







puppeteer是chrome官方出品的无界面浏览器,我们一般称为无头浏览器。
这种浏览器具有普通版浏览器的完备功能,并且可以运行在无界面的服务端,比如远程的linux服务器上,是做ui自动化测试的一个不错的选择。
我们今天就来看一下puppeteer的生态,看看除了自动化测试这个工具还能做什么吧。
Puppetron
https://github.com/cheeaun/puppetron,这个项目的功能非常简单,就是使用puppeteer来渲染页面并且进行截图或者是将页面保存成pdf文件。
你可以通过api调用来完成上述的3个功能,渲染/截图以及保存pdf都支持宽高设置,所以你可以很容易的实现模拟不同大小屏幕的功能。
比如你可以通过设置不同的宽高来得到某个网站在小屏手机/大屏手机/平板以及电脑上的屏幕截图。
pupperender
https://github.com/LasaleFamine/pupperender,pupperender是一个express中间件,它的功能是如果探测到这次页面的访问是来自搜索引擎的机器人或者是爬虫,那么就自动使用puppeteer来渲染页面,返回完整的html。
该工具就解决了一些前后端分离的站点对搜索引擎不友好的问题,因为如果是纯js实现的前端页面,那么搜索机器人爬到的页面仅仅包含一些基本的html,页面的具体内容是没办法正确渲染出来并返回的。
该库的使用也非常的简单,几行代码就可以搞定了。
const express = require('express');
const pupperender = require('pupperender');
const app = express();
app.use(pupperender.makeMiddleware({}));
app.use(express.static('files'));
app.listen(8080);有困惑的同学可以搜索PWA进行更深入的学习。
headless-chrome-crawler
https://github.com/yujiosaka/headless-chrome-crawler,是使用puppeteer实现的爬虫。
它的一些功能还是非常有特色的,比如:
- 支持分布式爬取
- 实现了深度优先和广度优先算法
- 支持csv和json line格式导出
- 插件式的结果存储,比如支持redis
- 自动插入jquery,可以使用jquery语法进行结果处理
- 支持截图作为爬取证据
- 支持模拟不同的设备
简单看一个例子:
const HCCrawler = require('headless-chrome-crawler');
(async () => {
const crawler = await HCCrawler.launch({
// Function to be evaluated in browsers
evaluatePage: (() => ({
title: $('title').text(),
})),
// Function to be called with evaluated results from browsers
onSuccess: (result => {
console.log(result);
}),
});
// Queue a request
await crawler.queue('https://example.com/');
// Queue multiple requests
await crawler.queue(['https://example.net/', 'https://example.org/']);
// Queue a request with custom options
await crawler.queue({
url: 'https://example.com/',
// Emulate a tablet device
device: 'Nexus 7',
// Enable screenshot by passing options
screenshot: {
path: './tmp/example-com.png'
},
});
await crawler.onIdle(); // Resolved when no queue is left
await crawler.close(); // Close the crawler
})();上面的例子就演示了使用jquery语法title: $('title').text() 获取页面信息以及模拟特定的设备Nexus 7进行爬取以及截图的功能。
browserless
https://github.com/browserless/chrome。browserless是一个云服务,它允许远程客户端连接并控制在服务器上的无界面浏览器,而这一切都是跑在docker里的。
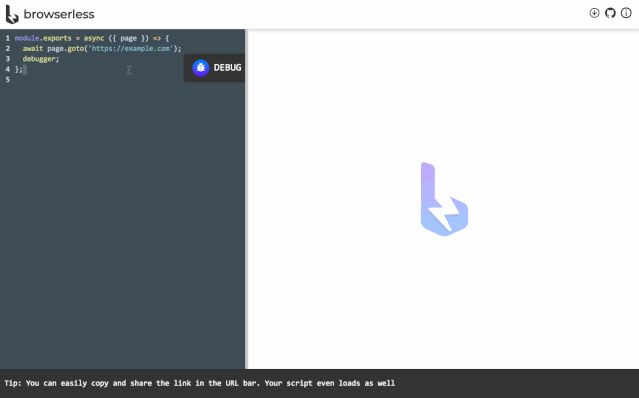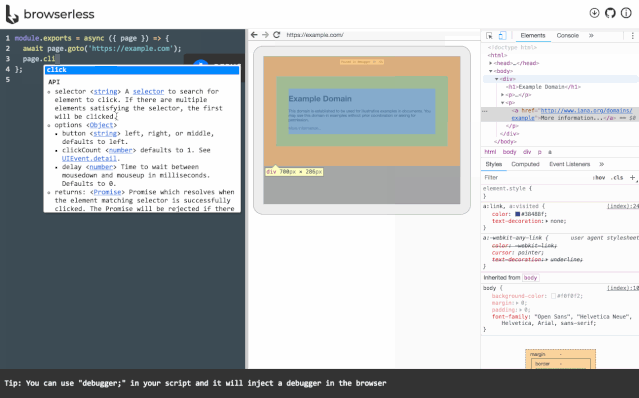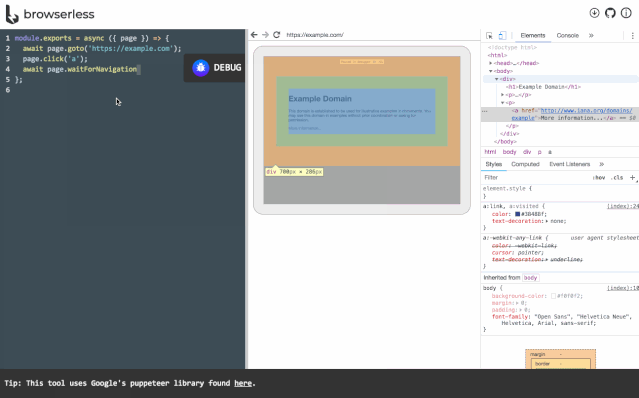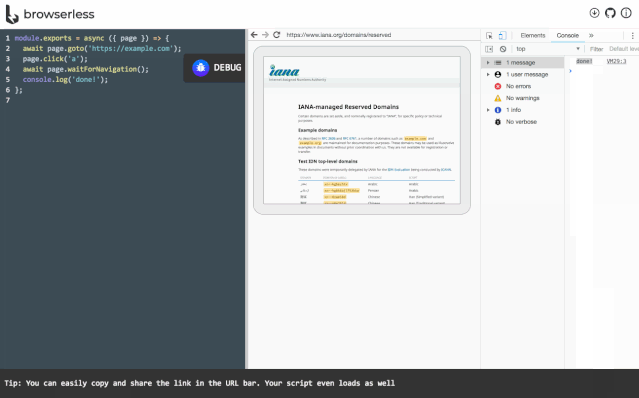
你可以使用browserless在自己公司内部搭建这样一套服务,这样就可以实现自己的headless浏览器私有云服务,组织内的任何成员都可以通过脚本去使用浏览器,统一了自动化执行环境并且优化了资源利用率。
browserless的原理如下,有兴趣的同学可以仔细研究一下。
browserless listens for both incoming websocket requests, generally issued by most libraries, as well as pre-build REST APIs to do common functions (PDF generation, images and so on). When a websocket connects to browserless it invokes Chrome and proxies your request into it. Once the session is done then it closes and awaits for more connections. Some libraries use Chrome's HTTP endpoints, like /json to inspect debug-able targets, which browserless also supports.
Your application still runs the script itself (much like a database interaction), which gives you total control over what library you want to choose and when to do upgrades. This is preferable over other solutions as Chrome is still breaking their debugging protocol quite frequently.
puppeteersandbox
https://puppeteersandbox.com,这个站点可以是一个puppeteer的沙盒环境,可以很方便的嵌入到其他的站点或者是markdown文件里。
不过不知道是不是因为网络的原因,这个站点似乎从来就没工作过,好吧,希望早日恢复健康。
jest-puppeteer
https://github.com/smooth-code/jest-puppeteer,是一个几乎只需要零配置的基于puppeteer和jest的ui自动化测试框架。
稍微看一下用例的写法,相信你很快就可以明白这个框架的用处了。
import 'expect-puppeteer'
describe('Google', () => {
beforeAll(async () => {
await page.goto('https://google.com')
})
it('should display "google" text on page', async () => {
await expect(page).toMatch('google')
})
})
// Assert that current page contains 'Text in the page'
await expect(page).toMatch('Text in the page')
// Assert that a button containing text "Home" will be clicked
await expect(page).toClick('button', { text: 'Home' })
// Assert that a form will be filled
await expect(page).toFillForm('form[name="myForm"]', {
firstName: 'James',
lastName: 'Bond',
})可以很方便的断言页面的文字包含,点击以及表单的填写,加上jest灵活的定制能力,该框架的灵活性是值得期待的。
Puppetry
https://puppetry.app 是一款完成度很高的用例录制及执行回放工具,当然了,基于puppeteer。
puppetry开源,跨平台,核心特性很多,这里就不一一列举了。有兴趣的同学可以看一下项目的github主页。
需要重点说明的是,Puppetry官方表示支持的测试场景有下面这么多:
- 功能测试
- 测试动态内容
- 详细测试
- 性能测试
- 可视化的回归测试
- mock api的能力
- 测试rest api
- 测试google analytics代码
- 测试chrome扩展
- 测试shadow dom
- 测试邮件
总结
总的来说,开发者对于puppeteer的热情还是很高的,而且puppeteer的更新频率很快,整体生态环境是健康和谐的。
对于大多数同学来说,只需要简单的理解,puppeteer可以实现
- 爬虫的能力
- ui自动化测试的能力
最后感谢每一个认真阅读我文章的人,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:
这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!
















 249
249

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









