







 本文讲述了作者使用Python爬取大众点评成都火锅类目50页的数据,分析了评论数量、星级、人均消费与商家热度之间的关系,并通过词云图展示了热门菜品。结果发现评论数与星级在四星以上商户中无明显关系,而口味、环境、服务得分高的店铺更受欢迎。此外,还进行了K-means聚类,进一步筛选出推荐的火锅店铺。
本文讲述了作者使用Python爬取大众点评成都火锅类目50页的数据,分析了评论数量、星级、人均消费与商家热度之间的关系,并通过词云图展示了热门菜品。结果发现评论数与星级在四星以上商户中无明显关系,而口味、环境、服务得分高的店铺更受欢迎。此外,还进行了K-means聚类,进一步筛选出推荐的火锅店铺。
文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
爬虫
首先笔者定位为成都,美食类型选的“火锅”,火锅具体类型选的不限,区域选的不限,排序选的智能,如图:
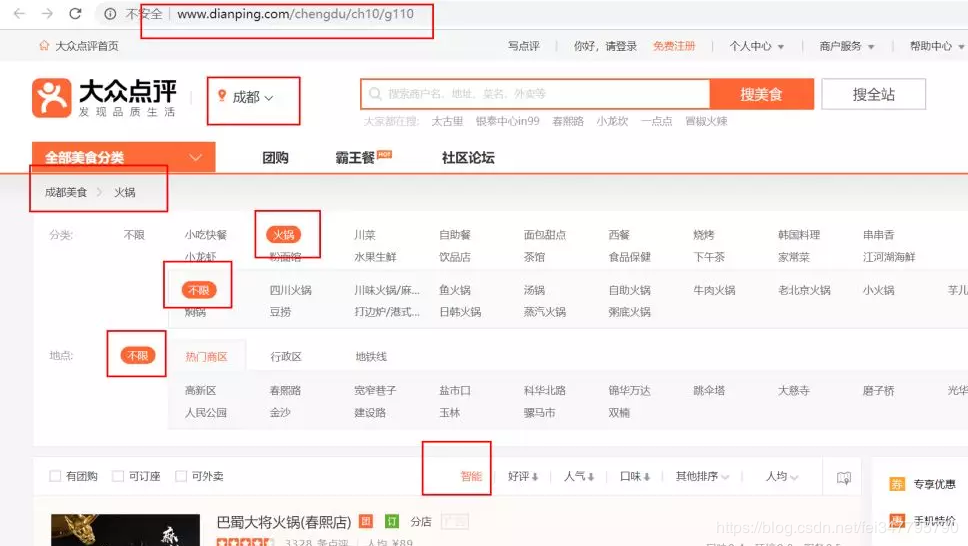
你也可以选择别的选项,只是注意URL的变化。本文都是按照上述选项爬取的数据。接下来翻页观察一下URL的变化:
第二页:

第三页:

很容易观察出翻页变化的知识p后面的数字,倒推回第一页,发现一样的显示内容,因此,写一个循环,便可以爬取全部页面。
但是大众点评只提供了前50页的数据,所以,我们也只能爬取前50页。
这一次,笔者用的pyquery来分析网页的,所以我们需要定位到我们所爬取的数据的位置,如图:
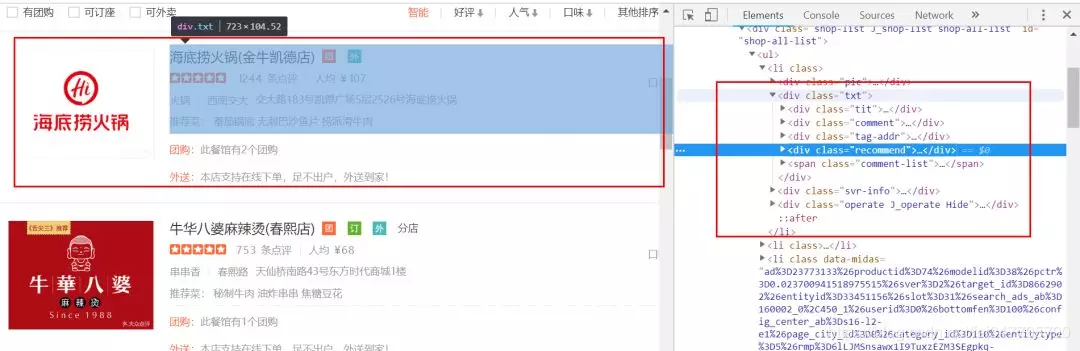
在具体分析的网页的时候,我震惊了,大众点评的反爬做的太过分了,它的数字,一些文字居然都不是明文显示,而是代码,你还不知道怎么分析它。如图:
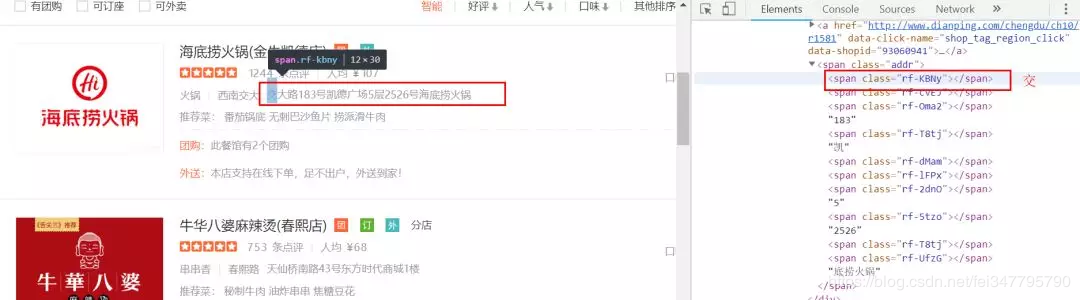
很烦的,一些文字又可以显示,一些又用代码表示。一些数字也是,不过好一点的是数字只有9个,只要稍微观察一下,就能发现数字的代码是什么了。这里笔者列出来了。 {‘hs-OEEp’: 0, ‘hs-4Enz’: 2, ‘hs-GOYR’: 3, ‘hs-61V1’: 4, ‘hs-SzzZ’: 5, ‘hs-VYVW’: 6, ‘hs-tQlR’: 7, ‘hs-LNui’: 8, ‘hs-42CK’: 9}。值得注意的是,数字1,是用明文表示的。
那么,如何用pyquery来定位呢,很简单,你找到你要获取的数据,然后右键→copy→cut selector,你复制到代码里面就OK了。pyquery的具体用法百度既有。
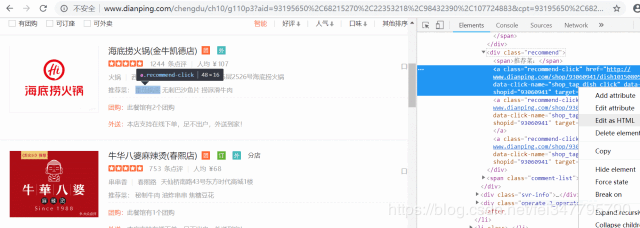
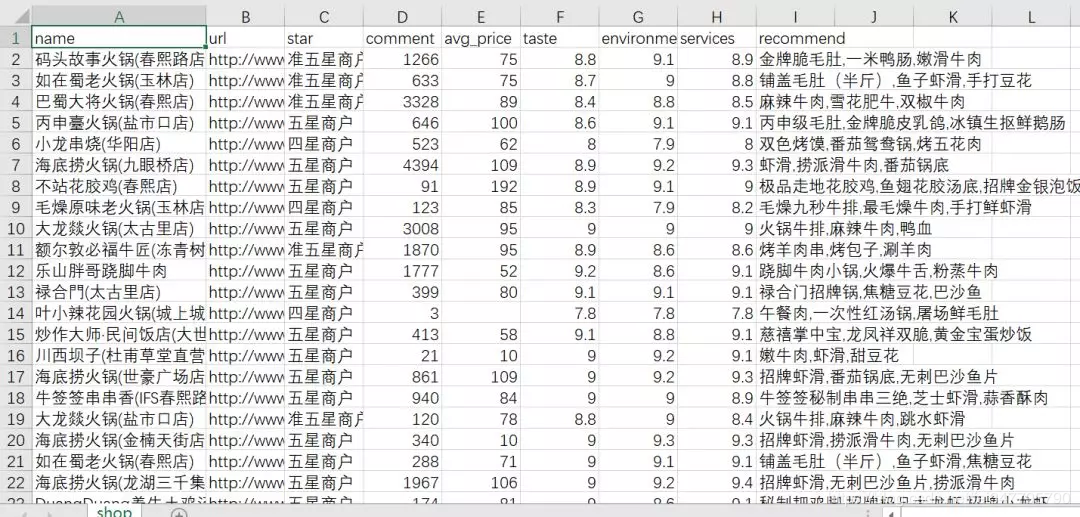
最后,我们获取了火锅50个页面的数据,每页15个数据,一共750家餐厅的数据。
分析
大众点评已经给出了星级评价,可以看看大致趋势。
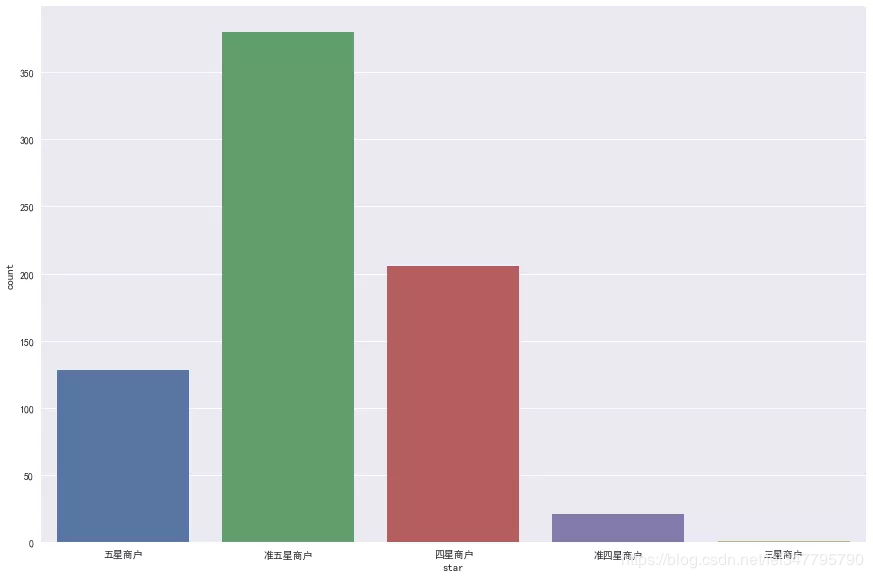
准五星商户最多,可
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









