







用一句话来说,UUID V4使用全随机的方式生成 UUID 值,根据 MySQL B+ 树的原理,在高频插入的场景下无法利用到局部性的优势,导致频繁树节点分裂,脏页刷盘,使得 I/O 升高。
背景知识

UUID-V4:
- 生成方式
- UUIDv4 是通过完全随机数生成器生成的。
- 基本特性
- 取值范围:128 位中,122 位为随机数,每个十六进制字符取值范围为
0至f。 - 存储形式:可存储为字符串(36 字符,包括破折号)或直接以 16 字节的二进制形式存储,后者节省空间且效率更高。
- 唯一性保障:UUIDv4 的唯一性非常可靠,重复概率极低。理论上,UUIDv4 的总可能组合数约为 2^122,即 5.3×10^36。在分布式系统中,即使生成数十亿个 UUID,冲突的概率也微乎其微。
- 取值范围:128 位中,122 位为随机数,每个十六进制字符取值范围为
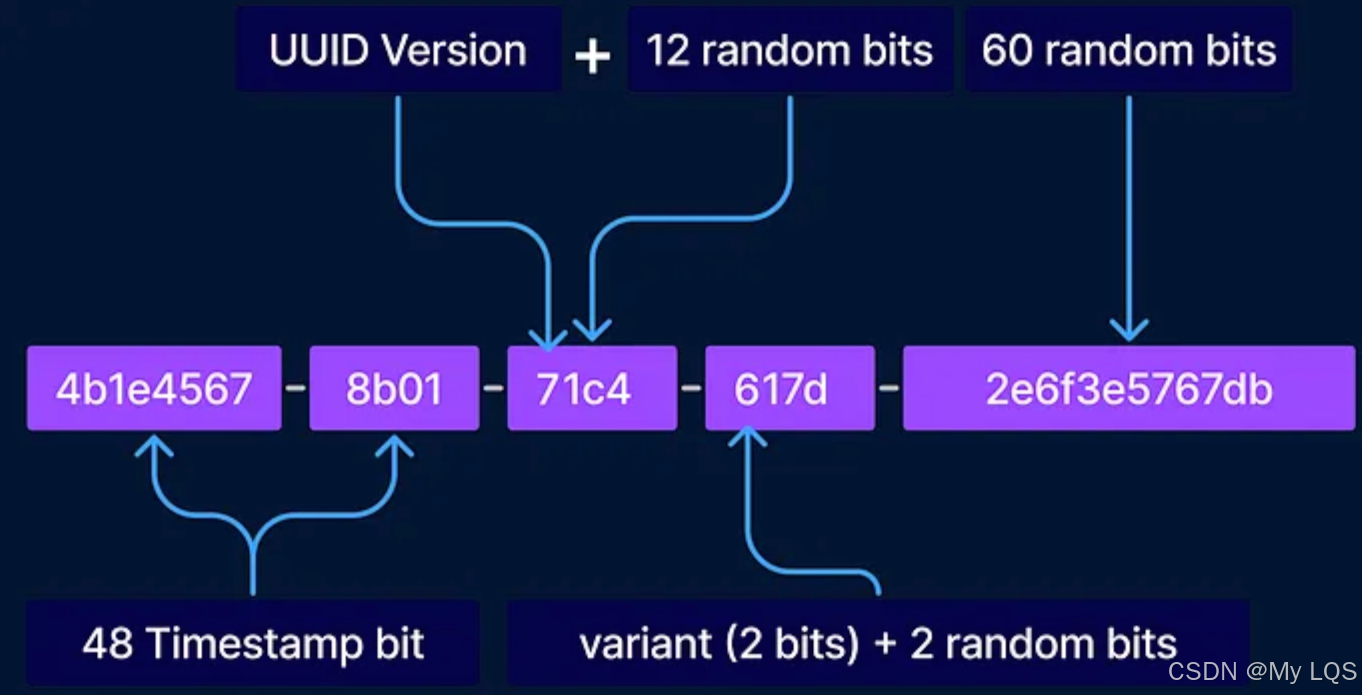
UUID-V7 :
- 生成方式
- UUIDv7 是基于时间戳驱动生成的,同时保留了一部分随机数。
- 前 48 位嵌入了毫秒级的 Unix 时间戳,后续部分为随机数。
- 基本特性
- 时间排序:由于时间戳的单调递增特性,UUIDv7 生成的值具备天然的顺序性,非常适合日志、事件流等需要时间排序的场景。
- 存储形式:与 UUIDv4 相同,可以存储为字符串或二进制形式。
- 随机性:时间戳之外的部分仍保留 80 位随机数,以确保唯一性。
核心对比表
| 特性 | UUID4 | UUID7 |
|---|---|---|
| 生成方式 | 完全随机生成 | 基于时间戳 + 部分随机 |
| 时间戳支持 | 无时间戳信息 | 包含时间戳,能反映生成时间 |
| 顺序性 | 无顺序性 | 高顺序性,基于时间戳驱动 |
| 分布式支持 | 良好,适合大规模分布式系统 | 良好,适合分布式系统且性能更优,不过对系统时间依赖较强,需防止时钟漂移或回拨问题。 |
| 数据库性能 | 插入性能差(完全随机,索引分裂) | 插入性能高(顺序性减少分裂) |
| 可读性和可用性 | 无法解析 | 能解析生成时间 |
| 适用场景 | 分布式唯一标识,无需时间排序场景 | 分布式唯一标识,需时间排序场景 |
| 生成性能 | 不如UUID V7 | 相对于UUID V4强,UUIDv7中的随机部分相对于UUIDv4更少,意味着对随机数生成器的依赖性降低,从而提高了生成速度; |
用UUID-V7替换UUID-V4 提高数据库性能
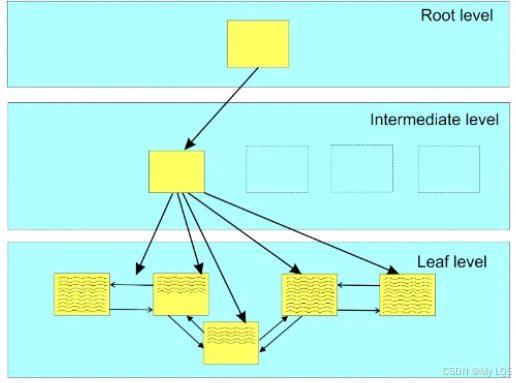
了解MySQL B+ 树
- MySQL 中的主键索引(特别是 InnoDB 存储引擎)使用 B+ 树作为数据结构。
- B+ 树是一种平衡树,数据节点之间按顺序排列,叶子节点形成一个链表,便于范围查询。
- 插入数据时,新数据需要根据键值找到其在 B+ 树中的合适位置,然后插入。
使用UUID-V4 产生的问题
在数据库设计中,主键(尤其是在 InnoDB 中)通常是聚簇索引的一部分,这意味着表中的数据是按照主键的顺序物理存储的。主键的顺序性对性能有直接影响,尤其是在频繁插入数据时。
1. 缺乏顺序性
UUID V4 是随机的,每次插入都会在 B+ 树的随机位置插入新的节点。与自增主键(顺序递增)不同,随机插入无法利用 B+ 树的局部性优势。
- 定位成本高:
- 随机插入时,数据库需要先在 B+ 树中找到合适的位置。这需要从根节点遍历到叶子节点,导致更多的索引页被频繁访问。
- 数据局部性丧失:
- 顺序插入时,数据和索引通常集中在最近的节点,能充分利用缓存和磁盘的预读功能。
- 随机插入时,数据可能分布在不同的节点上,导致更多的磁盘 I/O,无法利用缓存优势。
2. 频繁的树节点分裂
在使用 B+ 树作为索引结构时,频繁的树节点分裂会影响性能,尤其是在高频插入的场景中。为了理解这一问题,我们需要先了解 B+ 树的基本结构和分裂机制。
B+ 树的基本结构
- 节点结构:
- 内部节点:包含键值和指向子节点的指针。用于在树中导航,帮助定位数据。
- 叶子节点:存储实际的数据(或者指向数据的指针)。叶子节点之间通过链表连接,方便范围查询。
- 根节点:是 B+ 树的起始点,所有的查询操作都从根节点开始。
- 页的大小:
- 每个节点(内部节点或叶子节点)都有固定的大小(例如 16KB),这意味着每个节点可以存储一定数量的键值对或指针。
树节点的分裂
B+ 树在插入数据时,需要保证树的平衡性。当插入一个新元素时,首先要找到正确的叶子节点位置。假设该叶子节点有足够的空间来存放新数据,那么就直接插入到该节点中。如果该节点已满,必须进行节点分裂。
- 分裂过程:当一个节点(比如叶子节点)已满时,B+ 树会将该节点的一部分数据(一般是一半)移到一个新的节点中,并将新节点的最小键值(对于叶子节点来说是新的最小值)上升到父节点。如果父节点也满了,那么它同样会分裂,直到根节点可能也会分裂,这就导致了树的高度增长。
3. 脏页刷盘增加
-
脏页定义:
数据库将数据存储在数据页中,每个数据页是一定大小的磁盘块(如 MySQL InnoDB 默认 16KB)。当数据页被加载到内存缓冲池后,如果在内存中被修改,而还未同步写入磁盘,则这个数据页称为“脏页”。
-
脏页刷盘:
为了保持数据的持久性和一致性,数据库需要将脏页定期写回磁盘,这一过程被称为“脏页刷盘”。
-
脏页刷盘增加的性能影响:
-
磁盘 I/O 增加
脏页刷盘需要将内存中的数据写入磁盘,而磁盘写操作相对耗时,频繁的写入会导致磁盘 I/O 饱和。尤其是对于机械硬盘(HDD)或非优化的存储系统,性能下降更加显著。 -
数据库延迟增大
当脏页刷盘频繁时,写入操作会因等待磁盘写入完成而阻塞,导致事务响应时间增加。
-
如何升级UUID-V7
安装支持 UUID v7 的库,可以选择以下库之一:
uuid-creator:一个常用的 UUID 库,支持 UUID v7 和其他版本。java-uuid-generator:一个更强大的库,支持多种UUID 版本。
例如,在 Maven 中添加 uuid-creator 依赖:
<dependency>
<groupId>com.fasterxml.uuid</groupId>
<artifactId>java-uuid-generator</artifactId>
<version>4.0.1</version>
</dependency>
然后使用如下方式生成 UUID v7:
import com.fasterxml.uuid.Generators;
import com.fasterxml.uuid.impl.TimeBasedGenerator;
public class UUIDGeneration {
public static void main(String[] args) {
TimeBasedGenerator generator = Generators.timeBasedGenerator();
System.out.println(generator.generate());
}
}
总结
使用 UUID v7 代替 UUID v4 的主要原因是为了在高频数据插入场景中提升性能,同时保留全局唯一性和兼容性,并且增加了对数据的时间语义支持。

















 5847
5847

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









