




 本文详细介绍了HDFS的组成架构,包括NameNode、DataNode和Client的角色与职责。阐述了HDFS的写数据和读数据流程,以及NameNode的工作机制,包括Fsimage和Edits的解析。此外,还讨论了DataNode的运作方式和掉线时限参数。
本文详细介绍了HDFS的组成架构,包括NameNode、DataNode和Client的角色与职责。阐述了HDFS的写数据和读数据流程,以及NameNode的工作机制,包括Fsimage和Edits的解析。此外,还讨论了DataNode的运作方式和掉线时限参数。
一、HDFS 组成架构

1)NameNode(nn):就是Master,它是一个主管、管理者。
(1)管理HDFS的名称空间
(2)配置副本策略
(3)管理数据块(Block)映射信息
(4)处理客户端读写请求。
2)DataNode:就是Slave。NameNode下达命令,DataNode执行实际的操作。
(1)存储实际的数据块
(2)执行数据块的读/写操作。
3)Client:就是客户端。
(1)文件切分。文件上传HDFS的时候,Client将文件切分成一个一个的Block,然后进行上传
(2)与NameNode交互,获取文件的位置信息
(3)与DataNode交互,读取或者写入数据
(4)Client提供一些命令来管理HDFS,比如NameNode格式化
(5)Client可以通过一些命令来访问HDFS,比如对HDFS增删查改操作
4)Secondary NameNode:并非NameNode的热备。当NameNode挂掉的时候,它并不能马上替换NameNode并提供服务(一般只在测试环境存在,生产环境都是搭建NN高可用的)。
(1)辅助NameNode,分担其工作量,比如定期合并Fsimage和Edits,并推送给NameNode
(2)在紧急情况下,可辅助恢复NameNode。
二、HDFS的写数据流程

(1)客户端通过 Distributed FileSystem 模块向 NameNode 请求上传文件,NameNode 检查目标文件是否已存在,父目录是否存在
(2)NameNode 返回是否可以上传
(3)客户端请求第一个 Block 上传到哪几个 DataNode 服务器上
(4)NameNode 根据副本存储节点选择规则(本地节点,其他机架一个节点,其他机架另一个节点)返回 3 个 DataNode 节点,分别为 dn1、dn2、dn3
(5)客户端通过 FSDataOutputStream 模块请求 dn1 上传数据,dn1 收到请求会继续调用dn2,然后 dn2 调用 dn3,将这个通信管道建立完成
(6)dn1、dn2、dn3 逐级应答客户端
(7)客户端开始往 dn1 上传第一个 Block(先从磁盘读取数据放到一个本地内存缓存),以 Packet 为单位,dn1 收到一个 Packet 就会传给 dn2,dn2 传给 dn3;dn1 每传一个 packet会放入一个应答队列等待应答
(8)当一个 Block 传输完成之后,客户端再次请求 NameNode 上传第二个 Block 的服务器。(重复执行 3-7 步)
三、HDFS 读数据流程
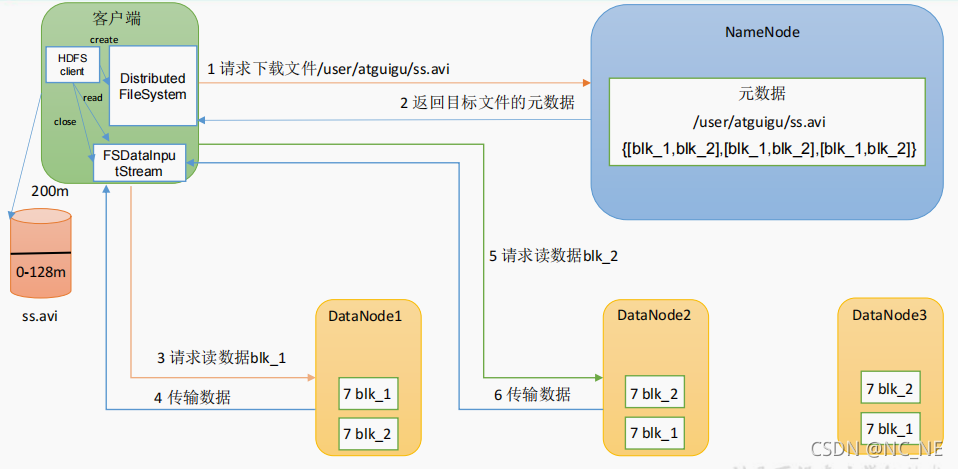
1)客户端通过 DistributedFileSystem 向 NameNode 请求下载文件,NameNode 通过查询元数据,找到文件块所在的 DataNode 地址
(2)挑选一台 DataNode(就近原则,然后随机)服务器,请求读取数据
(3)DataNode 开始传输数据给客户端(从磁盘里面读取数据输入流,以 Packet 为单位来做校验)
(4)客户端以 Packet 为单位接收,先在本地缓存,然后写入目标文件
四、NameNode工作机制
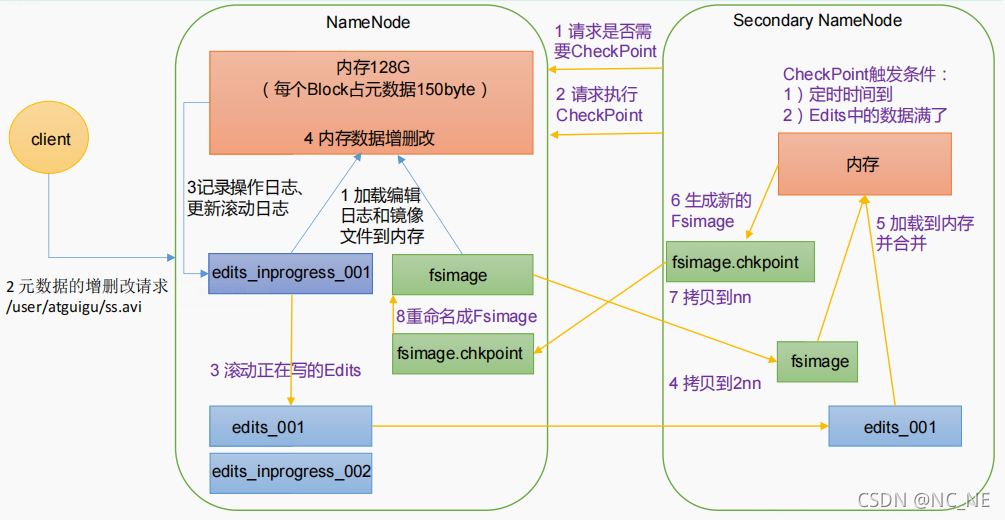
1)第一阶段:NameNode 启动
(1)第一次启动 NameNode 格式化后,创建 Fsimage 和 Edits 文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
(2)客户端对元数据进行增删改的请求
(3)NameNode 记录操作日志,更新滚动日志
(4)NameNode 在内存中对元数据进行增删改。
2)第二阶段:Secondary NameNode 工作(如果是NN的HA模式,这个时候就是Standby的NN来处理第二阶段,此时的Edits 文件就在journalNode里面保存)
(1)Secondary NameNode 询问 NameNode 是否需要 CheckPoint。直接带回 NameNode是否检查结果。
(2)Secondary NameNode 请求执行 CheckPoint
(3)NameNode 滚动正在写的 Edits 日志
(4)将滚动前的编辑日志和镜像文件拷贝到 Secondary NameNode
(5)Secondary NameNode 加载编辑日志和镜像文件到内存,并合并。
(6)生成新的镜像文件 fsimage.chkpoint
(7)拷贝 fsimage.chkpoint 到 NameNode
(8)NameNode 将 fsimage.chkpoint 重新命名成 fsimage。
五、Fsimage 和 Edits 解析
(1)Fsimage文件:HDFS文件系统元数据的一个永久性的检查点,其中包含HDFS文件系统的所有目录和文件inode的序列化信息
(2)Edits文件:存放HDFS文件系统的所有更新操作的路径,文件系统客户端执行的所有写操作首先会被记录到Edits文件中
(3)每 次NameNode启动的时候都会将Fsimage文件读入内存,加 载Edits里面的更新操作,保证内存中的元数据信息是最新的、同步的,可以看成NameNode启动的时候就将Fsimage和Edits文件进行了合并。
六、DataNode 工作机制
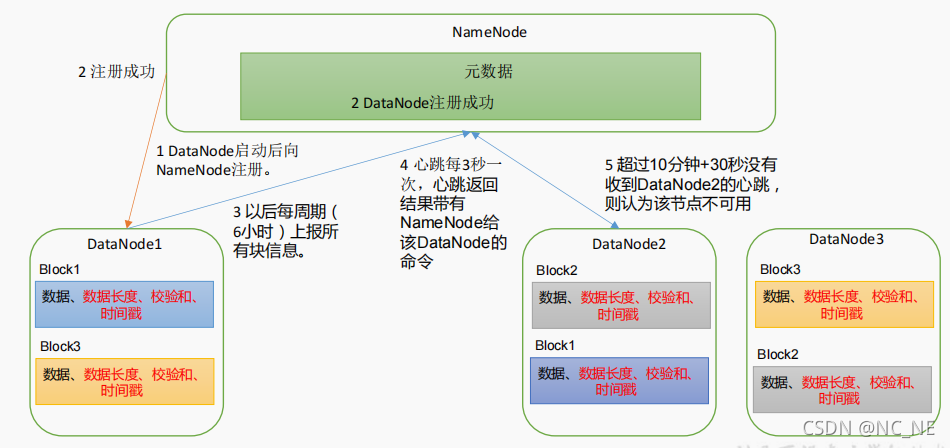
(1)一个数据块在 DataNode 上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳
(2)DataNode 启动后向 NameNode 注册,通过后,周期性(6 小时)的向 NameNode 上报所有的块信息(时间可以配置)。
(3)心跳是每 3 秒一次,心跳返回结果带有 NameNode 给该 DataNode 的命令如复制块数据到另一台机器,或删除某个数据块。如果超过 10 分钟+30秒没有收到某个 DataNode 的心跳,则认为该节点不可用。
(4)集群运行中可以安全加入和退出一些机器。
七、DataNode掉线时限参数
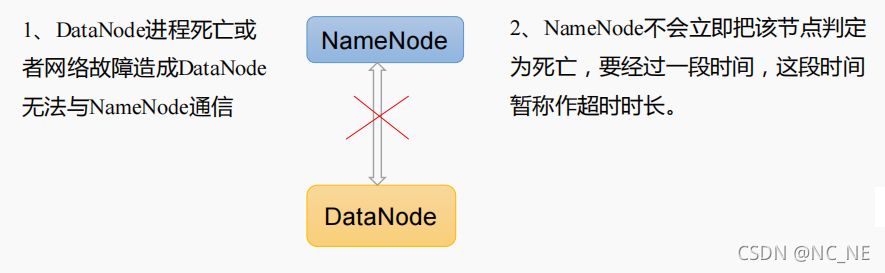
<property>
<name>dfs.namenode.heartbeat.recheck-interval</name>
<value>300000</value>
</property>
<property>
<name>dfs.heartbeat.interval</name>
<value>3</value>
</property>
1)默认的dfs.namenode.heartbeat.recheck-interval 大小为5分钟
HeartbeatManager中有一个线程,默认每5分钟会检查一次所有的datanodes,判断每个datanode是否已经死亡
(2)dfs.heartbeat.interval默认为3秒
(3)HDFS默认的超时时长为10分钟+30秒
TimeOut = 2 * dfs.namenode.heartbeat.recheck-interval + 10 * dfs.heartbeat.interval

















 3642
3642

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









