









 本文整理了使用IDEA连接配置了Kerberos的HDFS集群时遇到的时钟偏差和RPC保护配置不一致的错误。通过调整Windows系统时间与集群时间同步,以及确保`hadoop.rpc.protection`配置与集群一致,成功解决问题。
本文整理了使用IDEA连接配置了Kerberos的HDFS集群时遇到的时钟偏差和RPC保护配置不一致的错误。通过调整Windows系统时间与集群时间同步,以及确保`hadoop.rpc.protection`配置与集群一致,成功解决问题。
连接hdfs代码
public class HdfsTest {
public static void main(String[] args) throws IOException {
System.setProperty("java.security.krb5.conf", "hdfs-conf-kerberos\\krb5.conf");
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://bigdata-37-201:8020");
conf.set("hadoop.security.authentication", "kerberos");
try {
UserGroupInformation.setConfiguration(conf);
UserGroupInformation.loginUserFromKeytab("hdfs_test1/hdfs_test1@HADOOP.COM", "hdfs-conf-kerberos\\hdfs_test1.keytab");
System.out.println("+++++++++++++="+UserGroupInformation.getCurrentUser());
} catch (IOException e) {
e.printStackTrace();
}
FileSystem fs = FileSystem.get(conf);
FileStatus[] fsStatus = fs.listStatus(new Path("/tmp"));
for (int i = 0; i < fsStatus.length; i++) {
System.out.println("+++++ "+fsStatus[i].getPath().toString());
}
}
}配置文件放置路径:
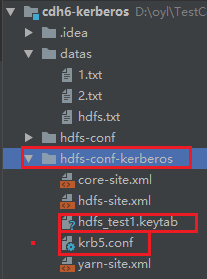
报错内容:
2021-02-18 15:33:50,189 INFO [org.apache.hadoop.security.UserGroupInformation] - Login successful for user hdfs_test1/hdfs_test1@HADOOP.COM using keytab file hdfs-conf-kerberos\hdfs_test1.keytab
+++++++++++++=hdfs_test1/hdfs_test1@HADOOP.COM (auth:KERBEROS)
2021-02-18 15:34:17,628 WARN [org.apache.hadoop.ipc.Client] - Couldn't setup connection for hdfs_test1/hdfs_test1@HADOOP.COM to bigdata-37-201/192.168.37.201:8020
javax.security.sasl.SaslException: GSS initiate failed [Caused by GSSException: No valid credentials provided (Mechanism level: Clock skew too great (37) - PROCESS_TGS)]
at com.sun.security.sasl.gsskerb.GssKrb5Client.evaluateChallenge(GssKrb5Client.java:211)
at org.apache.hadoop.security.SaslRpcClient.saslConnect(SaslRpcClient.java:408)
at org.apache.hadoop.ipc.Client$Connection.setupSaslConnection(Client.java:613)
at org.apache.hadoop.ipc.Client$Connection.access$2200(Client.java:409)
at org.apache.hadoop.ipc.Client$Connection$2.run(Client.java:798)
at org.apache.hadoop.ipc.Client$Connection$2.run(Client.java:794)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1962)
at org.apache.hadoop.ipc.Client$Connection.setupIOstreams(Client.java:794)
at org.apache.hadoop.ipc.Client$Connection.access$3500(Client.java:409)
at org.apache.hadoop.ipc.Client.getConnection(Client.java:1552)
at org.apache.hadoop.ipc.Client.call(Client.java:1383)
at org.apache.hadoop.ipc.Client.call(Client.java:1347)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:228)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:116)
at com.sun.proxy.$Proxy11.getListing(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.getListing(ClientNamenodeProtocolTranslatorPB.java:653)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:422)
at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeMethod(RetryInvocationHandler.java:165)
at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invoke(RetryInvocationHandler.java:157)
at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeOnce(RetryInvocationHandler.java:95)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:359)
at com.sun.proxy.$Proxy12.getListing(Unknown Source)
at org.apache.hadoop.hdfs.DFSClient.listPaths(DFSClient.java:1678)
at org.apache.hadoop.hdfs.DFSClient.listPaths(DFSClient.java:1662)
at org.apache.hadoop.hdfs.DistributedFileSystem.listStatusInternal(DistributedFileSystem.java:977)
at org.apache.hadoop.hdfs.DistributedFileSystem.access$1000(DistributedFileSystem.java:118)
at org.apache.hadoop.hdfs.DistributedFileSystem$24.doCall(DistributedFileSystem.java:1041)
at org.apache.hadoop.hdfs.DistributedFileSystem$24.doCall(DistributedFileSystem.java:1038)
at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)
at org.apache.hadoop.hdfs.DistributedFileSystem.listStatus(DistributedFileSystem.java:1048)
at com.hdfs.krb6.HdfsTest.main(HdfsTest.java:35)
Caused by: GSSException: No valid credentials provided (Mechanism level: Clock skew too great (37) - PROCESS_TGS)
at sun.security.jgss.krb5.Krb5Context.initSecContext(Krb5Context.java:770)
at sun.security.jgss.GSSContextImpl.initSecContext(GSSContextImpl.java:248)
at sun.security.jgss.GSSContextImpl.initSecContext(GSSContextImpl.java:179)
at com.sun.security.sasl.gsskerb.GssKrb5Client.evaluateChallenge(GssKrb5Client.java:192)
... 36 more
Caused by: KrbException: Clock skew too great (37) - PROCESS_TGS
at sun.security.krb5.KrbTgsRep.<init>(KrbTgsRep.java:73)
at sun.security.krb5.KrbTgsReq.getReply(KrbTgsReq.java:251)
at sun.security.krb5.KrbTgsReq.sendAndGetCreds(KrbTgsReq.java:262)
at sun.security.krb5.internal.CredentialsUtil.serviceCreds(CredentialsUtil.java:308)
at sun.security.krb5.internal.CredentialsUtil.acquireServiceCreds(CredentialsUtil.java:126)
at sun.security.krb5.Credentials.acquireServiceCreds(Credentials.java:458)
at sun.security.jgss.krb5.Krb5Context.initSecContext(Krb5Context.java:693)
... 39 more
Caused by: KrbException: Identifier doesn't match expected value (906)
at sun.security.krb5.internal.KDCRep.init(KDCRep.java:140)
at sun.security.krb5.internal.TGSRep.init(TGSRep.java:65)
at sun.security.krb5.internal.TGSRep.<init>(TGSRep.java:60)
at sun.security.krb5.KrbTgsRep.<init>(KrbTgsRep.java:55)
... 45 more
Exception in thread "main" java.io.IOException: Failed on local exception: java.io.IOException: Couldn't setup connection for hdfs_test1/hdfs_test1@HADOOP.COM to bigdata-37-201/192.168.37.201:8020; Host Details : local host is: "WB20200528/172.16.137.39"; destination host is: "bigdata-37-201":8020;
at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:808)
at org.apache.hadoop.ipc.Client.getRpcResponse(Client.java:1495)
at org.apache.hadoop.ipc.Client.call(Client.java:1437)
at org.apache.hadoop.ipc.Client.call(Client.java:1347)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:228)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:116)
at com.sun.proxy.$Proxy11.getListing(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.getListing(ClientNamenodeProtocolTranslatorPB.java:653)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)错误日志分析一
2021-02-18 15:34:17,628 WARN [org.apache.hadoop.ipc.Client] - Couldn't setup connection for hdfs_test1/hdfs_test1@HADOOP.COM to bigdata-37-201/192.168.37.201:8020
javax.security.sasl.SaslException: GSS initiate failed [Caused by GSSException: No valid credentials provided (Mechanism level: Clock skew too great (37) - PROCESS_TGS)]
Clock skew too great 时钟偏差太大
查找一下windows的时间和集群的时间,发现还真的相差半小时,修改windows的时间和集群时间同步再次执行上面代码
显示结果和在shell下查询相同
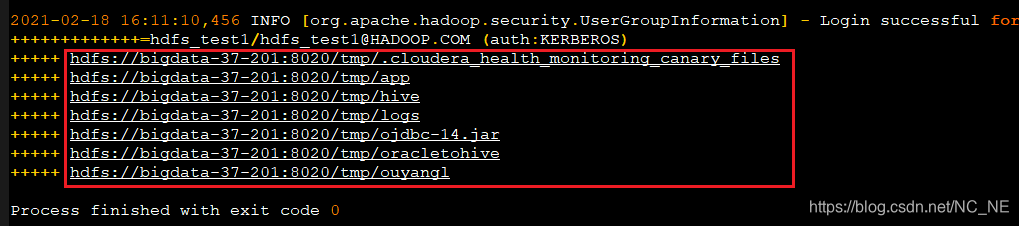
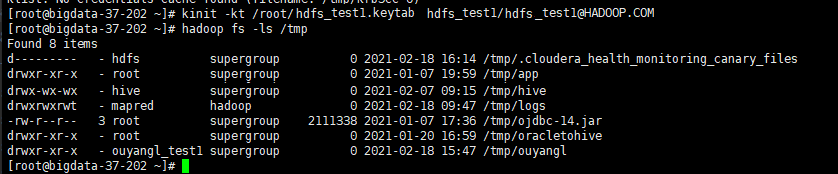
错误日志分析二
Exception in thread "main" java.io.IOException: Failed on local exception: java.io.IOException: Couldn't setup connection for hdfs_test1/hdfs_test1@HADOOP.COM to bigdata-37-201/192.168.37.201:8020; Host Details : local host is: "WB20200528/172.16.137.39"; destination host is: "bigdata-37-201":8020;注意: hadoop.rpc.protection必须与集群的配置保持一致(core-site.xml)
conf.set("hadoop.rpc.protection", "authentication");
//conf.set("hadoop.rpc.protection", "privacy");参考链接:https://blog.csdn.net/zhouyuanlinli/article/details/78581510

















 1558
1558

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









