






新建文件crawlertask.py,用于执行数据抓取任务,代码如下。
#coding:utf-8
from celery import Celery,platforms
import requests
from bs4 import BeautifulSoup
app=Celery('tasks',broker='redis://localhost:6379/0')
app.conf.CELERY_RESULT_BACKEND='redis://localhost:6379/0'
platforms.C_FORCE_ROOT=True
def format_str(str):
return str.replace("\n","").replace(" ","").replace("\t","")
@app.task
def get_urls_in_pages(from_page_num,to_page_num):
urls=[]
search_word='计算机'
url_part_1='http://www.phei.com.cn/module/goods/'\
'searchkey.jsp?Page='
url_part_2='&Page=2&searchKey='
for i in range(from_page_num,to_page_num+1):
urls.append(url_part_1+str(i)+url_part_2+search_word)
all_href_list=[]
for url in urls:
resp=requests.get(url)
bs=BeautifulSoup(resp.text)
a_list=bs.find_all('a')
needed_list=[]
for a in a_list:
if 'href' in a.attrs:
href_val=a['href']
title=a.text
if 'bookid' in href_val and 'shopcar0.jsp' not in href_val and title!='':
if [title,href_val] not in needed_list:
needed_list.append([format_str(title),format_str(href_val)])
all_href_list+=needed_list
all_href_file = open(str(from_page_num)+'_'+str(to_page_num)+'_'+'all_hrefs.txt','w')
for href in all_href_list:
all_href_file.write('\t'.join(href)+'\n')
all_href_file.close()
return len(all_href_list) 将以上脚本部署到两台云端服务器。
并且在云端开启redis服务,然后执行:
celery worker -A crawlertask -l info -c 10
在本机新建文件task_dist.py用于异步分发任务,代码如下:
from celery import Celery
from threading import Thread
import time
redis_ips={
0:'redis://101.200.163.195:6379/0',
1:'redis://112.124.28.41:6379/0',
2:'redis://112.124.28.41:6379/0',
3:'redis://101.200.163.195:6379/0',
}
def send_task_and_get_results(ind,from_page,to_page):
app=Celery('crawlertask',broker=redis_ips[ind])
app.conf.CELERY_RESULT_BACKEND=redis_ips[ind]
result=app.send_task('crawlertask.get_urls_in_pages',args=(from_page,to_page))
print(redis_ips[ind],result.get())
if __name__=='__main__':
t1=time.time()
page_ranges_lst=[
(1,10),
(11,20),
(21,30),
(31,40),
]
th_lst = []
for ind, page_range in enumerate(page_ranges_lst):
th = Thread(target=send_task_and_get_results,
args=(ind,page_range[0], page_range[1]))
th_lst.append(th)
for th in th_lst:
th.start()
for th in th_lst:
th.join()
t2 = time.time()
print("用时:", t2 - t1)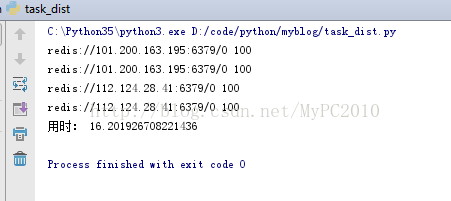
















 1165
1165

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











