







1. 目标
目标:https://hr.tencent.com/position.php?&start=0#a
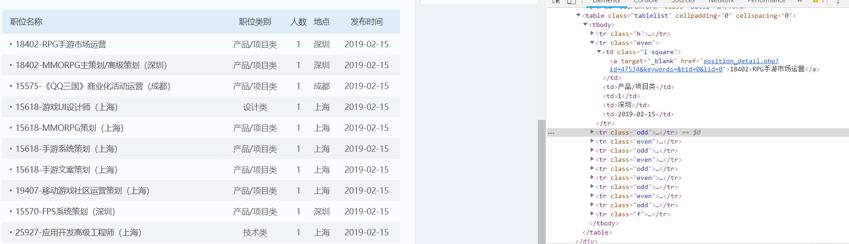
爬取所有的职位信息信息
- 职位名
- 职位url
- 职位类型
- 职位人数
- 工作地点
- 发布时间
2. 网站结构分析
3. 编写爬虫程序
3.1. 配置需要爬取的目标变量
对于新手小白想更轻松的学好Python基础,Python爬虫,web开发、大数据,数据分析,人工智能等技术,这里给大家分享系统教学资源,加下我V:itz992 【教程/工具/方法/解疑】
class TecentjobItem(scrapy.Item):
# define the fields for your item here like:
positionname = scrapy.Field()
positionlink = scrapy.Field()
positionType = scrapy.Field()
peopleNum = scrapy.Field()
workLocation = scrapy.Field()
publishTime = scrapy.Field()
3.2. 写爬虫文件scrapy
# -*- coding: utf-8 -*-
import scrapy
from tecentJob.items import Tecent 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









