







什么是强化学习(RL)?
强化学习(RL)是机器学习的一个重要分支,主要用来解决连续决策的问题。强化学习可以在复杂的不确定的环境环境中学习如何实现我们设定的目标。强化学习的应用场景非常广,几乎包括了所有需要做一系列决策的问题,如控制机器人的电机让他完成特定任务、给商品定价或者进行库存管理、玩视频游戏或者棋牌游戏等。强化学习也可应用到有序列输出的问题中,因为他可以针对一系列变化的环境状态,输出一系列对应的行动。
什么是深度学习(DL)?
深度学习(DL)也是机器学习的一个重要分支,也就是多层神经网络,通过多层的非线性函数实现对数据分布及函数模型的拟合。目前在图像和音频信号方面应用效果比较好。深度学习从统计学的角度来说,就是在预测数据的分布,从数据中学得一个模型,然后通过这个模型去预测新的数据。深度学习更像是一个非常强大的机器学习工具。
什么是深度强化学习(DRL)?
深度强化学习将深度学习的感知能力和强化学习的决策能力相结合,可以直接根据输入的图像进行控制,是一种更接近人类思维方式的人工智能方法。
深度学习具有较强的感知能力,但是缺乏一定的决策能力;而强化学习具有决策能力,对感知问题束手无策。因此,将两者结合起来,优势互补,为复杂系统的感知决策问题提供了解决思路。
智能体与环境的不断交互(即在给定状态采取动作),进而获得奖励,此时环境从一个状态转移到下一个状态。智能体通过不断优化自身动作策略,以期待最大化其长期回报或收益(奖励之和)。
DRL是一种端对端(end-to-end)的感知与控制系统,具有很强的通用性.其学习过程可以描述为:
(1)在每个时刻agent与环境交互得到一个高维度的观察,并利用DL方法来感知观察,以得到具体的状态特征表示;
(2)基于预期回报来评价各动作的价值函数,并通过某种策略将当前状态映射为相应的动作;
(3)环境对此动作做出反应,并得到下一个观察.通过不断循环以上过程,最终可以得到实现目标的最优策略。
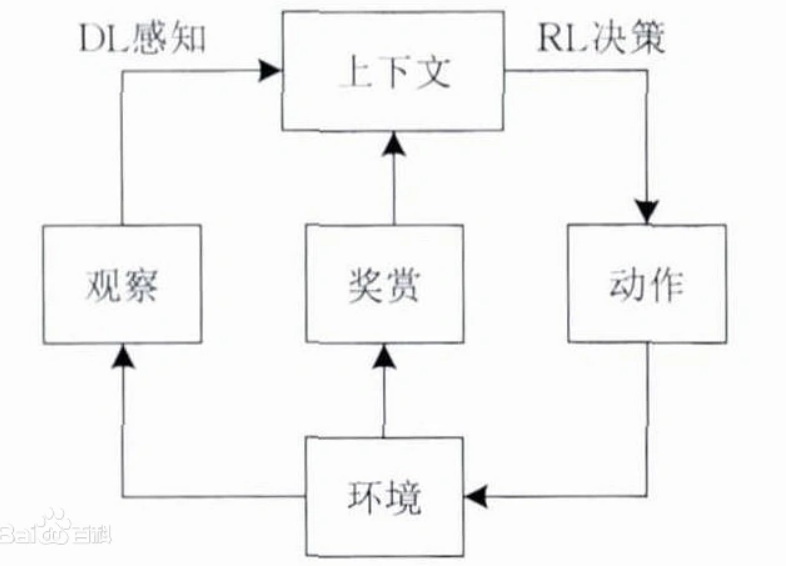
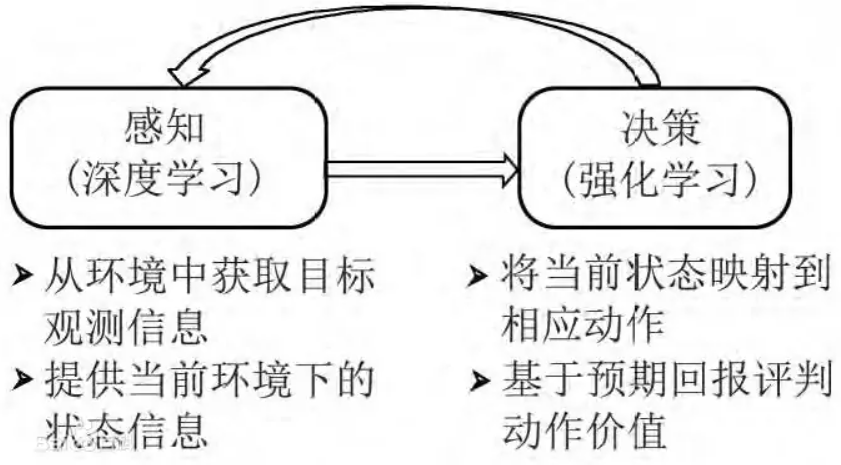
深度强化学习(Deep Reinforcement Learning,DRL)是一种结合了深度学习和强化学习的方法。它通过使用神经网络来近似值函数或策略函数,从而实现对复杂环境中的决策和行为的学习。 在深度强化学习中,智能体通过与环境的交互来学习最优策略。智能体通过观察环境的状态,选择一个动作,并接收环境的奖励信号来评估动作的好坏。通过不断地与环境交互,智能体通过优化策略来最大化累积奖励。 深度强化学习的核心是使用深度神经网络来近似值函数或策略函数。深度神经网络可以处理高维的输入数据,并通过反向传播算法来更新网络的参数,从而实现对值函数或策略函数的优化。 深度强化学习已经在许多领域取得了重要的突破,如游戏玩法、机器人控制、自动驾驶等。它能够处理高维、连续的状态和动作空间,并且能够通过大量的训练数据来学习复杂的决策和行为。 总而言之,深度强化学习是一种结合了深度学习和强化学习的方法,通过使用深度神经网络来近似值函数或策略函数,实现对复杂环境中的决策和行为的学习。
以下为论文Deep Reinforcement Learning Based Latency Minimization for Mobile Edge Computing With Virtualization in Maritime UAV Communication Network中DRL的应用
DRL是深度强化学习(Deep Reinforcement Learning)的缩写。它是一种结合了深度学习和强化学习的方法,用于解决具有连续状态和动作空间的优化问题。DRL算法通过让智能体与环境进行交互,通过试错的方式学习最优策略。在DRL中,智能体通过观察环境的状态,选择合适的动作,并根据环境的反馈(奖励信号)来调整策略,以最大化累积奖励。 在给定的信息中,作者使用了两种DRL算法,即DQN(Deep Q-Network)算法和DDPG(Deep Deterministic Policy Gradient)算法,来解决优化问题。DQN算法适用于低维离散空间的优化问题,而DDPG算法适用于高维连续空间的优化问题。这两种算法在作者的研究中都取得了良好的性能。 总的来说,DRL是一种强化学习方法,通过结合深度学习技术,可以有效地解决具有连续状态和动作空间的优化问题。在移动边缘计算中,DRL算法可以用于优化任务的调度和资源分配,以降低延迟并提高系统性能。
根据给定的信息,文章利用DRL(深度强化学习)算法来实现移动边缘计算中的延迟最小化。具体来说,文章使用了两种DRL算法,即DQN(Deep Q-Network)算法和DDPG(Deep Deterministic Policy Gradient)算法,来解决优化问题。这些算法通过训练智能体(T-UA V)的策略,以最小化任务的传输延迟和计算延迟。 在文章中,智能体通过与环境(包括B-UA V和T-UA V之间的通信环境)的交互来学习最优策略。智能体的状态由B-UA V的离线数据大小和T-UA V的位置组成,动作由T-UA V的飞行方向、飞行距离和VMs的数量组成。智能体根据环境的反馈(奖励信号)来调整策略,以最大化累积奖励并减少总体平均延迟。 文章中的实验结果表明,使用DRL算法进行轨迹优化和VM配置可以显著降低总体平均延迟。DDPG算法在轨迹设计方面表现更好,而DQN算法在离散空间的优化问题上表现较好。此外,通过动态选择VM的数量,可以进一步减少总体平均延迟。 综上所述,文章利用DRL算法实现了移动边缘计算中的延迟最小化,通过优化轨迹和VM配置来降低传输延迟和计算延迟。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











