube-prometheus的yaml文件里面并没有创建StatefulSet资源,很奇怪。
# 后来百度发现,其实官方定义了一种叫做prometheus的资源,该资源创建了StatefulSet,如下:
[root@matser manifests]# kubectl get prometheus -n monitoring
NAME VERSION REPLICAS AGE
k8s 2.32.1 2 71m #这种prometheus资源,由其创建的sts,创建k8s资源的文件是prometheus-prometheus.yaml
[root@matser manifests]#
# prometheus-server 默认情况下没有配置数据持久化。所以我们需要做持久化存储。
#在线修改prometheus这种类型的资源,名称叫k8s(当然,你也可以修改prometheus-prometheus.yaml然后在apply亦可)
[root@matser manifests]# kubectl edit prometheus k8s -n monitoring
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
.....................
replicas: 2
resources:
requests:
memory: 400Mi
retention: 15d #加这个参数,表示prometheus数据保留的天数,默认会是1天而已
ruleNamespaceSelector: {}
............
serviceMonitorNamespaceSelector: {}
serviceMonitorSelector: {}
storage: #加上下面这一段,一共9句
volumeClaimTemplate:
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 50M
storageClassName: nfs-storageclass #指定已有的存储类名称
version: 2.32.1
[root@matser manifests]#
# 查看pvc,pv都创建好了
kubectl get pvc,pv -n monitoring
grafana的数据持久化
[root@matser ~]# kubectl get deploy -n monitoring
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/grafana 1/1 1 1 110m
#以上我们看到使用deployment部署了grafana,只有一个pod。
#手动创建grafana的pvc
[root@matser manifests]# cat > grafana-pvc.yaml <<'EOF'
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: grafana-pvc
namespace: monitoring
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 100M
storageClassName: nfs-storageclass
EOF
kubectl apply -f grafana-pvc.yaml
kubectl get pvc -n monitoring | grep grafana
kubectl get pv | grep grafana
#编辑grafana的yaml文件,当然你可以在线edit它
[root@matser manifests]# vim grafana-deployment.yaml
volumes:
# - emptyDir: {} #注释或删掉
# name: grafana-storage #注释或删掉
- name: grafana-storage #注意名字要和上面那句的名称相同
persistentVolumeClaim:
claimName: grafana-pvc #指定我们刚才创建的pvc
- name: grafana-datasources #这个原来的,不管
secret:
secretName: grafana-datasources
# 可以不做下面这一步,因为上面持久化之后不会丢失密码的变更
#为了固定grafana的登陆密码,可以添加环境变量
readinessProbe:
httpGet:
path: /api/health
port: http
env: #添加环境变量
- name: GF_SECURITY_ADMIN_USER #添加环境变量
value: admin #添加环境变量
- name: GF_SECURITY_ADMIN_PASSWORD #添加环境变量
value: admin #添加环境变量
resources:
limits:
cpu: 200m
memory: 200Mi
kubectl replace -f grafana-deployment.yaml
问题处理
访问下面这个url,发现没有kube-controller-manager和kube-schedule 。

进入我们的http://192.168.118.133:31757 ,访问grafana,发现grafana也是没有监控到kube-controller-manager和kube-schedule 这两个集群组件。

解决prometheus没有监控到kube-controller-manager和kube-schedule的问题
原因分析:
和prometheus定义的ServiceMonitor的资源有关。
我们查看安装目录下的资源清单文件,kube-scheduler组件对应的资源清单发现:
#进入到我们安装prometheus的目录下
[root@master ~]# cd /root/kube-prometheus/kube-prometheus-release-0.10/manifests
#查看这个kubernetesControlPlane-serviceMonitorKubeScheduler.yaml资源清单
# 这种prometheus自定义资源ServiceMonitor类型,其标签选择器是一个svc
[root@master manifests]# cat kubernetesControlPlane-serviceMonitorKubeScheduler.yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
app.kubernetes.io/name: kube-scheduler
app.kubernetes.io/part-of: kube-prometheus
name: kube-scheduler
namespace: monitoring
spec:
endpoints:
- bearerTokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token
interval: 30s
port: https-metrics
scheme: https
tlsConfig:
insecureSkipVerify: true
jobLabel: app.kubernetes.io/name
namespaceSelector: #命名空间选择器
matchNames:
- kube-system
selector: #标签选择器
matchLabels:
app.kubernetes.io/name: kube-scheduler
#发现上面定义的命名空间下的标签选择器,根本就没有匹配的上的对应的svc
[root@master manifests]# kubectl get svc -l app.kubernetes.io/name=kube-scheduler -n kube-system
No resources found in kube-system namespace. #没有svc资源匹配的上
[root@master manifests]#
#我们再来查看对应的controller-manager资源清单看看,也是同样的问题,没有svc资源匹配的上
[root@master manifests]# tail kubernetesControlPlane-serviceMonitorKubeControllerManager.yaml
scheme: https
tlsConfig:
insecureSkipVerify: true
jobLabel: app.kubernetes.io/name
namespaceSelector:
matchNames:
- kube-system
selector:
matchLabels:
app.kubernetes.io/name: kube-controller-manager
#发现根本就没有对应的service
[root@master manifests]# kubectl get svc -l app.kubernetes.io/name=kube-controller-manager -n kube-system
No resources found in kube-system namespace.
[root@master manifests]#
解决办法:手动创建对应的svc,让prometheus定义的ServiceMonitor资源有对应的service,而service又通过标签选择器关联着pod
#所以现在我们需要主动给它创建一个svc来让他能监控到kube-scheduler
[root@master ~]# cd /root/kube-prometheus/kube-prometheus-release-0.10/manifests/repair-prometheus
[root@master repair-prometheus]# cat kubeSchedulerService.yaml
apiVersion: v1
kind: Service
metadata:
labels: #定义这个service的标签,因为kubernetesControlPlane-serviceMonitorKubeScheduler.yaml里面定义了这个标签
app.kubernetes.io/name: kube-scheduler
name: kube-scheduler
namespace: kube-system #名称空间是kube-system
spec:
selector: #这个标签选择器表示我们要关联到kube-scheduler的pod上
component: kube-scheduler # kubectl get pods kube-scheduler-master -n kube-system --show-labels
ports:
- name: https-metrics #service端口名称,这个名称要与ServiceMonitor的port名称一致
port: 10259
targetPort: 10259 #kube-scheduler-master的端口
[root@master repair-prometheus]#
#同理,我们也需要主动给它创建一个svc来让他能监控到controller-manager
[root@master repair-prometheus]# cat kubeControllermanagerService.yaml
apiVersion: v1
kind: Service
metadata:
labels: #定义这个service的标签,因为kubernetesControlPlane-serviceMonitorKubeControllerManager.yaml里面定义了这个标签
app.kubernetes.io/name: kube-controller-manager
name: kube-controller-manager
namespace: kube-system #名称空间是kube-system
spec:
selector: #这个标签选择器表示我们要关联到kube-controller-manager-master的pod上
component: kube-controller-manager #kubectl get pods kube-controller-manager-master -n kube-system --show-labels
ports:
- name: https-metrics #service端口名称,这个名称要与ServiceMonitor的port名称一致
port: 10257
targetPort: 10257 # kube-controller-manager-master的pod的端口
[root@master repair-prometheus]#
# 创建上面两个service
[root@master repair-prometheus]# kubectl apply -f kubeSchedulerService.yaml -f kubeControllermanagerService.yaml
创建service之后,我们发现grafana的界面还是没有监控到Scheduler和Controllermanager服务,还有一步:
#还有一点,kube-scheduler-master和kube-controller-manager这2个pod启动的时候默认绑定的地址是127.0.0.1,所以普罗米修斯通过ip去访问
# 就会被拒绝,所以需要修改一下,我们知道这2个系统组件是是以静态pod的方式启动的,所以进入到master节点的静态pod目录
# 如果我们不指定静态pod目录时在哪里,可以通过kubelet查看
[root@master manifests]# systemctl status kubelet.service | grep '\-\-config'
└─429488 /usr/bin/kubelet --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf --config=/var/lib/kubelet/config.yaml --network-plugin=cni --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.5
[root@master manifests]# grep static /var/lib/kubelet/config.yaml
staticPodPath: /etc/kubernetes/manifests #这就是静态pod的目录
[root@master manifests]#
[root@master ~]# cd /etc/kubernetes/manifests
[root@master manifests]# grep 192 kube-scheduler.yaml
- --bind-address=192.168.118.131 #修改127.0.0.1为主机的ip,修改为0.0.0.0也行
host: 192.168.118.131 #其实保持默认127.0.0.1也行
host: 192.168.118.131 #其实保持默认127.0.0.1也行
[root@master manifests]#
[root@master manifests]# vim kube-controller-manager.yaml
- --bind-address=192.168.118.131 #修改127.0.0.1为主机的ip,修改为0.0.0.0也行
host: 192.168.118.131 #其实保持默认127.0.0.1也行
host: 192.168.118.131 #其实保持默认127.0.0.1也行
[root@master manifests]#
#发现修改后scheduler和controller-manager pod消失了,一直也没有重新创建pod
#所以重启kubelet后pod都正常了
[root@master manifests]# systemctl restart kubelet.service
现在查看grafana的界面已经监控到Scheduler和Controllermanager服务了。
卸载kube-prometheus
如果不需要kube-prometheus了直接delete掉对应的资源清单创建的资源即可:
[root@master ~]# cd /root/kube-prometheus/kube-prometheus-release-0.10/
[root@master ~]# kubectl delete -f manifests/
[root@master ~]# kubectl delete -f manifests/setup/
至此,所有的系统组件都已经被kube-prometheus监控起来的,kube-prometheus搭建完成。
解读servicemonitors资源
# 我们发现,kube-prometheus是通过定义一个叫ServiceMonitor的对象来实现监控的,而ServiceMonitor定义其对应的service,service又有endpoint,endpoint关联pod
# 这里以一个redis的servicemonitors为例做介绍
[root@dev-master ~]# kubectl -n monitoring get servicemonitors.monitoring.coreos.com redis-exporter -oyaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor # 这是kube-prometheus自定义CRD
metadata:
annotations:
meta.helm.sh/release-name: redis
meta.helm.sh/release-namespace: monitoring
labels:
app: redis-exporter
app.kubernetes.io/managed-by: Helm
name: redis-exporter
namespace: monitoring
spec:
endpoints: # endpoints定义端点
- interval: 60s # 采集时间,每个60s秒采集一次
path: /metrics # 采集的路径接口是/metrics
scrapeTimeout: 10s # 超时时间
targetPort: 9121 # service对应的目标端口
jobLabel: redis-exporter
namespaceSelector: #service命名空间选择器
matchNames:
- monitoring
selector: # 匹配哪个service
matchLabels:
app: redis-exporter
# 由此,我们解读一下这个ServiceMonitor,其含义是匹配monitoring命名空间中标签是app=redis-exporter的service的9121端口的/metrics接口
[root@dev-master ~]# kubectl -n monitoring get svc -l app=redis-exporter
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
redis-exporter ClusterIP 10.102.22.146 <none> 9121/TCP 99m
Prometheus默认创建了很多servicemonitoring,所以页面上默认就有很多targets 监控项了:
[root@master manifests]# kubectl -n monitoring get servicemonitors.monitoring.coreos.com
NAME AGE
alertmanager-main 4d4h
blackbox-exporter 4d4h
coredns 4d4h
grafana 4d4h
ingress-nginx 3d21h
kube-apiserver 4d4h
kube-controller-manager 4d4h
kube-scheduler 4d4h
kube-state-metrics 4d4h
kubelet 4d4h
node-exporter 4d4h
prometheus-adapter 4d4h
prometheus-k8s 4d4h
prometheus-operator 4d4h
创建servicemonitors,实现自定义监控
下面,我们举3例子来实现监控。
prometheus监控kube-proxy
我们发现prometheus默认没有监控kube-proxy,而且kube-proxy本身就暴露了数据指标接口。
这里我们可以参照上面的例子来手动创建servicemonitors来监控kube-proxy。
# 并没有kube-proxy的servicemonitors
kubectl -n monitoring get servicemonitors.monitoring.coreos.com
# 先查看kube-proxy的数据指标端口是什么
netstat -lntup| grep kube-proxy
tcp 0 0 127.0.0.1:10249 0.0.0.0:* LISTEN 4528/kube-proxy
tcp6 0 0 :::10256 :::* LISTEN 4528/kube-proxy
# 可以采集得到指标数据
curl -s http://127.0.0.1:10249/metrics | head -n 3
# 发现kube-proxy没有对应的service,则创建一个
cat > svc-kube-pxory.yaml <<'EOF'
apiVersion: v1
kind: Service
metadata:
name: kube-proxy
namespace: kube-system
spec:
ports:
- name: kube-proxy-port
port: 10249
protocol: TCP
targetPort: 10249
selector:
k8s-app: kube-proxy
type: ClusterIP
EOF
kubectl apply -f svc-kube-pxory.yaml
[root@master manifests]# kubectl -n kube-system get ep kube-proxy # 这里有问题,下面再说
NAME ENDPOINTS AGE
kube-proxy 192.168.118.140:10249,192.168.118.141:10249,192.168.118.142:10249 109s
[root@master manifests]# kubectl -n kube-system get svc kube-proxy
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-proxy ClusterIP 10.110.255.154 <none> 10249/TCP 112s
# 编写yaml资源清单,可以找一个servicemonitors过来改一下
cat > servicemonitor-kube-proxy.yaml <<'EOF'
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
app.kubernetes.io/name: kube-proxy
app.kubernetes.io/part-of: kube-prometheus
name: kube-proxy
namespace: monitoring
spec:
endpoints:
- bearerTokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token
interval: 30s
port: kube-proxy-port # 这个和service的端口名字保持一致
scheme: http
path: /metrics
jobLabel: app.kubernetes.io/name
namespaceSelector:
matchNames:
- kube-system
selector:
matchLabels:
app.kubernetes.io/name: kube-proxy
EOF
kubectl -n monitoring apply -f servicemonitor-kube-proxy.yaml
# 创建之后,Prometheus页面已经可以监控到kube-proxy了,
#但是存在问题,报错了
Get "http://192.168.118.140:10249/metrics": dial tcp 192.168.118.140:10249: connect: connection refused
# 我们发现IP都是宿主机的IP,拿这个url去服务器上访问,也访问不通。使用service的IP访问也是访问不通
#原因在于,kube-proxy 监听的是127.0.0.1端口,虽然kube-proxy 是使用demonset部署的,network: true,使用的是宿主机网络,
#但是kube-proxy监听的是宿主机的127.0.0.1 IP呀,而我们创建的ep对应的IP也都是主机的IP
#所以,现在问题就是怎么让kube-proxy的端口监听在宿主机网卡上,即让他端口监听在0.0.0.0上
[root@master manifests]# netstat -lntup| grep kube-proxy
tcp 0 0 127.0.0.1:10249 0.0.0.0:* LISTEN 4528/kube-proxy # 只监听在127.0.0.1
tcp6 0 0 :::10256 :::* LISTEN 4528/kube-proxy
[root@master manifests]# kubectl -n kube-system get ep kube-proxy
NAME ENDPOINTS AGE
kube-proxy 192.168.118.140:10249,192.168.118.141:10249,192.168.118.142:10249 92m
[root@master manifests]#
# 修改kube-proxy的配置文件
kubectl -n kube-system get cm kube-proxy -oyaml | grep -i address
bindAddress: 0.0.0.0 #通过查询我们发现,这个默认就是监听在0.0.0.0上,但是我们不是要修改这个
bindAddressHardFail: true
healthzBindAddress: ""
metricsBindAddress: "" # 我们要修改的是这个IP
nodePortAddresses: null
#在线编辑ConfigMap
kubectl -n kube-system edit cm kube-proxy
metricsBindAddress: "0.0.0.0" # 主要修改这个为0.0.0.0
#重启pod
kubectl -n kube-system rollout restart ds kube-proxy
[root@master ~]# netstat -lntup | grep proxy # 端口已经监听在0.0.0.0上了
tcp6 0 0 :::10249 :::* LISTEN 111980/kube-proxy
tcp6 0 0 :::10256 :::* LISTEN 111980/kube-proxy
[root@master ~]#
# 现在我们curl kube-proxy的service 的IP和指标接口,都正常了
# curl service的地址正常,那curl endpoints的IP地址端口肯定也都正常了
kubectl -n kube-system get svc kube-proxy
curl 10.110.255.154:10249/metrics
curl 192.168.118.140:10249/metrics
curl 192.168.118.141:10249/metrics
curl 192.168.118.142:10249/metrics
# 普罗米修斯页面也正常了
kube-prometheus监控nginx-ingress
nginx-ingress是k8s集群流量的入口,很重要,我们需要监控nginx-ingress,默认 kube-prometheus并没有监控nginx-ingress,而且nginx-ingress本身就暴露了数据指标接口,所以我们需要自己创建serviceMonitor监控nginx-ingress。
kubectl -n ingress-nginx get ds ingress-nginx-controller
kubectl -n ingress-nginx get pods
#通过查看yaml可以得知pod暴露10254这个指标端口
kubectl get pods ingress-nginx-controller-g7vmn -n ingress-nginx -oyaml
#curl pod端口10254暴露的指标,有输出一大堆内容
curl 192.168.118.132:10254/metrics
# 先创建一个ingress-nginx对应的service
#我们发现已经有对应的标签的service,但是这个service里面并没有定义targetPort是10254的端口
[root@master ~]# kubectl get svc -n ingress-nginx -l app.kubernetes.io/name=ingress-nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx-controller-admission ClusterIP 10.102.72.255 <none> 443/TCP 245d
# 添加targetPort是10254的端口
[root@master ~]# kubectl edit svc ingress-nginx-controller-admission -n ingress-nginx
ports:
- appProtocol: https
name: https-webhook
port: 443
protocol: TCP
targetPort: webhook
- name: metrics #追加这一段,表示在service上定义一个10245的端口,对应着pod的10245端口
port: 10254
protocol: TCP
targetPort: 10254
#验证通过service的10254端口能读取到metrics数据指标
curl 10.102.72.255:10254/metrics
#现在来创建servicemonitors来监控nginx-ingress
#创建nginx-ingress的servicemonitors
cat > servicemonitor-nginx-ingress.yaml <<'EOF'
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
app.kubernetes.io/name: ingress-nginx
name: ingress-nginx
namespace: monitoring
spec:
endpoints:
- path: /metrics # 数据指标接口
interval: 15s # 采集周期
port: metrics # 这个名字要和service的定义的端口名字保持一致
jobLabel: app.kubernetes.io/name
namespaceSelector: # 命名空间选择器,表示选择哪个命名空间的service
matchNames:
- ingress-nginx
selector: # service选择器,表示选择指定标签的service
matchLabels:
app.kubernetes.io/name: ingress-nginx
EOF
kubectl apply -f servicemonitor-nginx-ingress.yaml
创建完之后,我们发现prometheus页面上targets(http://192.168.118.131:32539/targets )里面还是没有显示nginx-ingress,查prometheus-k8s-0这个pod 看到报错:
#查看prometheus-k8s-0这个pod 看到报错了,forbidden权限不足
[root@master servicemonitor-nginx-ingress]# kubectl logs -n monitoring prometheus-k8s-0 -c prometheus
ts=2022-10-21T04:57:14.829Z caller=klog.go:116 level=error component=k8s_client_runtime func=ErrorDepth msg="pkg/mod/k8s.io/client-go@v0.22.4/tools/cache/reflector.go:167: Failed to watch *v1.Service: failed to list *v1.Service: services is forbidden: User \"system:serviceaccount:monitoring:prometheus-k8s\" cannot list resource \"services\" in API group \"\" in the namespace \"ingress-nginx\""
# 查看prometheus创建的集群角色
[root@master ~]# kubectl get clusterroles prometheus-k8s -oyaml
apiVersion: rbac.authorization.k8s.io/v1
........
rules: #默认权限太少了
- apiGroups:
- ""
resources:
- nodes/metrics
verbs:
- get
- nonResourceURLs:
- /metrics
verbs:
- get
# 修改集群角色的权限
[root@master ~]# kubectl edit clusterroles prometheus-k8s
rules: #添加权限
- apiGroups:
- ""
resources:
- nodes
- services
- endpoints
- pods
- nodes/proxy
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- configmaps
- nodes/metrics
verbs:
- get
- nonResourceURLs:
- /metrics
verbs:
- get
这是,我们发现prometheus页面上targets(http://192.168.118.131:32539/targets )有显示nginx-ingress了,说明已经监控起来了。
kube-prometheus监控redis主从
# 在若依命名空间中存在一个redis主从复制集群,我们需要使用kube-prometheus监控redis主从复制集群
[root@dev-master ~]# kubectl -n ruoyi get po -l app.kubernetes.io/instance=redis
NAME READY STATUS RESTARTS AGE
redis-master-0 1/1 Running 1 78d
redis-replicas-0 1/1 Running 2 78d
redis-replicas-1 1/1 Running 1 7d
redis-replicas-2 1/1 Running 1 78d
[root@dev-master ~]# kubectl -n ruoyi get svc -l app.kubernetes.io/name=redis
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
redis-headless ClusterIP None <none> 6379/TCP 106d
redis-master ClusterIP 10.109.12.23 <none> 6379/TCP 106d
redis-replicas ClusterIP 10.109.78.217 <none> 6379/TCP 106d
# 使用helm安装redis-exporter
helm repo add kubegemsapp https://charts.kubegems.io/kubegemsapp
helm repo update
helm pull kubegemsapp/prometheus-redis-exporter --version=4.7.4
tar xf prometheus-redis-exporter-4.7.4.tgz
cd prometheus-redis-exporter/
# 修改values.yaml文件
vim values.yaml
[root@dev-master prometheus-redis-exporter]# grep -Ev '#|$^' values.yaml
rbac:
create: false
pspEnabled: false
serviceAccount:
create: false
name:
replicaCount: 1
image:
repository: registry.cn-beijing.aliyuncs.com/kubegemsapp/redis_exporter
tag: v1.27.0
pullPolicy: IfNotPresent
nameOverride: redis-exporter
fullnameOverride: redis-exporter
extraArgs: {}
customLabels: {}
securityContext: {}
env: {}
service:
type: ClusterIP
port: 9121
annotations: {}
labels: {}
resources:
limits:
cpu: 100m
memory: 128Mi
requests:
cpu: 20m
memory: 64Mi
nodeSelector: {}
tolerations: []
affinity: {}
redisAddress: redis://redis-master.ruoyi.svc:6379 # 指定redis的命名空间,这里指定的是redis-master 的service
annotations: {}
labels: {}
redisAddressConfig:
enabled: false
configmap:
name: ""
key: ""
serviceMonitor:
enabled: true
interval: 60s
telemetryPath: /metrics
timeout: 10s
additionalLabels: {}
alerts:
enabled: true
auth:
enabled: true
secret:
name: "redis" # 这里设置redis的secret名称
key: "redis-password" #redis的secret的key名字
redisPassword: "password"
[root@dev-master prometheus-redis-exporter]#
# 上面我们设置了redis的secret,由于是在ruoyi命名空间的,所以需要添加过来
kubectl -n ruoyi get secrets redis -oyaml > redis-secrets.yaml
vim redis-secrets.yaml # 修改命名空间为monitoring
kubectl -n monitoring create -f redis-secrets.yaml
# 部署redis-exporter,这里将资源都放在monitoring 命名空间方便管理,当然也可以放在任意命名空间
helm -n monitoring template redis-exporter ./
helm -n monitoring install redis-exporter ./
kubectl -n monitoring get po redis-exporter-75ccfb99cf-v4644 -owide
kubectl -n monitoring logs redis-exporter-75ccfb99cf-v4644
# 使用curl命令直接查看pod ID的指标
curl 10.244.0.83:9121/metrics
# 最后在prometheus server 中targets栏已经看到redis-exporter了,然后在grafana导入模板即可
# 那么,我们很好奇,就部署了redis-exporter的pod就能采集redis的指标了,前面采集k8s组件的时候不是说要创建servicemonitors的吗
# 仔细观察你可以发现,其实在安装时已经帮我们部署了很多普罗米修斯的资源,如ServiceMonitor、PrometheusRule
helm -n monitoring template redis-exporter ./
#以前我们的k8s组件默认就暴露了metrics接口,但是我们自己的应用,如一些中间件redis,mysql等就需要使用exporter的形式暴露metrics接口了
# 采集k8s组件数据指标流程
prometuhs -> servicemonitor -> service -> enpoints -> kube-peoxy pod(本身暴露了指标接口)
# 采集中间件数据指标流程
prometuhs -> servicemonitor -> service -> enpoints -> redis-exporter(部署一个redis-exporter暴露redis指标接口) ->redis pod
[root@master ~]# kubectl -n monitoring get po redis-exporter-75ccfb99cf-rgtrx -owide
NAME READY STATUS RESTARTS AGE IP NODE
redis-exporter-75ccfb99cf-rgtrx 1/1 Running 0 12m 10.244.1.65 node2
# 自动创建了servicemonitors
[root@master ~]# kubectl -n monitoring get servicemonitors.monitoring.coreos.com redis-exporter
NAME AGE
redis-exporter 13m
[root@master ~]# kubectl -n monitoring get service redis-exporter
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
redis-exporter ClusterIP 10.107.26.231 <none> 9121/TCP 13m
[root@master ~]# kubectl -n monitoring get ep redis-exporter
NAME ENDPOINTS AGE
redis-exporter 10.244.1.65:9121 13m
# 可以看到,整体的工作流程是这样的
servicemonitor关联了一个service,而service关联着enpoints,endpoint对应的后端pod IP和端口就是redis-exporter 这个pod的IP和端口,redis-exporter本身就是采集redis数据指标的,它的yaml里面定义了要采集的redis的地址。就是这样。
手动访问k8s组件的metrics接口
我们手动访问k8s组件的metrics接口。
[root@master setup]# curl -k https://192.168.118.140:10259/metrics
{
"kind": "Status",
"apiVersion": "v1",
"metadata": {
},
"status": "Failure",
"message": "forbidden: User \"system:anonymous\" cannot get path \"/metrics\"",
"reason": "Forbidden",
"details": {
},
"code": 403
}[root@master setup]#
# 默认是需要进行认证访问的
# 那么怎么进行认证呢?
#在k8s中,可以通过证书,也可以通过token的方式进行认证和访问。
#那么,这个token,从哪里来呢?
#就涉及到一个概念,在k8s里面的概念,就是权限的问题,比如clusterrole和serviceaccount的概念。
#serviceaccount是k8s里的用户的概念,只要seviceaccount有访问node资源的权限,就可以获取对应的资源的信息了
# 可以从prometheus创建的sa中得到token
kubectl -n monitoring get sa prometheus-k8s -oyaml
kubectl -n monitoring get secrets prometheus-k8s-token-27mlq -oyaml
[root@master ~]# kubectl -n monitoring get secrets prometheus-k8s-token-27mlq -oyaml
apiVersion: v1
data:
.......
token: ZXlKaGJHY2lPaUpTVXp...................pZdmlkOUpVRFhWSkVB
kind: Secret
# token 是加密的,需要解密
echo "ZXlKaGJHY2lPaUpTVXp....................pZdmlkOUpVRFhWSkVB" | base64 -d
# 定义一个token变量,值就是解密的内容
export token=解密的字符
# 访问metrics,这时就正常了
curl -s -k -H "Authorization: Bearer $token" https://192.168.118.140:10259/metrics
# 直接这样也可以,注意tr -d是故意换了一行的,表示字符串内容要去掉换行符,直接复制粘贴执行即可
token=$(kubectl -n monitoring get secrets prometheus-k8s-token-27mlq -oyaml | grep 'token:' | awk '{print $2}' | tr -d '
' | base64 -d )
curl -s -k -H "Authorization: Bearer $token" https://192.168.118.140:10259/metrics
prometheus的配置文件
以前二进制部署的prometheus的配置文件名字叫做prometheus.yaml,现在我们使用kube-prometheus部署的prometheus,我们在页面上也可以看到其配置文件:
# 查看sts
kubectl -n monitoring get sts prometheus-k8s -oyaml > prometheus-k8s.yaml
# 我们精简出一些重要信息
vim prometheus-k8s.yaml
serviceName: prometheus-operated
template:
metadata:
spec:
containers:
- args:
- --web.console.templates=/etc/prometheus/consoles
- --web.console.libraries=/etc/prometheus/console_libraries
- --config.file=/etc/prometheus/config_out/prometheus.env.yaml
- --storage.tsdb.path=/prometheus
- --storage.tsdb.retention.time=15d
- --web.enable-lifecycle
- --web.route-prefix=/
- --web.config.file=/etc/prometheus/web_config/web-config.yaml
image: quay.io/prometheus/prometheus:v2.32.1
name: prometheus # 这是主容器
ports:
- containerPort: 9090 #主容器端口9090
name: web
volumeMounts:
- mountPath: /etc/prometheus/config_out
name: config-out
readOnly: true
- mountPath: /etc/prometheus/certs
name: tls-assets
readOnly: true
- mountPath: /prometheus # 数据库挂载点,pvc存储
name: prometheus-k8s-db
subPath: prometheus-db
- mountPath: /etc/prometheus/rules/prometheus-k8s-rulefiles-0
name: prometheus-k8s-rulefiles-0
- mountPath: /etc/prometheus/web_config/web-config.yaml
name: web-config
readOnly: true
subPath: web-config.yaml
- args:
- --listen-address=:8080 # 边车容器的端口
- --reload-url=http://localhost:9090/-/reload
- --config-file=/etc/prometheus/config/prometheus.yaml.gz # 这个就是普罗米修斯的主配置文件
- --config-envsubst-file=/etc/prometheus/config_out/prometheus.env.yaml
- --watched-dir=/etc/prometheus/rules/prometheus-k8s-rulefiles-0
command:
- /bin/prometheus-config-reloader
env:
- name: POD_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.name
- name: SHARD
value: "0"
image: quay.io/prometheus-operator/prometheus-config-reloader:v0.53.1
name: config-reloader # 这是一个配置文件动态加载的边车容器
ports:
- containerPort: 8080
name: reloader-web
volumeMounts:
- mountPath: /etc/prometheus/config
name: config
- mountPath: /etc/prometheus/config_out
name: config-out
- mountPath: /etc/prometheus/rules/prometheus-k8s-rulefiles-0
name: prometheus-k8s-rulefiles-0
initContainers:
- args:
- --watch-interval=0
- --listen-address=:8080
- --config-file=/etc/prometheus/config/prometheus.yaml.gz
- --config-envsubst-file=/etc/prometheus/config_out/prometheus.env.yaml
- --watched-dir=/etc/prometheus/rules/prometheus-k8s-rulefiles-0
command:
- /bin/prometheus-config-reloader
env:
- name: POD_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.name
- name: SHARD
value: "0"
image: quay.io/prometheus-operator/prometheus-config-reloader:v0.53.1
imagePullPolicy: IfNotPresent
name: init-config-reloader
ports:
- containerPort: 8080
name: reloader-web
protocol: TCP
volumeMounts:
- mountPath: /etc/prometheus/config
name: config
- mountPath: /etc/prometheus/config_out
name: config-out
- mountPath: /etc/prometheus/rules/prometheus-k8s-rulefiles-0
name: prometheus-k8s-rulefiles-0
volumes:
- name: config
secret:
defaultMode: 420
secretName: prometheus-k8s #普罗米修斯的主配置文件
- name: tls-assets
projected:
defaultMode: 420
sources:
- secret:
name: prometheus-k8s-tls-assets-0
- emptyDir: {}
name: config-out
- configMap:
defaultMode: 420
name: prometheus-k8s-rulefiles-0
name: prometheus-k8s-rulefiles-0
- name: web-config
secret:
defaultMode: 420
secretName: prometheus-k8s-web-config
# 从上面的yaml文件中我们可以看到,普罗米修斯主容器并没有直接使用配置文件,而是使用一个config-reloader的边车容器来动态加载配置文件
# 而且配置文件都是使用secret卷挂载的
# 我们查看prometheus-k8s secret卷,发现这是一个压缩文件,还是加密的,看不出什么内容
[root@master setup]# kubectl -n monitoring get secrets prometheus-k8s -oyaml
apiVersion: v1
data:
prometheus.yaml.gz: H4sIAAAAAA.....sAAA==
kind: Secret
metadata:
name: prometheus-k8s
namespace: monitoring
......
type: Opaque
[root@master setup]#
# 我们进入边车容器里面查看
[root@master setup]# kubectl -n monitoring exec -it prometheus-k8s-0 -c config-reloader -- sh
/ $ cd /etc/prometheus/config
/etc/prometheus/config $ ls -lrth
total 0
lrwxrwxrwx 1 root 2000 25 Sep 27 04:33 prometheus.yaml.gz -> ..data/prometheus.yaml.gz
/etc/prometheus/config $ cd ..data/
/etc/prometheus/config/..2024_09_27_04_33_35.075698414 $ ls -lrth
total 4K
-rw-r--r-- 1 root 2000 3.1K Sep 27 04:33 prometheus.yaml.gz
/etc/prometheus/config/..2024_09_27_04_33_35.075698414 $ pwd
/etc/prometheus/config/..data
[root@master setup]# 我们把文件拷贝出来看看
kubectl -n monitoring cp prometheus-k8s-0:/etc/prometheus/config/..2024_09_27_04_33_35.075698414/prometheus.yaml.gz -c config-reloader ./prometheus.yaml.gz
[root@master setup]# ll # 发现这是一个gz文件
-rw-r--r-- 1 root root 3205 Sep 27 13:04 prometheus.yaml.gz
[root@master setup]# 解压gz文件
[root@master setup]# gunzip prometheus.yaml.gz # 解压后默认删除了源文件,得到prometheus.yaml文件
[root@master setup]# vim prometheus.yaml # 这个问内容就是普罗米修斯的配置文件,就是我们在页面上看到的配置文件内容
了解普罗米修斯的服务发现
我们回顾一下,以前在Linux上部署二进制的Prometheus,其配置文件是这样的:
参考:https://blog.csdn.net/MssGuo/article/details/122402074
cd /usr/local/prometheus-2.5.0.linux-amd64
#编辑主配置文件,添加一个客户端的配置
vim prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
- job_name: 'client1' #复制一个job_name的标签,与上面那个job_name对其,client1是job_name,可自定义
static_configs:
- targets: ['192.168.118.135:9100'] #填写客户端的IP和node_export的端口
#注意:普罗米修斯的配置文件时yml格式的,yml语法标签对齐,空格等都要非常严格的语法
#关闭prometheus服务
kill -9 34937
#重启prometheus服务
./prometheus &
我们查看普罗米修斯的配置文件,其中定义了很多服务发现:
vim prometheus.yaml
global:
scrape_interval: 30s
scrape_timeout: 10s
evaluation_interval: 30s
external_labels:
prometheus: monitoring/k8s
prometheus_replica: prometheus-k8s-1
scrape_configs:
- job_name: serviceMonitor/monitoring/coredns/0 # 只查看这一个job,一个job其实就是一个监控项
honor_timestamps: true
scrape_interval: 15s # 采集时间,15s采集一次
scrape_timeout: 10s # 采集超时时间
metrics_path: /metrics # 采集数据指标接口
scheme: http # http架构
authorization: # 认证
type: Bearer # 认证的类型,这里表示Prometheus pod使用token方式去连接api-server
credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token
follow_redirects: true
relabel_configs:
- source_labels: [job]
separator: ;
regex: (.*)
target_label: __tmp_prometheus_job_name
replacement: $1
action: replace
- source_labels: [__meta_kubernetes_service_label_k8s_app, __meta_kubernetes_service_labelpresent_k8s_app]
separator: ;
regex: (kube-dns);true
replacement: $1
action: keep
- source_labels: [__meta_kubernetes_endpoint_port_name]
separator: ;
regex: metrics
replacement: $1
action: keep
- source_labels: [__meta_kubernetes_endpoint_address_target_kind, __meta_kubernetes_endpoint_address_target_name]
separator: ;
regex: Node;(.*)
target_label: node
replacement: ${1}
action: replace
- source_labels: [__meta_kubernetes_endpoint_address_target_kind, __meta_kubernetes_endpoint_address_target_name]
separator: ;
regex: Pod;(.*)
target_label: pod
replacement: ${1}
action: replace
- source_labels: [__meta_kubernetes_namespace]
separator: ;
regex: (.*)
target_label: namespace
replacement: $1
action: replace
- source_labels: [__meta_kubernetes_service_name]
separator: ;
regex: (.*)
target_label: service
replacement: $1
action: replace
- source_labels: [__meta_kubernetes_pod_name]
separator: ;
regex: (.*)
target_label: pod
replacement: $1
action: replace
- source_labels: [__meta_kubernetes_pod_container_name]
separator: ;
regex: (.*)
target_label: container
replacement: $1
action: replace
- source_labels: [__meta_kubernetes_service_name]
separator: ;
regex: (.*)
target_label: job
replacement: ${1}
action: replace
- source_labels: [__meta_kubernetes_service_label_app_kubernetes_io_name]
separator: ;
regex: (.+)
target_label: job
replacement: ${1}
action: replace
- separator: ;
regex: (.*)
target_label: endpoint
replacement: metrics
action: replace
- source_labels: [__address__]
separator: ;
regex: (.*)
modulus: 1
target_label: __tmp_hash
replacement: $1
action: hashmod
- source_labels: [__tmp_hash]
separator: ;
regex: "0"
replacement: $1
action: keep
metric_relabel_configs:
- source_labels: [__name__]
separator: ;
regex: coredns_cache_misses_total
replacement: $1
action: drop
kubernetes_sd_configs:
- role: endpoints
kubeconfig_file: ""
follow_redirects: true
namespaces:
names:
- kube-system
那么,谁去定义的Prometheus配置文件的呢,前面我们创建了一个ingress-nginx也没有修改Prometheus的配置文件呀?ingress-nginx也能正常呀。
原来,当你创建了一个servicemonitors之后(servicemonitors关联service,service关联pod),Prometheus会自动的修改secrets prometheus-k8s的prometheus.yaml.gz的值,然后边车容器自动热加载生效,所以,我们只需要熟悉servicemonitors的定义即可。不需要手动编辑Prometheus配置文件,怪不得官方将Prometheus配置文件的做成secrets 资源呢,原来是这样的。
这篇文章讲解了Prometheus的服务发现,写的很好,可以看下:prometheus学习笔记之服务发现kubernetes_sd_configs https://blog.51cto.com/u_8901540/12118325
告警规则
可以从这个开源的github项目上找告警规则:
https://github.com/samber/awesome-prometheus-alerts
# 这个仓库也有很多告警规则
https://github.com/helm/charts/tree/master/stable/prometheus-operator/templates/prometheus/rules
# 可以看到,边车容器里面有很多告警规则文件
[root@master setup]# kubectl -n monitoring exec -it prometheus-k8s-0 -c config-reloader -- sh
/ $ cd /etc/prometheus/rules/prometheus-k8s-rulefiles-0/
/etc/prometheus/rules/prometheus-k8s-rulefiles-0 $ ls
monitoring-alertmanager-main-rules-7050ad08-a18a-4df9-b0bb-835da9b99a20.yaml monitoring-node-exporter-rules-079bdb01-7159-46e6-92a4-691f30f64270.yaml
monitoring-kube-prometheus-rules-d40b5d99-a8d7-4dac-9e3d-95bd994d5949.yaml monitoring-prometheus-k8s-prometheus-rules-8a93e113-1d43-43fb-9019-af265730d88e.yaml
monitoring-kube-state-metrics-rules-c276ee95-abef-4cef-a8a7-c818c60196d7.yaml monitoring-prometheus-operator-rules-f8bf3204-3489-4c06-bf5b-0982f650e8c4.yaml
monitoring-kubernetes-monitoring-rules-67cf70c7-985f-4037-bd22-690bbcc5d6c1.yaml
/etc/prometheus/rules/prometheus-k8s-rulefiles-0 $ ls -lrth
total 0
lrwxrwxrwx 1 root 2000 85 Sep 23 09:29 monitoring-prometheus-operator-rules-f8bf3204-3489-4c06-bf5b-0982f650e8c4.yaml -> ..data/monitoring-prometheus-operator-rules-f8bf3204-3489-4c06-bf5b-0982f650e8c4.yaml
lrwxrwxrwx 1 root 2000 91 Sep 23 09:29 monitoring-prometheus-k8s-prometheus-rules-8a93e113-1d43-43fb-9019-af265730d88e.yaml -> ..data/monitoring-prometheus-k8s-prometheus-rules-8a93e113-1d43-43fb-9019-af265730d88e.yaml
lrwxrwxrwx 1 root 2000 79 Sep 23 09:29 monitoring-node-exporter-rules-079bdb01-7159-46e6-92a4-691f30f64270.yaml -> ..data/monitoring-node-exporter-rules-079bdb01-7159-46e6-92a4-691f30f64270.yaml
lrwxrwxrwx 1 root 2000 87 Sep 23 09:29 monitoring-kubernetes-monitoring-rules-67cf70c7-985f-4037-bd22-690bbcc5d6c1.yaml -> ..data/monitoring-kubernetes-monitoring-rules-67cf70c7-985f-4037-bd22-690bbcc5d6c1.yaml
lrwxrwxrwx 1 root 2000 84 Sep 23 09:29 monitoring-kube-state-metrics-rules-c276ee95-abef-4cef-a8a7-c818c60196d7.yaml -> ..data/monitoring-kube-state-metrics-rules-c276ee95-abef-4cef-a8a7-c818c60196d7.yaml
lrwxrwxrwx 1 root 2000 81 Sep 23 09:29 monitoring-kube-prometheus-rules-d40b5d99-a8d7-4dac-9e3d-95bd994d5949.yaml -> ..data/monitoring-kube-prometheus-rules-d40b5d99-a8d7-4dac-9e3d-95bd994d5949.yaml
lrwxrwxrwx 1 root 2000 83 Sep 23 09:29 monitoring-alertmanager-main-rules-7050ad08-a18a-4df9-b0bb-835da9b99a20.yaml -> ..data/monitoring-alertmanager-main-rules-7050ad08-a18a-4df9-b0bb-835da9b99a20.yaml
# 通过查看sts的yaml定义,我们得知告警规则文件是通过configmap挂载进去的
kubectl -n monitoring get sts prometheus-k8s -oyaml
kubectl -n monitoring get cm prometheus-k8s-rulefiles-0 -oyaml # 告警规则文件都定义在这里
告警其实就是写表达式,拿到某个指标的值,然后进行计算,大于小于某个值就报警,比如内存指标的数值大于总内存的80%就报警:可用内存不足。等等,告警就是这样的。所以必须保证有这个指标。去Prometheus的页面输入指标名称就能查看有没有这个指标了。
二进制部署Prometheus和kube-promethus对比
传统方式部署的Prometheus,在prometheus.yaml配置文件定义目标主机上抓取指标,这是静态配置targets的方式,如下:
scrape_configs:
- job_name: 'prometheus' # 定义一个job名字,可自定义,每个要抓取的目标主机都定义一个job
static_configs: # 这表示静态配置,还有一种叫服务发现,下面会讲
- targets: ['localhost:9090'] #要抓取的目标主机IP端口
metrics_path: /metrics # 数据指标接口,metrics_path defaults to '/metrics'
- job_name: 'node-exporter'
static_configs: # 这表示静态配置
- targets: ['192.168.118.112:9100'] #要抓取的目标主机IP端口
metrics_path: /metrics # 数据指标接口,metrics_path defaults to '/metrics'
而kube-promethus是使用服务发现的机制配置:
scrape_configs:
- job_name: serviceMonitor/default/redis-exporter/0
honor_timestamps: true
scrape_interval: 1m
scrape_timeout: 10s
metrics_path: /metrics
scheme: http
follow_redirects: true
relabel_configs:
- source_labels: [__tmp_hash]
separator: ;
regex: "0"
replacement: $1
action: keep
kubernetes_sd_configs:
- role: endpoints
kubeconfig_file: ""
follow_redirects: true
namespaces:
names:
- default
这是因为,在k8s集群,一切配置皆是以资源对象的形式存在的,即CRD资源,我们传统方式部署的Prometheus需要在promethus.yaml中定义要抓取的目标主机targets、告警rule等,在kube-promethus,官方通过CRD资源servicemonitors、prometheusrules来抽象出来了配置,当你创建了一个servicemonitors,promethus就会自动的将其转换为promethus.yaml里面的目标主机配置,所以现在只需要懂得如下编写servicemonitors就可以了,告警规则也是一样,promethus就会自动的将其转换为promethus.yaml里面的告警规则。
这就像我们熟知的nginx-ingress一样,我们只需要创建ingress,nginx-ingress-controller会自动的将ingress定义的规则加载到nginx.confg里面并生效。k8s强大吧,这就是k8s的配置都是资源对象的理念。
如果Prometheus部署在k8s集群外部,那如何监控k8s集群?
在k8s集群部署一个kube-state-metrics的deployment,kube-state-metrics就是暴露k8s集群数据指标的,然后创建NodePort service,Prometheus service 配置文件里面直接配置这个IP端口即可抓取数据指标。

















 2880
2880

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









