









DB2 HADR(High Availability Disaster Recovery)简叙及安装使用
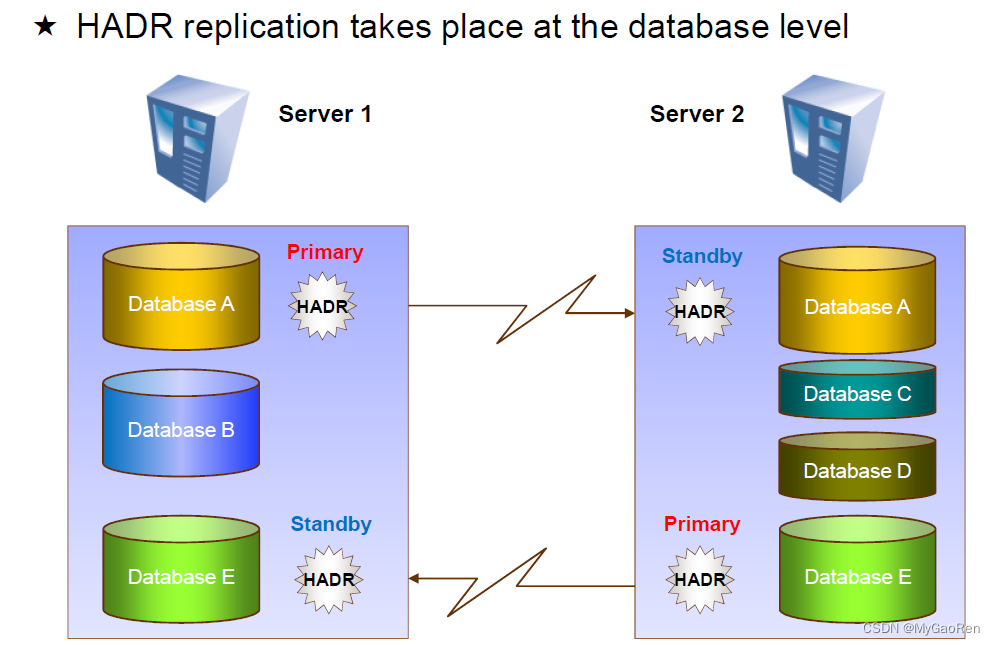
HADR( 高可用性灾难恢复 ) 是 DB2 数据库的一个组件,是 DB2 提供给用户的一种高可用性和灾难恢复的解决方案,提供数据库级别的数据保护。使用场景包括数据库热备保护、业务数据的读写分离、站点间容灾保护。
DB2 HADR
HADR全称为High Availability Disaster Recovery ,是IBM DB2数据库上的数据库级别的高可用性数据复制机制,最初被应用于Informix数据库系统中,称为High Availability Data Replication(HDR)。IBM收购Informix之后,这项技术就应用到了新的DB2发行版中。最早查到时间2004年应用与DB2 8.X版本。
HADR 用途广泛,并被完全集成到 DB2 数据库,不需要任何特殊硬件和软件,使用标准 TCP 接口连接主数据库和备用数据库。
原理
一个HADR环境最少需要两台数据库服务器:主数据库服务器(primary)和备用数据库服务器(standby)。
1、当主数据库中发生事务操作时,会同时将日志文件通过TCP/IP协议传送到备用数据库服务器,然后备用数据库对接受到的日志文件进行重放(Replay),从而保持与主数据库的一致性。
2、当主数据库发生故障时,备用数据库服务器可以接管主数据库服务器的事务处理。此时,备用数据库服务器作为新的主数据库服务器进行数据库的读写操作,而客户端应用程序的数据库连接可以通过自动客户端重新路由(Automatic Client Reroute)机制转移到新的主服务器。
3、当原来的主数据库服务器被修复后,又可以作为新的备用数据库服务器加入HADR。
通过这种机制,DB2 UDB实现了数据库的灾难恢复和高可用性,最大限度的避免了数据丢失。
参考:Client Reroute客户端自动路由功能
可以将客户机自动重新路由与高可用性灾难恢复 (HADR) 配合使用,以便将客户机应用程序请求从发生故障的数据库服务器转移至备用数据库服务器。
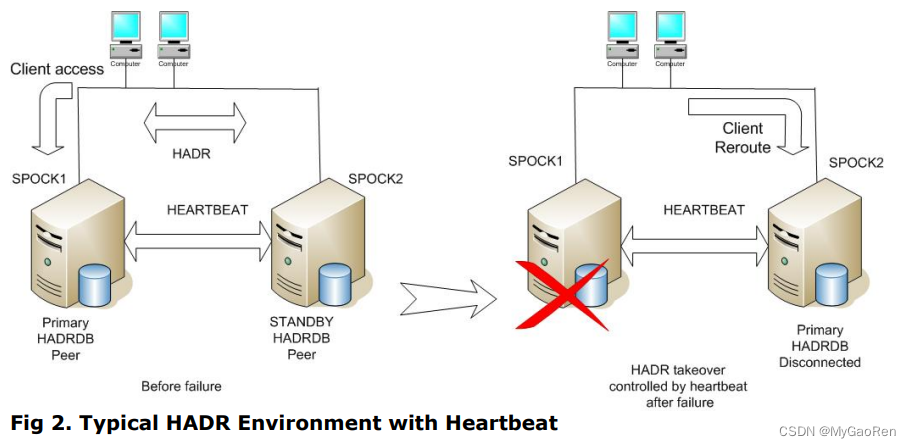
客户机自动重新路由功能的主要目标是使 IBM® Data Server Client应用程序能够恢复通信,以便应用程序可以继续工作,并将中断减至最低。 顾名思义,支持连续操作的核心在于重新路由,但是只有存在已向客户机连接标识的备用位置时,才能进行重新路由。
如果服务器是 DB2® for Linux, UNIX, and Windows,那么可以在下列可配置环境中使用客户机自动重新路由功能:
具有 分区数据库环境 的 DB2 Enterprise Server Edition
具备 IBM DB2 pureScale® Feature的 DB2 Enterprise Server Edition
InfoSphere® Replication Server
IBM PowerHA® SystemMirror for AIX®
高可用性灾难恢复 (HADR)
客户机自动重新路由与 HADR 和 DB2 pureScale 功能部件 配合工作,允许客户机应用程序在访问数据库故障转移之后继续其工作,并将中断减至最少。
以下是WAS的一个配置案例,,可以指定db的清单,可以指定failover的策略,可以指定错误的响应等。供参考,具体请参见其他文档
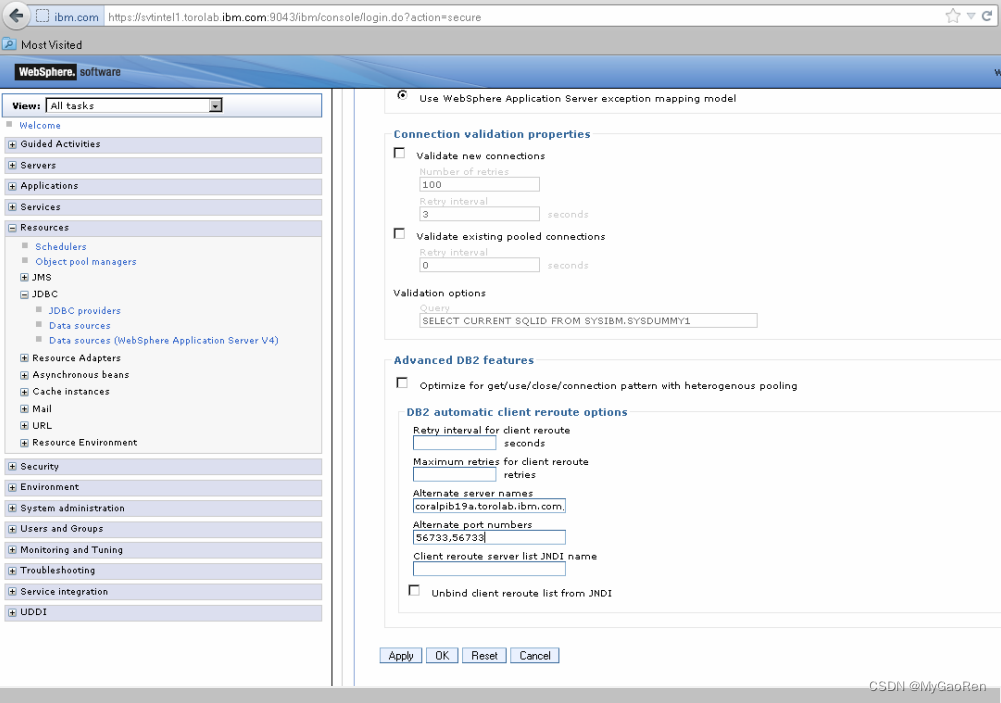
参考:
Configuring automatic client reroute and high availability disaster recovery (HADR)
https://www.ibm.com/docs/en/db2/11.1?topic=hadr-configuring-automatic-client-reroute
参考:TSA Tivoli System Automation高可用控制软件
IBM TSA高可用切换软件,是支持AIX/Linux等平台的高可用控制软件,负责控制、感知以及变更相关资源,包括IP、存储、服务或进程等资源的启动停止,感知异常后将资源切换到其他机器等。当前是集成到DB2 11.0安装中。
IBM TSA类似与传统PowerHA,支持AIX及Linux平台。
HADR配合TSA实现自动切换,包括HADR的主备角色,涉及到HADR对外服务地址等。

同步方式
HADR同步模式
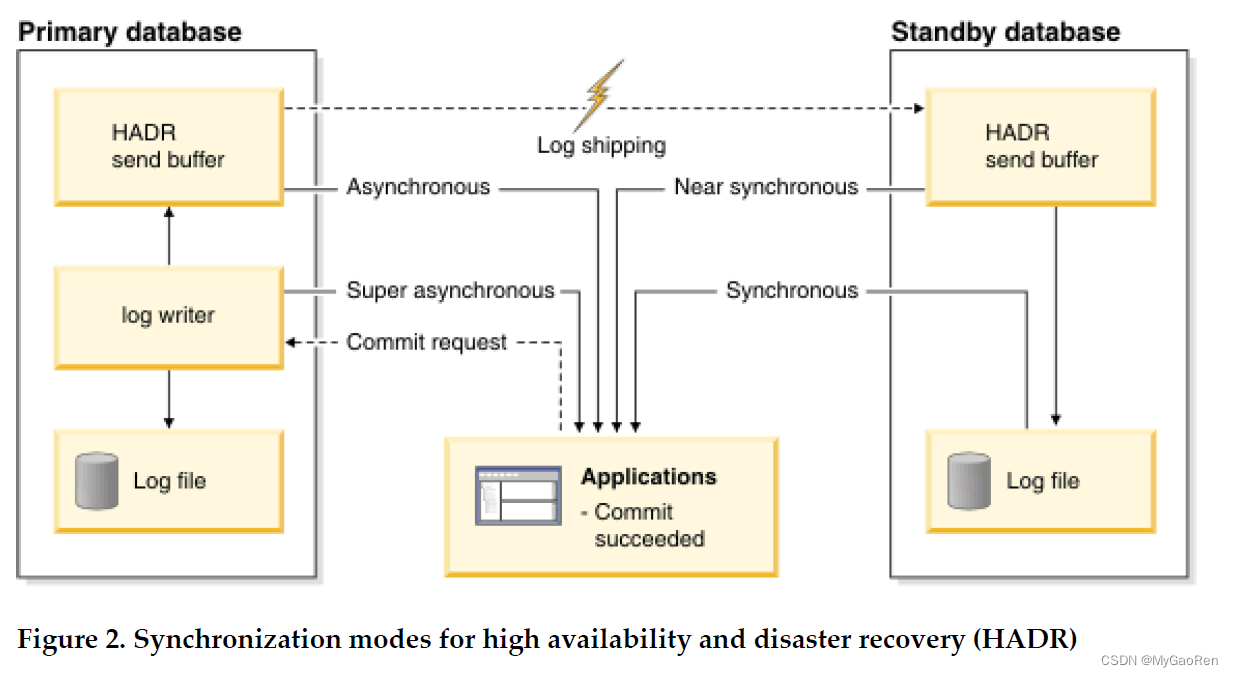
支持四种同步方式:SYNC(同步)、NEARSYNC(接近同步)、ASYNC(异步)、SUPERASYNC(超级异步)
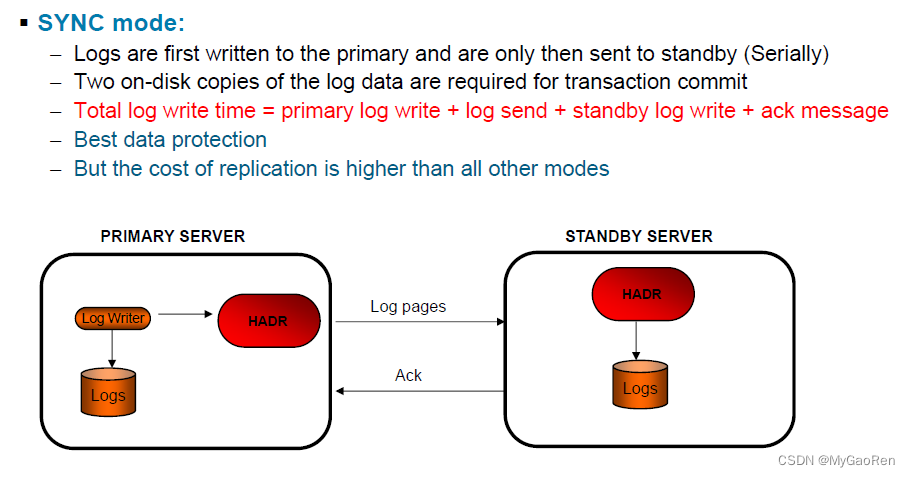
SYNC(同步)
在四种方式中,此方式将最大可能地避免事务丢失,但使用此方式会导致事务响应时间最长。
在此方式中,仅当日志已写入主数据库上的日志文件,而且主数据库已接收到来自备用数据库的应答,确定日志也已写入备用数据库上的日志文件时,方才认为日志写入是成功的。保证日志数据同时存储在这两处。
如果备用数据库在重放日志记录之前崩溃,那么它下次启动时,可从其本地日志文件中检索和重放这些记录。如果主数据库发生故障,故障转移至备用数据库可以保证任何已在主数据库上落实的事务也在备用数据库上落实了。执行故障转移操作之后,当客户机重新连接至新的主数据库时,新的主数据库上可能会有一些已落实的事务,在原始主数据库上却从未对应用程序将这些事务报告为已落实。当主数据库在处理来自备用数据库的应答消息之前出现故障时,即会出现此种情况。客户机应用程序应考虑查询数据库以确定是否存在此类事务。
如果主数据库断开了与备用数据库的连接,那么接下来的出现的情况取决于 hadr_peer_window 数据库配置参数的配置。如果 hadr_peer_window 已设置为非零时间值,那么在断开与备用数据库的连接时,主数据库将进入断开连接的对等状态,并且会在落实事务之前继续等待来自备用数据库的确认。如果 hadr_peer_window 数据库配置参数已设置为零,那么将不再认为主数据库和备用数据库处于对等状态,并且在等待来自备用数据库的确认时不会暂挂事务。如果在数据库不处于对等或断开连接的对等状态期间进行了故障转移操作,那么将不能保证在主数据库上落实的所有事务都会出现在备用数据库上。
当数据库处于对等或断开连接的对等状态时,如果主数据库失败,那么它可以在完成故障转移操作之后,作为备用数据库重新加入 HADR 数据库对。因为在主数据库接收到来自备用数据库的应答,确认日志已写入备用数据库上的日志文件之前,不认为事务已落实,所以主数据库上的日志顺序将与备用数据库上的日志顺序相同。原始主数据库(现在是备用数据库)只需要通过重放自从执行故障转移操作以来,在新的主数据库上生成的新日志记录来进行同步复制。
如果主数据库发生故障时并未处于对等状态,那么其日志顺序可能与备用数据库上的日志顺序不同。如果必须执行故障转移操作,主数据库和备用数据库上的日志顺序可能不同,因为在故障转移之后,备用数据库启动自己的日志顺序。因为无法撤销某些操作(例如,删除表),所以不可能将主数据库回复到创建新的日志顺序的时间点。如果日志顺序不同,并且在原始主数据库发出了带有 AS STANDBY 参数的 START HADR 命令,那么将接收到命令成功的消息。但是,此消息是在试图重新集成之前发出的。如果重新集成失败,HADR 对验证消息将发送至主数据库和备用数据库的管理日志和诊断日志。被重新集成的备用数据库将保持等候,但在进行对验证期间,主数据库将拒绝备用数据库,导致备用数据库关闭。如果原始主数据库成功地重新加入 HADR 对,那么可以通过发出未指定 BY FORCE 参数的 TAKEOVER HADR 命令来完成数据库的故障回退。如果原始主数据库无法重新加入 HADR 对,那么可以通过复原新的主数据库的备份映像将其重新初始化为备用数据库。
注: 不能在 DB2 pureScale® 环境中使用 SYNC 同步方式。
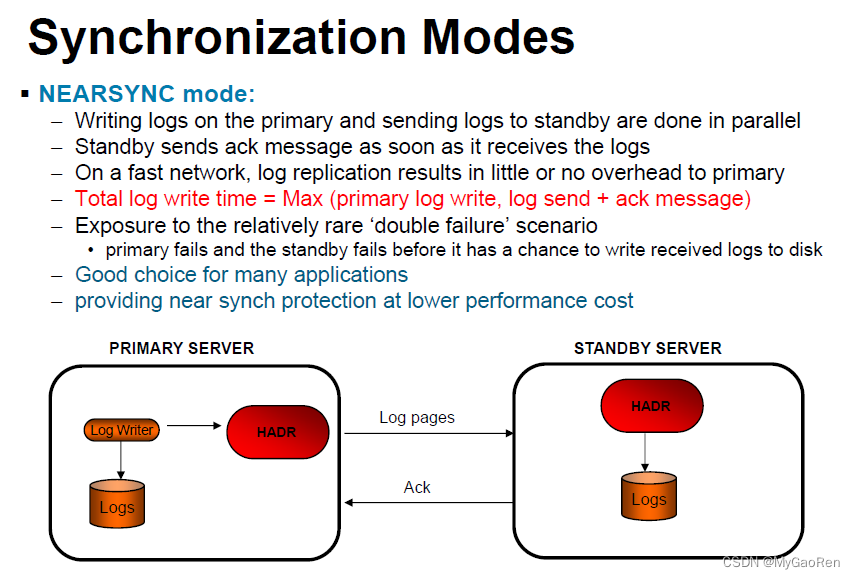
NEARSYNC(接近同步)
此方式具有比同步方式更短的事务响应时间,但针对事务丢失提供的保护也较少。
在此方式中,仅当日志记录已写入主数据库上的日志文件,而且主数据库已接收到来自备用系统的应答,确定日志也已写入备用系统上的主存储器时,方才认为日志写入是成功的。仅当两处同时发生故障,并且目标位置未将接收到的所有日志数据转移至非易失性存储器时,才会出现数据的丢失。
如果备用数据库在其将日志记录从存储器复制到磁盘之前崩溃,那么备用数据库上将丢失日志记录。通常,当备用数据库重新启动时,它可以从主数据库中获取丢失的日志记录。但是,如果主数据库或网络上的故障使检索无法进行,并且需要故障转移,那么日志记录将不会出现在备用数据库上,而且与这些日志记录相关联的事务将不会出现在备用数据库上。
如果事务丢失,那么在故障转移操作之后,新的主数据库与原始主数据库不相同。客户机应用程序应该考虑重新提交这些事务,以便使应用程序状态保持最新。
当主数据库和备用数据库处于对等状态时,如果主数据库发生故障,那么在没有使用完全复原操作重新初始化的情况下,原始主数据库可能无法作为备用数据库重新加入 HADR 对。如果故障转移涉及丢失的日志记录(因为主数据库和备用数据库已发生故障),主数据库和备用数据库上的日志顺序将会不同,并且在未首先执行复原操作的情况下,重新启动原始主数据库以作为备用数据库的尝试将会失败。如果原始主数据库成功地重新加入 HADR 对,那么可以通过发出未指定 BY FORCE 参数的 TAKEOVER HADR 命令来完成数据库的故障回退。如果原始主数据库无法重新加入 HADR 对,那么可以通过复原新的主数据库的备份映像将其重新初始化为备用数据库。
注: 不能在 DB2 pureScale 环境中使用 NEARSYNC 同步方式。
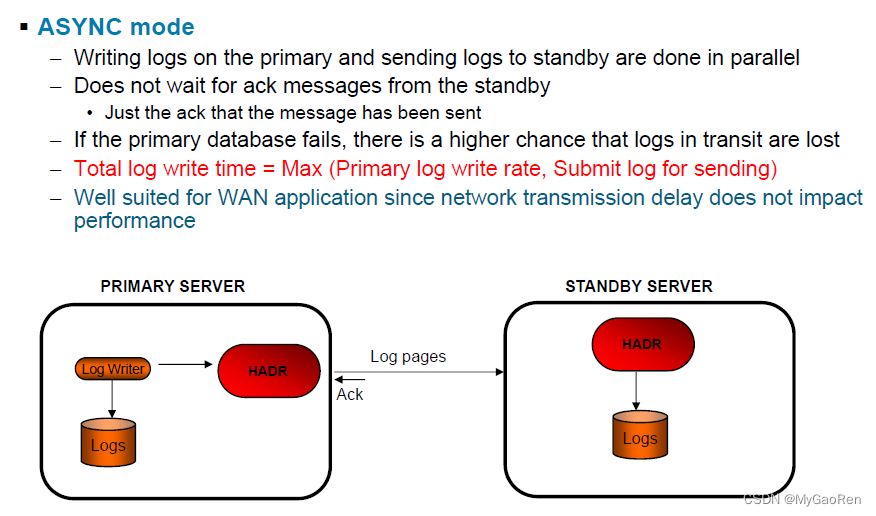
ASYNC(异步)
与 SYNC 和 NEARSYNC 方式相比,ASYNC 方式使事务响应时间更短,但在主数据库出现故障时,导致事务丢失的可能性更大。
在 ASYNC 方式下,仅当日志记录已写入主数据库上的日志文件,并且已传递到主系统的主机的 TCP 层时,才认为日志写入成功。因为主系统不会等待来自备用系统的确认,所以当事务仍处于正在传入备用数据库的过程中时,可能会认为事务已落实。
主数据库主机上、网络上或备用数据库上的故障可能导致传送中的日志记录丢失。如果主数据库可用,那么会在重新建立“ 对”连接时,将丢失的日志记录重新发送至备用数据库。但是,如果在有丢失日志记录的情况下需要执行故障转移操作,那么那些日志记录将不会到达备用数据库,从而导致在故障转移中丢失关联的事务。
如果事务丢失,那么在故障转移操作之后,新的主数据库与原始主数据库不是完全相同的。客户机应用程序应该考虑重新提交这些事务,以便使应用程序状态保持最新。
当主数据库和备用数据库处于对等状态时,如果主数据库发生故障,那么在没有使用完全复原操作重新初始化的情况下,原始主数据库可能无法作为备用数据库重新加入 HADR 对。如果故障转移涉及丢失的日志记录,主数据库和备用数据库上的日志顺序将会不同,并且重新启动原始主数据库以作为备用数据库的尝试将失败。因为,如果在异步方式中发生故障转移,日志记录更有可能丢失,所以主数据库将不能重新加入 HADR 对的可能性也更大。如果原始主数据库成功地重新加入 HADR 对,那么可以通过发出未指定 BY FORCE 参数的 TAKEOVER HADR 命令来完成数据库的故障回退。如果原始主数据库无法重新加入 HADR 对,那么可以通过复原新的主数据库的备份映像将其重新初始化为备用数据库。
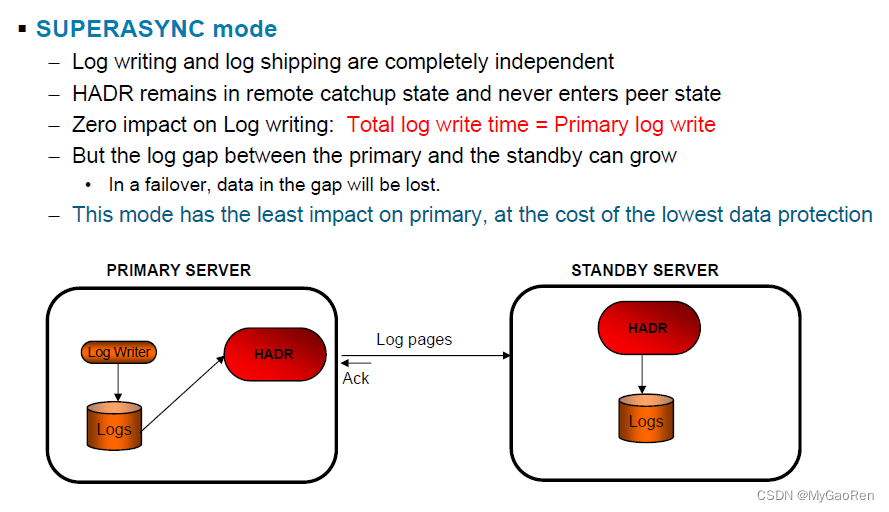
SUPERASYNC(超级异步)
此方式具有最短的事务响应时间,但在主系统出现故障时,此方式导致事务丢失的可能性也最大。当您不希望事务由于网络中断或拥塞而受到阻塞或经历较长的响应时间时,此方式很有用。
在此方式下,HADR 对永远不会处于对等状态或断开连接的对等状态。只要日志记录已写入主数据库上的日志文件,就认为日志写入成功。由于主数据库不会等待来自备用数据库的确认,所以无论事务的复制状态如何,都会认为已落实该事务。
主数据库主机上、网络上或备用数据库上的故障可能导致传送中的日志记录丢失。如果主数据库可用,那么会在重新建立“ 对”连接时,将丢失的日志记录重新发送至备用数据库。但是,如果在有丢失日志记录的情况下需要执行故障转移操作,那么那些日志记录将不会到达备用数据库,从而导致在故障转移中丢失关联的事务。
如果事务丢失,那么在故障转移操作之后,新的主数据库与原始主数据库不是完全相同的。客户机应用程序应该考虑重新提交这些事务,以便使应用程序状态保持最新。
因为主数据库上的事务落实操作不会受到相对较慢的 HADR 网络或备用 HADR 服务器的影响,所以主数据库与备用数据库之间的日志间隔可能会继续增大。监视日志间隔很重要,这是因为在主系统上发生真正的灾难时,日志间隔是可能丢失的事务数的间接度量。在灾难恢复方案中,日志间隔期间落实的任何事务都对备用数据库不可用。因此,请使用 hadr_log_gap 监视器元素来监视日志间隔;如果出现日志间隔不可接受的情况,请调查网络中断次数或备用数据库节点的相对速度,并采取纠正措施以减小日志间隔。
如果主数据库发生故障,那么在没有使用完全复原操作重新初始化的情况下,原始主数据库可能无法作为备用数据库重新加入 HADR 对。如果故障转移涉及丢失的日志记录,主数据库和备用数据库上的日志顺序将会不同,并且重新启动原始主数据库以作为备用数据库的尝试将失败。因为在超级异步方式下发生故障转移时,丢失日志记录的可能性更大,所以主数据库无法重新加入 HADR 对的可能性也更大。如果原始主数据库成功地重新加入 HADR 对,那么可以通过发出未指定 BY FORCE 参数的 TAKEOVER HADR 命令来完成数据库的故障回退。如果原始主数据库无法重新加入 HADR 对,那么可以通过复原新的主数据库的备份映像将其重新初始化为备用数据库。
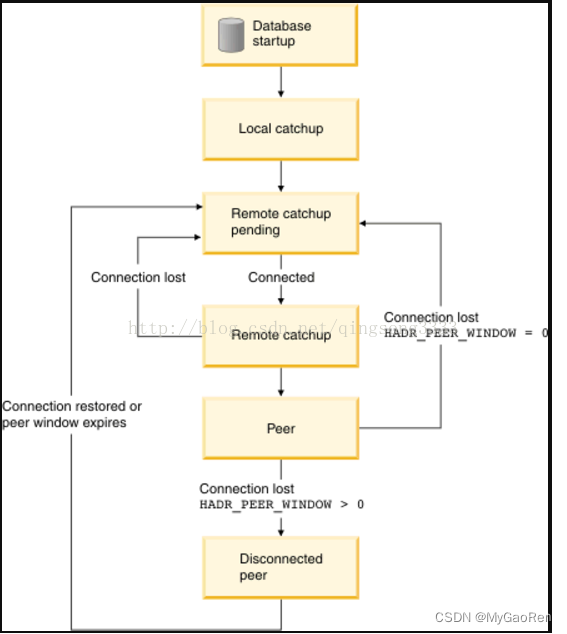
5种备机状态状态
Local catchup state 备机激活后,会从它本地的日志目录读取日志。
Remote catchup pending state 读完本机的日志之后,备机就会进入Remote catchup pending state状态。
Remote catchup state 一旦和主机建立了连接,主机会读取自己的日志,发送到备机,备机这时候追主机的日志,这种状态为Remote catchup state。
Peer state 这个状态下,日志条目不是从文件中读取了,而是直接从主机的log buffer发送到备机,这个状态叫做Peer state。
Disconnected peer state 在peer状态下,如果连接已经丢失,但配置了hadr_peer_window参数,这时候会进入Disconnected peer状态。这个状态的意思是,虽然主备机的连接已经丢失,但主机会”假装“仍然是peer状态,直到hadr_peer_window也超时。这样做的好处是不至于主备机连接一断开主机就立刻写日志,有助于保持主备机的数据一致性
应用场景
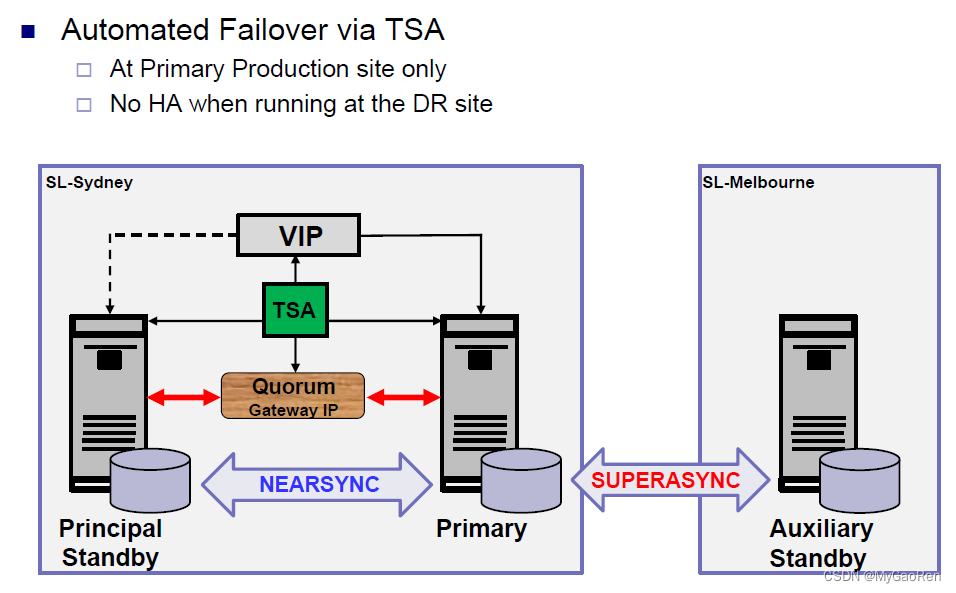
1、高可用场景
与TSA、或者PowerHA、或者第三方高可用控制软件),实现基于硬件或操作系统或者数据库级别(脚本)的自动感知及切换。
2、读写分离场景
RoS请求:Reads on Standby (RoS) supported on all standbys
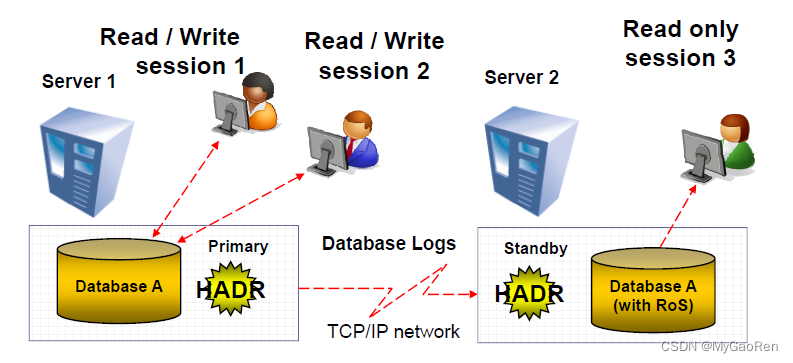
一个BI业务中读写分离的场景,DataStage server读写请求到HADR primary主服务器,而Cognos 10 BI server的只读请求到HADR standby备服务器。
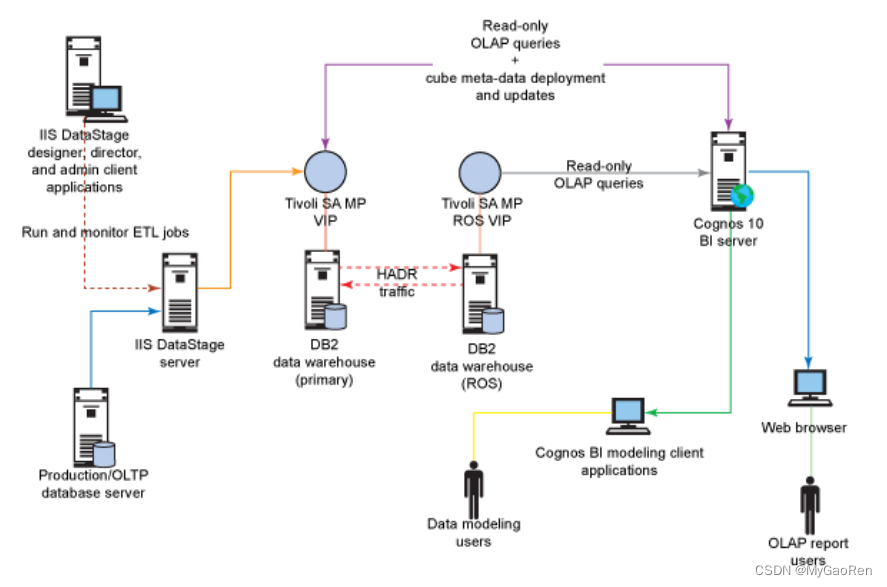
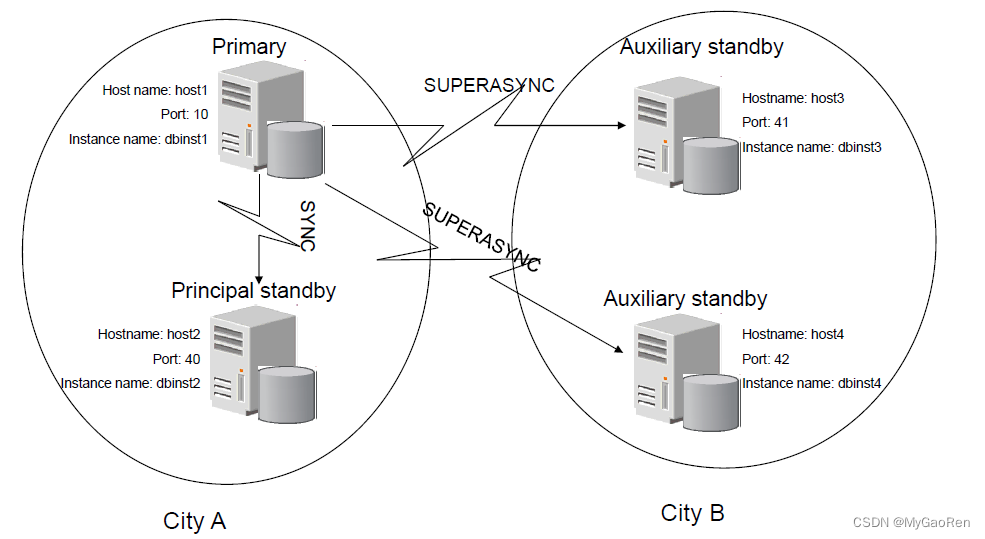
3、同城灾备或者两地三中心场景
5、HADR波动升级场景
可以先升级standby备节点,此期间不影响主节点,升级完成后启动standby备节点。确保数据一致后,再安排时间窗口切换HADR角色,将原有standby备节点作为主节点对外服务,同步升级原有主节点。

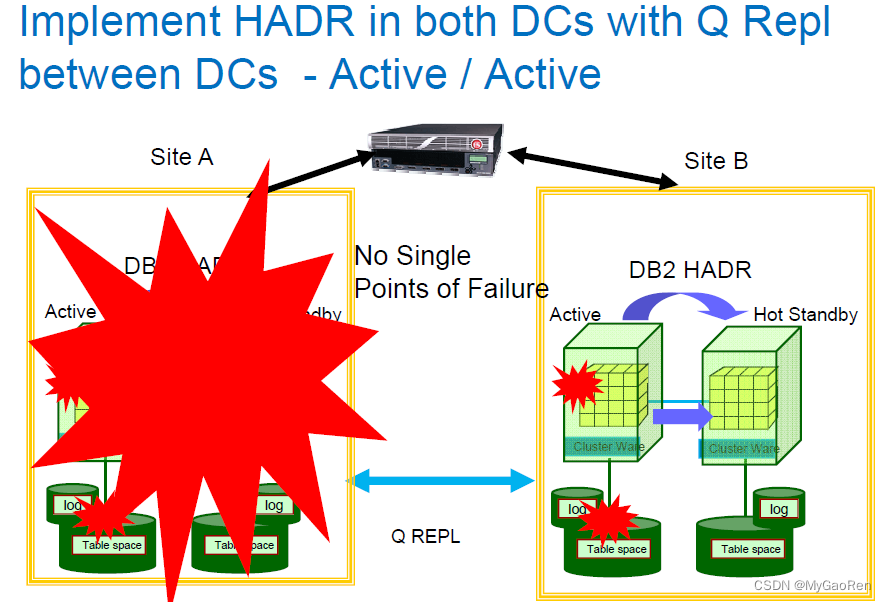
6.同机房用HADR 及 不同数据中心用Q Repl场景
配置
配置可以使用命令行,或者db2cc控制中心心图形界面
注意
1.机器之间时间必须同步,生产环境配置时钟同步服务;
2.建议操作系统版本、DB2数据库版本等保持一致;
3.建议db2数据库用户标识等保持一致;
软件版本
基于DB2 11.1
机器信息
源数据库 source 192.168.0.11
目标数据库 target 192.168.0.12
操作机 opr 192.168.1.22
准备数据库
注意:
1.注意license级别;
2.注意数据库的codepage一致;
1、在source建立源数据库
db2 "create db sample"
2、在target建立目标数据库
db2 "create db sample"
3、准备/etc/hosts文件
192.168.0.11 db2_node1 source
192.168.0.12 db2_node2 target
4、准备/etc/services文件
db2_hadr1 50000/tcp
db2_hadr2 50001/tcp
5、准备测试表
source及target上准备测试表,包括主键
db2 "create table qrep.employee(id int NOT NULL, FAMILYNAME char(20), GIVENNAME char(20), PRIMARY KEY (ID))"
配置source
db2 update db cfg for sample using LOGARCHMETH1 LOGRETAIN
db2 backup db sample
db2 update db cfg for sample using HADR_LOCAL_HOST db2_node1
db2 update db cfg for sample using HADR_LOCAL_SVC db2_hadr1
db2 update db cfg for sample using HADR_REMOTE_HOST db2_node2
db2 update db cfg for sample using HADR_REMOTE_SVC db2_hadr2
db2 update db cfg for sample using HADR_REMOTE_INST db2inst1
db2 update db cfg for sample using LOGINDEXBUILD ON
配置target
db2 "restore database sample "
db2 update db cfg for sample using HADR_LOCAL_HOST db2_node2
db2 update db cfg for sample using HADR_LOCAL_SVC db2_hadr2
db2 update db cfg for sample using HADR_REMOTE_HOST db2_node1
db2 update db cfg for sample using HADR_REMOTE_SVC db2_hadr1
db2 update db cfg for sample using HADR_REMOTE_INST db2inst1
启动hadr
启动备节点,在target上
db2 start hadr on database hadr as standby
查看hadr状态,在target上
db2pd -db sample -hadr
启动主节点,在source上
db2 start hadr on database hadrdb as primary
查看hadr状态,在target及source上
db2pd -db hadrdb -hadr
主备切换
在备机端:
db2 TAKEOVER HADR ON DB sample
强制切换:
db2 TAKEOVER HADR ON DB sample BY FORCE
primary故障时,可以将standby DB的Role向primary进行强制切换
复制测试
测试
插入数据检查数据是否复制到对端
检查sorce及target端条数
db2 "select count(*) from qrep.employee"
source插入数据
db2 "insert into qrep.employee values(5,'a','aa'),(6,'b','bb')";
db2 commit;
检查sorce及target端条数
db2 "select count(*) from qrep.employee"
客户端自动路由测试
配置客户端自动路由
1、在target执行
db2 “update alternate server for sample using hostname 192.168.0.11 port 50000”
2、在source执行
db2 “update alternate server for sample using hostname 192.168.0.12 port 50001”
自动路由测试
测试方法,先确定主备运行正常,能正常连接,页面或java能正常执行,其次手动关闭或强制source上db2实例停止后,重新测试效验
方法1:使用db2 jdbc type4 drive内部方法测试
export $CLASSPATH=$CLASSPATH:/home/db2inst1/sqllib/java/db2java.zip:/home/db2inst1/sqllib/function:/home/db2inst1/sqllib/java/db2jcc_license_cu.jar:/home/db2inst1/sqllib/tools/clpplus.jar:/home/db2inst1/sqllib/tools/jline-0.9.93.jar:/home/db2inst1/sqllib/java/db2jcc.jar:.
java com.ibm.db2.jcc.DB2Jcc -url 'jdbc:db2://192.168.0.11:50000/SAMPLE:clientRerouteAlternateServerName=192.168.0.12:50000;clientRerouteAlternatePortNumber=50001;maxRetriesForClientReroute=2;retryIntervalForClientReroute=3;' -user db2inst1 -password password
手动关闭或强制source上db2实例停止后,重新测试效验
方法2:WAS数据源测试
1、在was管理控制台,创建数据源,在指定或修改其定制属性,重启应用服务器java进程生效后,再重新测试。
注意:在定制参数的列表显示的概要设置中,勾选显示所有参数属性,否则部分定制参数不会显示。
enableClientAffinitiesList =1
serverName=192.168.0.11
portNumber=50000
clientRerouteAlternateServerName=192.168.0.11,192.168.0.12
clientRerouteAlternatePortNumber=50000,50001
maxRetriesForClientReroute=2
retryIntervalForClientReroute=3
enableSeamlessFailover=2
2、手动关闭或强制source上db2实例停止后,重新测试效验
WAS部署测试页面如下:
<%@ page import="java.sql.*, javax.sql.*, java.io.*, javax.naming.*" %>
<html>
<head><title>Hello world from JSP</title></head>
<body>
<%
InitialContext ctx;
DataSource ds;
Connection conn;
Statement stmt;
ResultSet rs;
try {
ctx = new InitialContext();
ds = (DataSource) ctx.lookup("jdbc/sample");
conn = ds.getConnection();
stmt = conn.createStatement();
rs = stmt.executeQuery("SELECT * FROM qrep.employee");
while(rs.next()) {
%>
<h3>Output: <%= rs.getString(1) %></h3>
<%
}
}
catch (SQLException se) {
%>
<%= se.getMessage() %>
<%
}
catch (NamingException ne) {
%>
<%= ne.getMessage() %>
<%
}
%>
</body>
</html>
方法3、定制java方法测试
新建java.class文件
public class ACRSample {
public static void main(String args[]) {
String connectionURL = "jdbc:db2://192.168.0.11:50000/SAMPLE:user=db2inst1;password=password;enableClientAffinitiesList=1;maxRetriesForClientReroute=2;retryIntervalForClientReroute=3;clientRerouteAlternateServerName=192.168.0.11,192.168.0.12;clientRerouteAlternatePortNumber=50000,50001;enableSeamlessFailover=true;";
Connection con = null;
try {
// Load the JCC Driver class (db2jcc4.jar).
Class.forName("com.ibm.db2.jcc.DB2Driver");
//Create the connection using the static getConnection method
con = DriverManager.getConnection(connectionURL);
Statement stmt = con.createStatement();
ResultSet rs = null;
con.setAutoCommit(false);
try {
rs = stmt.executeQuery("select FAMILYNAME , GIVENNAME from QREP.EMPLOYEE");
// Print results
while (rs.next()) {
System.out.println("Name= " + rs.getString("FAMILYNAME ") + " GIVENNAME = " + rs.getString("GIVENNAME"));
}
// do a random update
String sql = "update QREPL.EMPLOYEE set GIVENNAME = '" + RandomAlphaNum.gen(10) + "'";
stmt.executeUpdate(sql);
con.commit();
} catch (java.sql.SQLException e) {
//Catch return code to do any retry
if (e.getErrorCode() == -30108 || e.getErrorCode() == -4498 || e.getErrorCode() == -4499) {
// Add any logic to reply the current in flight transaction
// if necessary
System.out.println("Replay any transactions if necessary");
} else {
throw e;
}
}
} catch (SQLException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if (con != null) {
con.close();
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
HADR监控及参数
db2pd -hadr命令说明
心跳丢失数量(HeartBeatMissed):主机会不断地向备机发送心跳,以确认仍然可以和对方通信。这个值表明了有多少心跳信号没有发送成功或者没有接收成功。
日志 LSN 差异(LogGapRunAvg):这个值表示一段时间以内,主机和备机日志差异的平均值。如果这个值一直很大,可能表明网络状况比较差,或者备机的性能和主机差异太大,以至于日志不能及时的从主机传到备机。
连接状态(ConnectStatus):包括三种 CONNECTED, DISCONNECTED, CONGESTED。CONNECTED 表示连接状况良好;DISCONNECTED 表示主机和备机已经断开连接;CONGESTED 表示当前的网络状况不太好,日志或者消息的发送遇到拥塞。
连接时间(ConnectTime):如果主机和备机是连接的,表示连接建立起来的时间;如果连接时断开的,表示的是连接断开的时间;如果发生了网络拥塞,则表示上次网络拥塞的时间。
超时时间(Timeout):如果 HADR 在这段时间内没有收到来自同伴的任何消息,它就会断开网络连接。需要注意的是,这个时间并一定是网络出现错误以后的等待时间。HADR 可以发现网络上的大部分错误,当这些错误发生时,HADR 会立刻断开和对方的连接,而并不会等待。另外,这项配置还有另外两个作用:
1. 心跳的时间间隔为 HADR_TIMEOUT/4 和 30 秒钟两者之间的较小的那个值
2. 如果首先在主机上执行启动 HADR 的操作,如果主机没有在 HADR_TIMEOUT 时间以内没有收到备机的连接,主机上的数据库就会停掉,以防止两台主数据库的存在而导致脑裂。
同伴窗口(PeerWindow):相对应 DB2 配置文件中的 HADR_PEER_WINDOW,该参数只对 SYNC 和 NEARSYNC 两种同步模式有效。如果该参数不为零,当主机和备机断开连接时,在 HADR_PEER_WINDOW 这段时间以内,数据库处于 DISCONNECTED PEER 状态。主机在这段时间内不能提交任何事务。所以,这段时间内,如果备机做了接管,备机不会丢失任何事务。这个参数通对于在 TSA 对 HADR 自动做接管的环境中特别重要,因为 TSA 执行“takeover hard on db dbname by force peer window only”这个命令进行接管。
同伴窗口结束时间(PeerWindowEnd):显示了同伴窗口的结束时间。过了这个时间以后,HADR 将处于 DISCONNECTED 状态。
本地主机名(LocalHost):本地 HADR 所在的主机名或者 IP 地址。
本地服务名(LocalService):本地 HADR 所使用的服务名称或者端口号。
远程主机名(RemoteHost):对端 HADR 所在机器的的主机名或者 IP 地址。
远程服务名(RemoteService):对端 HADR 使用的服务名称或者端口号。
远程实例(RemoteInstance):对端 HADR 数据库所在的实例的名字。
主机日志文件(PrimaryFile):主机目前正在写的日志文件。
主机日志页号(PrimaryPg):主机目前正在写的日志文件中的页号。
主机日志序号(PrimaryLSN):主机正在处理的日志记录的序列号。
备机日志文件(StandByFile):备机目前正在写的日志文件。
备机日志页号(StandByPg):备机目前正在写的日志文件中的页号。
备机日志序号(StandByLSN):备机正在处理的日志记录的序列号。
HADR的3个超时参数
hadr_timeout:如果这么长的时间里,主备机还建立不了联系,那么主机就认为和备机的连接丢失
hadr_peer_window:在主、备机的连接丢失之后,如果设置了这个参数,HADR会进入Disconnected peer 状态。具体请参考上面的描述。
DB2_HADR_PEER_WAIT_LIMIT:这个是db2set设置的参数,意思是如果主机的日志因为复制到备机而被阻塞这么久,那主机就认为和备机的连接丢失,这个和达到hadr_timeout效果一样,只是触发原因不同。














 1872
1872











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









